예측 코딩 기반 양안 경쟁 네트워크를 활용한 무참조 입체 이미지 품질 측정
본 논문은 인간 시각 시스템의 양안 경쟁 현상을 예측 코딩 이론과 결합한 Siamese 인코더‑디코더 구조인 PAD‑Net을 제안한다. 왜곡된 좌·우 이미지 쌍을 입력으로 받아, 각각의 사전 확률 지도와 가능도 지도를 생성하고, 이를 품질 회귀 모듈에 통합해 무참조(stereoscopic) 이미지 품질을 예측한다. 세 개의 공개 데이터베이스에서 실험한 결과, 대칭·비대칭 왜곡 모두에서 기존 최첨단 NR‑SIQM 방법들을 능가한다.
저자: Jiahua Xu, Wei Zhou, Zhibo Chen
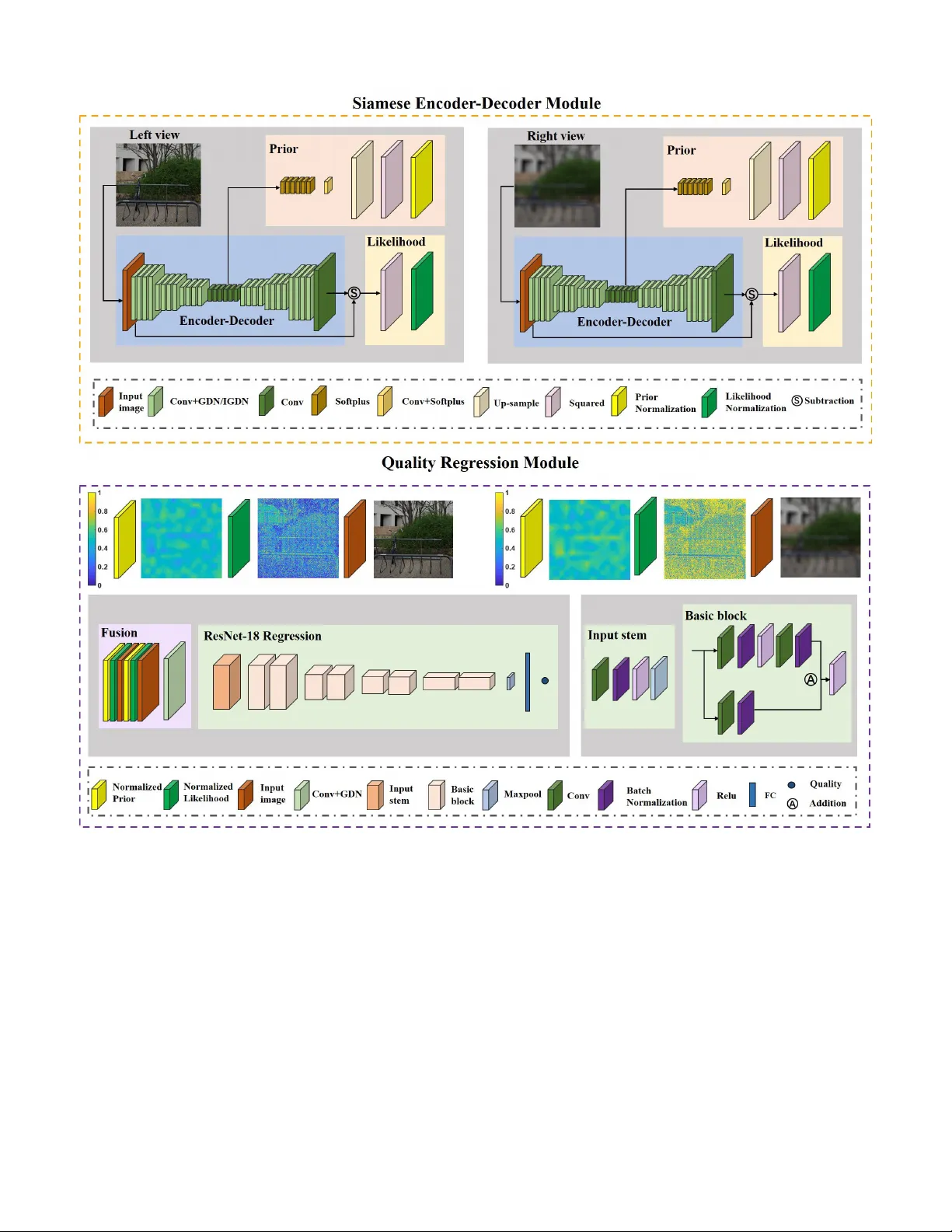
본 연구는 3차원 입체 영상의 품질을 주관적 인간 시각에 가깝게 평가하기 위해, 인간의 양안 경쟁 현상을 예측 코딩 이론과 결합한 새로운 무참조 품질 측정 프레임워크인 PAD‑Net을 제안한다. 기존의 NR‑SIQM(Blind/No‑Reference Stereoscopic Image Quality Measurement) 방법들은 주로 2D 이미지 품질 측정 기법을 확장하거나, 깊이 정보와 간단한 인간 시각 모델을 적용했지만, 양안 경쟁·융합·억제와 같은 복합적인 3D 시각 메커니즘을 충분히 반영하지 못했다.
