생성 모델로 구현하는 다양하고 자연스러운 억양 합성
본 논문은 변분 자동인코더(VAE)를 활용해 텍스트‑투‑스피치(TTS) 시스템에서 평균 억양이 아닌 다양한 억양을 생성하는 방법을 제안한다. 평균 억양을 피하기 위해 VAE의 가우시안 사전분포의 꼬리 영역을 샘플링함으로써 자연스러움을 크게 손상시키지 않으면서도 억양 변동성을 크게 증가시킨다. 실험 결과, 제안된 VAE‑TAIL 모델은 기존 RNN, MDN 등 전통적인 SPSS 모델보다 억양 변이도가 높으며, 자연스러움 점수는 기존 모델과 통계적…
저자: Zack Hodari, Oliver Watts, Simon King
**1. 서론**
텍스트‑투‑스피치(TTS) 시스템은 일반적으로 하나의 가장 가능성 높은 음성 렌더링을 생성한다. 인간 화자는 동일 문장에 대해 상황·감정·개인적 특성에 따라 다양한 억양을 구사하지만, 기존 신경 TTS는 평균 제곱오차(MSE) 최소화로 평균 억양을 학습해 평탄하고 지루한 결과를 낳는다. 이러한 ‘average prosody’를 극복하고자 연구자는 명시적 외부 제어 대신, 데이터 자체가 내포한 억양 변동성을 모델링하는 생성적 접근을 제안한다.
**2. 관련 연구**
프로소디 제어 방법은 크게 라벨링 기반 제어와 잠재 제어로 나뉜다. 라벨링은 비용이 많이 들고, 감정·스타일 라벨링은 주관적·불명확한 경우가 많다. 반면, 변분 자동인코더(VAE), VQ‑VAE, 글로벌 스타일 토큰(GST) 등은 비지도 학습으로 잠재 변수를 학습한다. 기존 VAE 기반 연구는 주로 음소·음성 스타일 전이 등에 초점을 맞췄으며, 억양 변동성을 직접적으로 활용한 TTS는 드물다.
**3. 평균 억양 문제**
전통적인 SPSS는 MSE를 최소화함으로써 데이터 평균을 학습하고, 이는 억양을 포함한 여러 음향 특성의 ‘oversmoothing’으로 이어진다. 프레임 수준의 혼합밀도 네트워크(MDN)는 단일 프레임에서 다중 모드를 모델링할 수 있지만, 억양과 같이 시간에 따라 연속적인 변화를 포착하기엔 한계가 있다. 따라서 저자는 잠재공간에서 장기적인 변동성을 모델링할 수 있는 VAE를 선택한다.
**4. 변분 자동인코더 설계**
문장 수준의 인코더가 입력 음성(로그 F0, 속도·가속도)과 언어학적 특징을 받아 가우시안 사후분포 q(z|x)를 추정한다. 사전분포는 평균 0, 분산 1인 단일 가우시안이며, KL‑annealing을 통해 posterior collapse를 방지한다. 디코더는 잠재벡터 z와 동일한 언어학적 특징을 받아 로그 F0와 동적 특성을 재구성한다. 두 가지 샘플링 전략을 정의한다: (1) VAE‑PEAK: z=0 (사전 평균)으로 평균 억양을 재현, (2) VAE‑TAIL: 반경 r=3인 초구 표면에서 균등 샘플링(vMF 분포)하여 저확률 영역의 억양을 생성한다.
**5. 실험 시스템**
- **RNN**: 기존 MSE 기반 SPSS 모델.
- **MDN**: 4-성분 가우시안 혼합 모델, NLL 손실 사용.
- **VAE‑PEAK**: 위에서 설명한 평균 샘플링.
- **VAE‑TAIL**: 꼬리 샘플링.
- **RNN‑SCALED**: RNN 출력 F0를 수직으로 3배 확대해 변동성 인위적 증가.
- **COPY‑SYNTH**: 원본 녹음 그대로, 상한선.
- **BASELINE**: 단순 2차 다항식으로 적합한 F0, 하한선.
모델은 동일한 600차원 언어학적 라벨과 9개의 위치 특성을 입력으로 사용하고, WORLD 코덱으로 분석·합성한다.
**6. 가설**
1) VAE‑TAIL은 기존 SPSS보다 억양 변동성이 크다.
2) RNN‑SCALED, VAE‑TAIL, COPY‑SYNTH는 동일 수준의 변동성을 보인다.
3) RNN, VAE‑PEAK, MDN은 변동성이 비슷하고, MDN이 약간 더 크다.
4) VAE‑TAIL은 기존 SPSS보다 자연스러움이 약간 낮다.
5) VAE‑TAIL은 RNN‑SCALED보다 자연스러움이 크게 높다.
**7. 데이터**
Blizzard Challenge 2018 데이터(6.5시간, 7,250문장, 영국 남부 여성 음성)를 사용했으며, 기존 연구와 동일한 학습/검증/테스트 분할을 적용했다.
