오디오 비주얼 동기화를 위한 강화된 교차모달 임베딩
본 논문은 오디오와 비디오 간의 동기화 문제를 교차모달 검색으로 정의하고, 기존의 이진 매칭 손실 대신 다중 후보 매칭을 이용한 교차엔트로피 손실로 임베딩을 학습하는 새로운 전략을 제안한다. 제안 방법은 동일한 입력에 대해 여러 오디오 후보 중 정답을 선택하도록 학습함으로써 더 풍부한 컨텍스트 정보를 활용한다. LRS2 데이터셋을 이용한 실험에서 5프레임(0.2 초)만 사용했을 때도 동기화 정확도가 75.8 %에서 89.5 %로 크게 향상되었으…
저자: Soo-Whan Chung, Joon Son Chung, Hong-Goo Kang
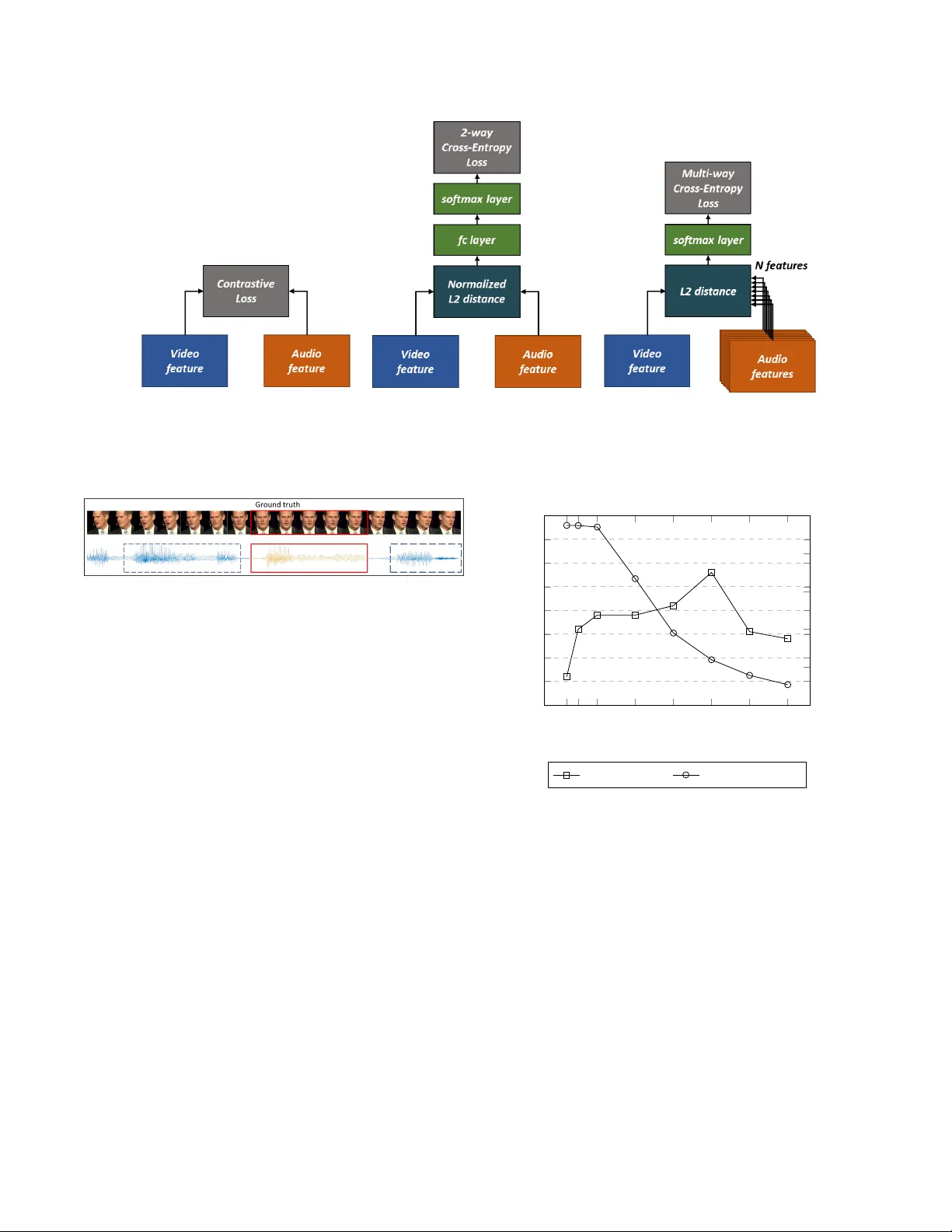
본 논문은 오디오와 비디오 간의 동기화 문제를 교차모달 검색 문제로 재정의하고, 기존의 이진 매칭 손실이 갖는 한계를 극복하기 위해 다중‑웨이 매칭 전략을 제안한다. 기존 연구들, 특히 SyncNet과 AVE‑Net은 오디오‑비디오 쌍이 일치하는지 여부를 이진 분류 혹은 대비 손실로 학습했으며, 이는 샘플 간의 전역적인 상대 관계를 활용하지 못하고, 학습 과정에서 “정답이 아닌” 샘플이 무작위로 선택돼 실제 내용 기반 특징을 충분히 학습하지 못한다는 문제점이 있었다.
