LogGraph 근접 최적 고성능 그래프 표현
초록
**
Log(Graph)는 그래프의 정점, 오프셋, 인접 리스트 등을 이론적 저장 하한에 맞춰 비트 단위로 압축하고, 최신 비트 연산과 압축 데이터 구조를 활용해 압축·해제 비용을 최소화한다. 실험 결과, 기존 GAP‑BS 기반 구현보다 20‑35 % 적은 메모리를 사용하면서도 동일하거나 2배 이상의 속도 향상을 달성한다.
**
상세 분석
**
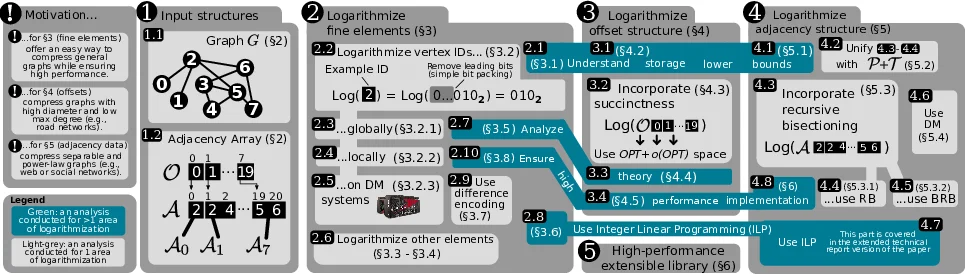
본 논문은 대규모 그래프 처리에서 메모리 대역폭과 저장 용량이 병목이 되는 문제를 해결하고자, “그래프 로그화(Graph logarithmization)”라는 새로운 설계 패러다임을 제시한다. 핵심 아이디어는 그래프의 각 구성 요소—정점 ID, 오프셋 배열, 인접 리스트, 가중치—에 대해 정보 이론적 최소 비트 수인 ⌈log |S|⌉(S는 해당 요소가 가질 수 있는 경우의 수) 만큼만 저장하도록 설계하는 것이다. 이를 위해 저자들은 세 가지 수준으로 압축을 적용한다.
첫 번째 수준(섹션 3)은 정점 ID와 오프셋, 가중치를 개별적으로 로그화한다. 전역 접근법에서는 모든 정점을 동일한 ⌈log n⌉ 비트로 인코딩하고, 로컬 접근법에서는 각 정점의 이웃 집합 크기 Nᵥ에 기반해 ⌈log |Nᵥ|⌉ 비트만 사용한다. 로컬 방식은 특히 저차수 정점이 많은 전력‑법 그래프에서 큰 절감 효과를 보이며, 이를 위해 각 정점마다 비트 길이를 저장하는 메타데이터를 추가하지만 전체 오버헤드는 미미하다.
두 번째 수준(섹션 4)은 오프셋 배열 O를 압축한다. 전통적인 인접 배열은 O에 O(n log n) 비트를 사용하지만, 저자들은 순위(rank)와 선택(select) 연산을 지원하는 압축 비트벡터와 간단한 차이 인코딩을 결합해 O를 O(m + o(m)) 비트 수준으로 줄인다. 이 구조는 상수 시간 접근을 보장하므로, BFS·PageRank·SSSP와 같은 반복적인 인접 탐색에 전혀 성능 저하를 일으키지 않는다.
세 번째 수준(섹션 5)은 실제 인접 리스트 A 자체를 압축한다. 여기서는 그래프가 갖는 구조적 특성(예: 분리 가능성, 전력‑법 차수 분포)을 활용해 재귀적 이분법(bisection)과 정점 재배열을 수행한다. 정점 재배열은 정수선형계획법(ILP) 기반 히어리스틱으로 구현되어, 고밀도 서브그래프가 연속적인 메모리 구간에 배치되도록 최적화한다. 결과적으로 A는 평균적으로 ⌈log |Nᵥ|⌉ 비트 수준으로 압축되며, 압축률은 WebGraph와 근접하지만, 압축·해제 과정이 거의 없으므로 실제 실행 시 2배 이상의 속도 향상을 얻는다.
성능 평가에서는 GAP‑BS 튜닝 버전과 비교해 20‑35 % 메모리 절감과 1.0‑2.2× 속도 향상을 보고한다. 특히 SSSP와 BFS에서 데이터 전송량 감소가 전체 실행 시간을 크게 단축시켰다. 또한, 분산 메모리 환경에서도 정점 ID를 intra/inter 파트로 나누어 인코딩함으로써 노드 간 통신 비용을 최소화한다.
이 논문은 압축 효율과 접근 속도 사이의 전통적인 트레이드오프를 비트‑레벨 설계와 최신 압축 데이터 구조를 통해 거의 무시할 수준으로 낮추었다는 점에서 의미가 크다. 특히, 그래프 알고리즘 라이브러리나 엔진에 손쉽게 통합할 수 있는 모듈형 설계와 오픈소스 구현을 제공함으로써 실무 적용 가능성을 높였다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기