**8. 평가**
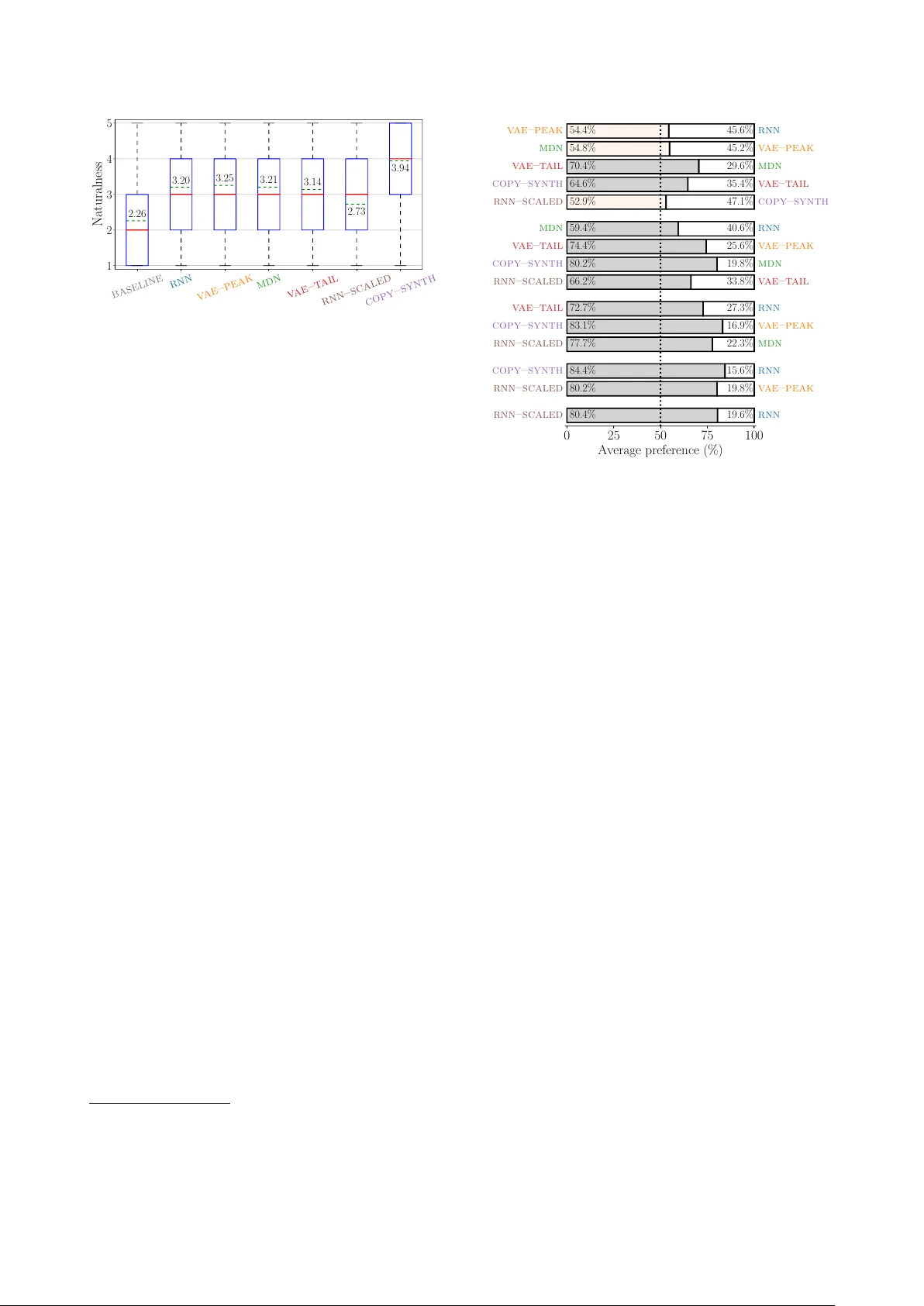
- **자연스러움**: 5점 Likert MOS, 30명 참여, 2×2 라틴 사각형 설계.
- **변동성**: 쌍별 선호 테스트(두 시스템 중 어느 것이 더 억양이 다양하게 들리는가). BASELINE은 변동성이 가장 낮아 테스트에서 제외. 32개의 테스트 문장을 무작위 선택.
**9. 결과**
자연스러움 점수는 VAE‑TAIL(2.73), RNN(2.26), MDN(3.20), VAE‑PEAK(3.21) 등에서 통계적으로 유의한 차이가 없었다. RNN‑SCALED는 평균 2.26으로 가장 낮았으며, COPY‑SYNTH는 3.94로 최고였다. 변동성 선호 테스트에서는 VAE‑TAIL이 MDN, RNN, VAE‑PEAK보다 현저히 높은 선호도를 얻었으며, RNN‑SCALED와는 비슷한 수준이지만 자연스러움에서는 VAE‑TAIL이 우수했다. 이는 가설 1, 4, 5를 지지하고, 가설 2,3은 부분적으로만 타당함을 보여준다.
**10. 논의 및 향후 과제**
VAE의 잠재공간을 활용해 저확률 영역을 샘플링하면 억양 변동성을 크게 늘리면서도 자연스러움을 유지할 수 있음을 실증하였다. 현재는 F0만 모델링했지만, 향후 지속시간·에너지까지 확장하면 전체 프로소디 다양성을 확보할 수 있다. 또한, 다중 모드 사전분포, VQ‑VAE와 같은 이산 잠재공간, 텍스트 기반 잠재값 예측(예: GST와 결합) 등을 도입하면 사용자 의도에 맞는 스타일 제어가 가능해질 것이다. 이러한 방향은 대화형 AI, 게임 내 캐릭터 음성, 맞춤형 내레이션 등 다양한 응용 분야에 적용될 잠재력을 가진다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기