빅데이터, 새로운 유형을 넘어 새로운 패러다임
초록
본 논문은 지리정보가 포함된 빅데이터(예: 트위터 위치 데이터)와 전통적인 소규모 데이터(예: 인구 조사)를 데이터 특성, 공간·통계 분석 관점에서 비교한다. 빅데이터는 규모·속도·다양성에서 기존 데이터와 근본적으로 차별화되며, 이를 처리하기 위한 기하학적·통계적 방법론도 새롭게 정의되어야 함을 주장한다.
상세 분석
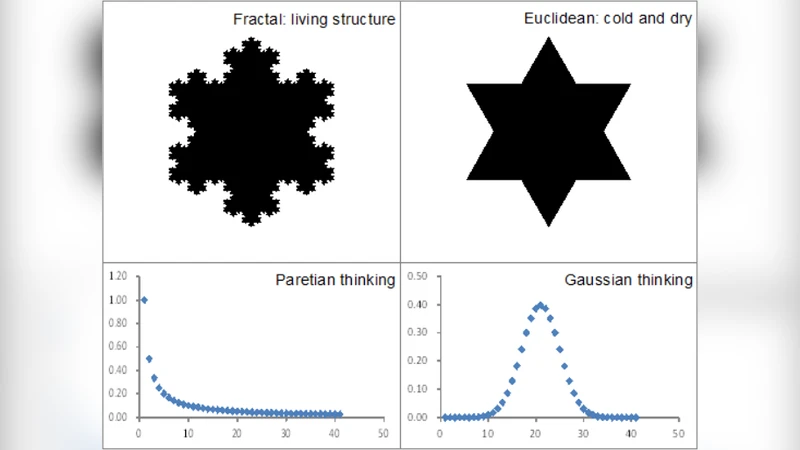
본 논문은 빅데이터와 소규모 데이터의 차이를 ‘데이터 특성’과 ‘분석 패러다임’ 두 축으로 체계화한다. 첫 번째 축인 데이터 특성에서는 전통적인 3V(Volume, Velocity, Variety) 외에 ‘Veracity(진실성)’와 ‘Granularity(세분성)’를 강조한다. 트위터와 같은 지리적 빅데이터는 수십억 건의 위치 레코드를 실시간으로 생성하며, 공간 해상도는 개별 GPS 좌표 수준으로 매우 미세하다. 반면 인구 조사 데이터는 수천~수만 가구를 대표하는 집계값으로, 시간적 업데이트 주기가 수년 단위이며, 공간 단위는 행정구역(시·군·구) 수준에 머문다. 이러한 차이는 데이터의 샘플링 방식에서도 드러난다. 빅데이터는 ‘자발적 참여(volunteered)’ 형태로 비대표성(bias)과 불균형(uneven distribution)을 내포하지만, 대용량이라는 특성 덕분에 ‘희소 현상(sparse events)’까지 포착한다.
두 번째 축인 분석 패러다임에서는 기하학적 접근과 통계적 접근이 각각 어떻게 전환되는지를 논한다. 기하학적으로 소규모 데이터는 주로 ‘폴리곤 기반(행정구역)’ 분석에 의존해 평균값·밀도 등을 산출한다. 빅데이터는 ‘점 구름(point cloud)’ 형태로 존재하며, 밀도 기반 커널 추정, 클러스터링, 흐름 분석 등 미세한 공간 패턴을 직접 탐색할 수 있다. 통계적으로는 전통적인 정규분포 가정과 표본 평균 중심의 추론이 통용되지만, 빅데이터는 ‘헤비테일(heavy‑tail)’·‘파워‑로우(power‑law)’ 분포가 지배적이며, 중앙극값이 아닌 극단값이 분석의 핵심이 된다. 따라서 베이지안 네트워크, 베이지안 비층화 모델, 딥러닝 기반 공간‑시계열 예측 등 새로운 방법론이 요구된다.
또한 논문은 빅데이터 분석이 ‘설명적(explanatory)’에서 ‘예측적(predictive)’으로 전환되는 흐름을 강조한다. 트위터 위치 데이터는 실시간 사건 감지와 급변하는 도시 현상의 조기 경보에 활용될 수 있으며, 이는 기존 인구 조사 기반 정책 설계와는 근본적인 차이를 만든다. 마지막으로, 데이터 프라이버시와 품질 관리, 계산 인프라(클라우드·분산 처리) 등 실용적 과제도 함께 제시한다. 이러한 통합적 논의는 빅데이터가 단순히 ‘새로운 유형’이 아니라, 지리정보 과학 전반에 새로운 패러다임을 제시한다는 결론으로 귀결된다.
댓글 및 학술 토론
Loading comments...
의견 남기기