Score‑P 로 파이썬 성능 모니터링 혁신
초록
본 논문은 고성능 컴퓨팅(HPC) 환경에서 파이썬 애플리케이션을 Score‑P 프레임워크와 연동해 트레이스와 프로파일링을 수행하는 바인딩을 소개한다. 구현 구조와 두 단계(준비 단계와 실행 단계)를 설명하고, sys.setprofile과 sys.settrace 두 가지 계측 방법의 오버헤드를 실험적으로 비교한다. 결과적으로 함수 호출 기반 계측(sys.setprofile)이 라인‑단위 계측(sys.settrace)보다 낮은 런타임 오버헤드를 보여 기본 옵션으로 채택되었다.
상세 분석
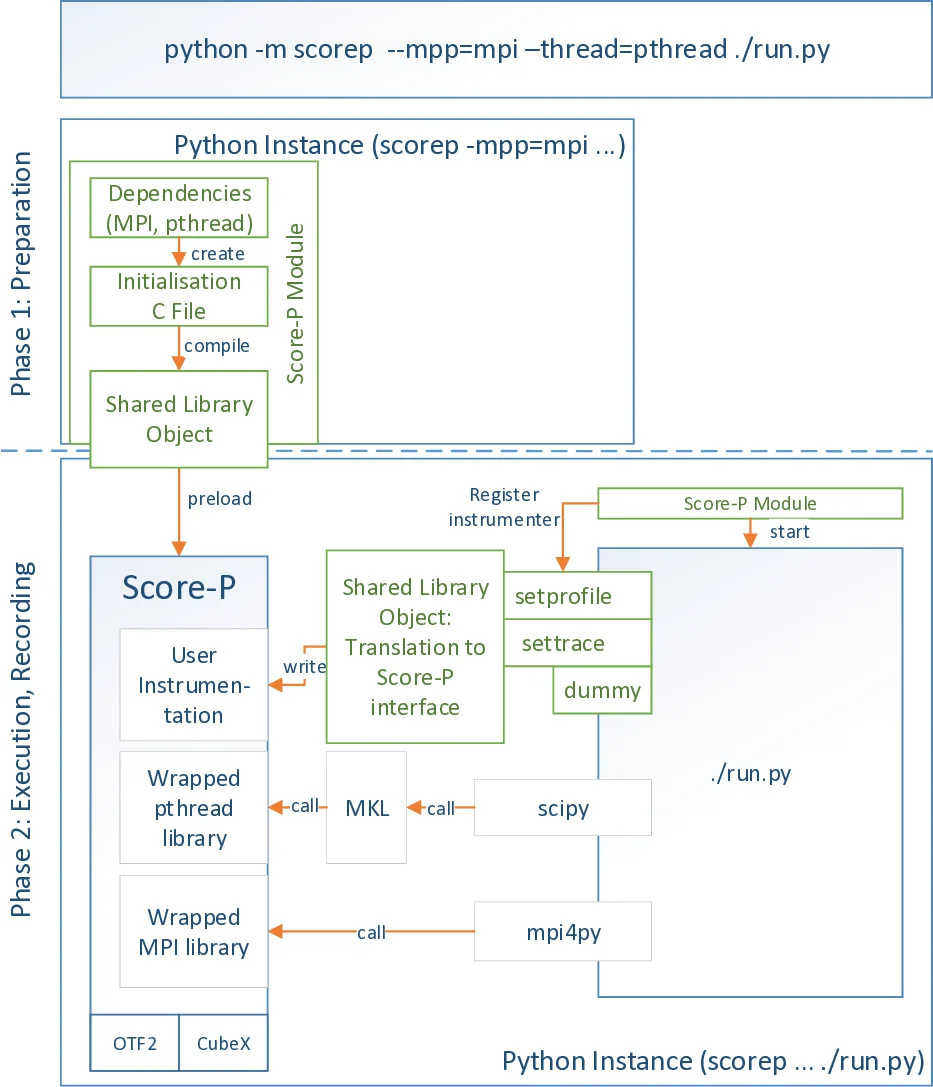
이 논문은 파이썬이 과학·공학 분야에서 널리 사용됨에도 불구하고, 기존의 파이썬 전용 프로파일러는 MPI·OpenMP·CUDA와 같은 HPC 수준의 병렬성을 지원하지 못한다는 문제점을 지적한다. 이를 해결하기 위해 저자들은 Score‑P라는 확장성이 뛰어난 성능 분석 인프라에 파이썬 바인딩을 추가하였다. 구현은 크게 두 블록으로 나뉜다. 첫 번째는 ‘준비 단계’로, 사용자가 scorep‑mpp 옵션을 통해 원하는 병렬 모델(MPI, pthread, CUDA 등)을 지정하고, LD_PRELOAD를 이용해 Score‑P 라이브러리를 파이썬 인터프리터에 사전 로드한다. 이 단계에서 파이썬 인터프리터는 os.execve를 통해 재시작되며, Score‑P 초기화 코드가 생성·컴파일된다. 두 번째는 ‘실행 단계’로, 실제 파이썬 스크립트가 컴파일·실행되는 동안 두 종류의 콜백(sys.setprofile, sys.settrace)을 이용해 이벤트를 캡처한다. sys.setprofile은 함수 진입·종료와 C 함수 호출을 포착하고, sys.settrace는 라인‑단위 실행 흐름을 기록한다. 캡처된 이벤트는 C‑바인딩을 통해 Score‑P에 전달되어 OTF2 트레이스, Cube 프로파일 등 다양한 포맷으로 저장된다.
오버헤드 평가에서는 두 개의 마이크로벤치마크를 사용하였다. 첫 번째는 순수 루프만 수행해 함수 호출이 없으므로 sys.setprofile은 거의 영향을 주지 않으며, sys.settrace는 라인당 콜백 호출 때문에 반복 횟수에 비례한 오버헤드가 발생한다. 두 번째는 함수 호출을 포함해 두 계측기 모두 반복 횟수에 비례한 비용이 증가한다. 실험 결과, 초기 설정 비용은 약 0.6 초로 동일했으며, per‑iteration 비용은 sys.setprofile이 0.17 µs0.3 µs, sys.settrace가 0.98 µs17.9 µs로 크게 차이났다. 따라서 저자들은 기본 계측기로 sys.setprofile을 선택하고, 필요 시 라인‑단위 정보는 선택적으로 활성화하도록 설계하였다.
관련 작업에서는 기존 파이썬 프로파일러(cProfile, pyprof2calltree 등)와 HPC 전용 트레이서(Extrae, TAU)를 비교한다. 기존 프로파일러는 단일 노드 분석에 국한되고 MPI·OpenMP·CUDA와 같은 병렬 이벤트를 포착하지 못한다. 반면 Extrae와 TAU는 C‑API를 이용해 파이썬 콜백을 등록하지만 구현 방식이 다르고, 성능 최적화 측면에서 Score‑P와의 통합이 제한적이다.
향후 과제는 샘플링 기반 계측 도입, 예외·라인 정보 선택적 기록, 그리고 자동 오버헤드 조절 메커니즘을 포함한다. 현재 바인딩은 GitHub(https://github.com/score‑p/scorep_binding_python)에서 공개되어 커뮤니티 기여가 가능하다.
댓글 및 학술 토론
Loading comments...
의견 남기기