PAD‑Net은 크게 두 부분으로 구성된다. 첫 번째는 Siamese 인코더‑디코더 모듈이다. 좌·우 두 뷰 이미지가 각각 동일한 인코더‑디코더 네트워크를 통과하면서, 인코더는 다중 스케일 특징을 추출하고 디코더는 입력을 재구성한다. 재구성 과정에서 발생하는 오류는 ‘가능도(likelihood)’ 지도로 변환된다. 오류가 작을수록 해당 가설이 입력을 잘 설명한다는 의미이며, 이는 베이즈 추론에서 사후 확률을 계산하는 데 사용된다. 동시에 인코더의 최상위 레이어에서 추출된 고수준 특징은 ‘사전(prior)’ 지도로 매핑된다. 사전은 인간이 사전에 가지고 있는 장면 구조·조명·재질 등에 대한 통계적 지식을 근사한다. 이렇게 얻어진 좌·우 각각의 가능도와 사전 지도는 베이즈 관점에서 결합되어 후방 확률(p(H|I))을 산출하고, 양안 경쟁 과정에서 어느 뷰가 지배적인지를 정량화한다.
두 번째는 품질 회귀 모듈이다. 원본 좌·우 이미지와 함께 생성된 네 개의 지도(좌·우 가능도, 좌·우 사전)를 채널 차원으로 결합한 ‘퓨전 이미지’를 입력으로, 다층 컨볼루션 신경망이 전역적인 품질 특성을 학습한다. 회귀 헤드는 평균 제곱 오차 손실을 최소화하도록 설계되었으며, 최종적으로 인간 주관 평가 점수인 MOS(Mean Opinion Score)를 예측한다.
학습 과정은 단계적이다. 먼저 Waterloo Exploration 데이터베이스와 2D 이미지 품질 데이터베이스(LIVE)를 이용해 인코더‑디코더와 회귀 모듈을 각각 사전 학습(pre‑training)한다. 이후 3D 전용 데이터베이스(LIVE‑3D, 3D‑IQM, 그리고 또 다른 공개 데이터베이스)를 사용해 전체 네트워크를 공동 최적화한다. 이렇게 하면 2D·3D 양쪽의 통계적 특성을 모두 활용하면서, 입체 영상 특유의 비대칭 왜곡에도 강인한 모델을 얻을 수 있다.
실험에서는 세 개의 대표적인 3D 품질 데이터베이스에서 PLCC(Pearson Linear Correlation Coefficient), SROCC(Spearman Rank Order Correlation Coefficient), KRCC(Kendall Rank Correlation Coefficient), RMSE(Root Mean Square Error) 네 가지 지표를 사용해 성능을 평가했다. PAD‑Net은 모든 지표에서 기존 최첨단 모델(DNR‑S3DIQE, StereoQA‑Net, DECOSINE, S3D‑BLINQ 등)을 능가했으며, 특히 비대칭 왜곡(한쪽은 블러, 다른 쪽은 노이즈 등) 상황에서 높은 상관성을 보였다. 시각적 사례 분석에서는 가능도 지도가 고품질 뷰의 강한 에지와 구조 정보를 강조하고, 사전 지도는 전체 장면 인식 가능성을 반영하는 모습을 확인했다. 이는 인간 관찰자가 비대칭 입체 영상에서 고품질 뷰에 더 큰 가중치를 두는 현상을 모델이 자연스럽게 학습했음을 의미한다.
또한, PAD‑Net은 파라미터 공유를 통한 Siamese 설계 덕분에 연산 효율성도 확보했다. 입력 이미지가 256×256 크기의 패치로 분할되어 처리되며, 최종 품질 점수는 모든 패치의 평균으로 집계한다. 이는 고해상도 영상에서도 실시간에 가까운 추론이 가능함을 시사한다.
결론적으로, 본 논문은 예측 코딩 이론을 기반으로 양안 경쟁을 정량화하고, 이를 딥러닝 네트워크에 통합함으로써 인간 시각 메커니즘에 부합하는 고성능 무참조 입체 이미지 품질 측정기를 제시한다. 향후 연구에서는 이 프레임워크를 깊이 추정, 3D 재구성, 가상 현실(VR) 콘텐츠 품질 평가 등 다른 3D 비전 과제로 확장하고, 더 정교한 사전·가능도 모델링을 통해 해석 가능성을 높이는 방향이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기