제안된 방법은 하나의 비디오 클립에 대해 N개의 오디오 클립을 동시에 입력하고, 각각의 오디오와 비디오 임베딩 사이의 유클리드 거리를 계산한다. 거리의 역수를 소프트맥스에 통과시켜 정답 오디오에 대한 확률을 높이는 교차엔트로피 손실을 적용함으로써, 정답과 비정답 사이의 상대적 차이를 명시적으로 학습한다. 이때 비정답 오디오들은 동일한 얼굴 트랙 내에서 시간적으로 다른 구간을 사용해 “무슨 말을 하는가”에 초점을 맞추도록 설계되었다.
아키텍처는 기존 SyncNet과 동일한 VGG‑M 기반 두 스트림을 사용한다. 오디오 스트림은 13 차원의 MFCC 20프레임(10 ms 간격, 25 ms 프레임) 입력이며, 비디오 스트림은 224×224 크기의 얼굴 영상을 5프레임(0.2 초) 스택 형태로 처리한다. 첫 레이어의 필터 크기를 각각 (5×7×7)과 (13×5)로 조정해 시간적 정보를 포착한다. 이러한 설계는 기존 모델과 직접 비교할 수 있게 해준다.
학습은 LRS2(Lip Reading Sentences 2) 데이터셋의 사전학습 셋(96,318 클립)에서 수행되었다. 후보 오디오 수 N을 10~60 사이에서 실험했으며, N = 40이 가장 높은 정확도를 보였다. 평가 프로토콜은 ±15프레임(0.6 초) 범위 내에서 정답 오디오를 찾는 것이며, 예측이 1프레임 이내이면 정답으로 간주한다. 무작위 추측 시 9.7 % 정확도가 기대되지만, 제안 모델은 5프레임(단일 컨텍스트)만 사용했을 때 89.5 %의 정확도를 달성했다. 비디오 프레임 수(K)를 5→15까지 늘리면 정확도는 96.1 %→98.1 %로 상승한다. 이는 컨텍스트 윈도우를 확장함으로써 비디오 내 비언어 구간을 보완할 수 있음을 보여준다.
시각 음성 인식(visual speech recognition) 실험에서는 학습된 시각 임베딩을 고정하고, 2‑layer Temporal Convolution + 500‑way Softmax 구조(TC‑5)를 적용했다. 동일한 구조를 완전 감독 방식(E2E)으로 학습했을 때 71.5 %의 단어 정확도를 보였으며, 사전학습된 임베딩만 사용한 경우 71.6 %를 달성해 거의 동일한 성능을 보여준다. 이는 교차모달 자기지도 학습이 시각적 특징을 충분히 풍부하게 만든다는 증거이다.
결론적으로, 논문은 (1) 다중‑웨이 매칭을 통한 교차엔트로피 손실 적용이라는 새로운 학습 패러다임을 제시하고, (2) 동일한 네트워크 구조에서 기존 대비 크게 향상된 동기화 성능을 입증했으며, (3) 학습된 임베딩이 다른 다운스트림 태스크(시각 음성 인식)에서도 완전 감독 방식과 동등한 성능을 보임을 실증했다. 이러한 접근은 오디오‑비주얼 동기화뿐 아니라, 사운드 소스 로컬라이제이션, 멀티모달 검색 등 다양한 교차모달 응용 분야에 확장 가능할 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기