스트리밍 음악에서 몇 샷 순차 스킵 예측
본 논문은 Spotify가 제공한 청취 세션 데이터를 활용해, 첫 절반의 사용자 로그와 음향 특징을 기반으로 두 번째 절반 트랙의 스킵 여부를 예측하는 두 가지 접근법을 제시한다. 메트릭 학습과 시퀀스 학습을 각각 구현했으며, 실험 결과 시퀀스 학습 모델이 메트릭 학습 모델보다 5.9%p 이상 높은 Mean Average Accuracy(MAA)를 기록하였다. 또한, 쿼리 단계에 사용자 로그 전체를 제공하면 성능이 21.1%p 상승한다는 추가 …
저자: Sungkyun Chang, Seungjin Lee, Kyogu Lee
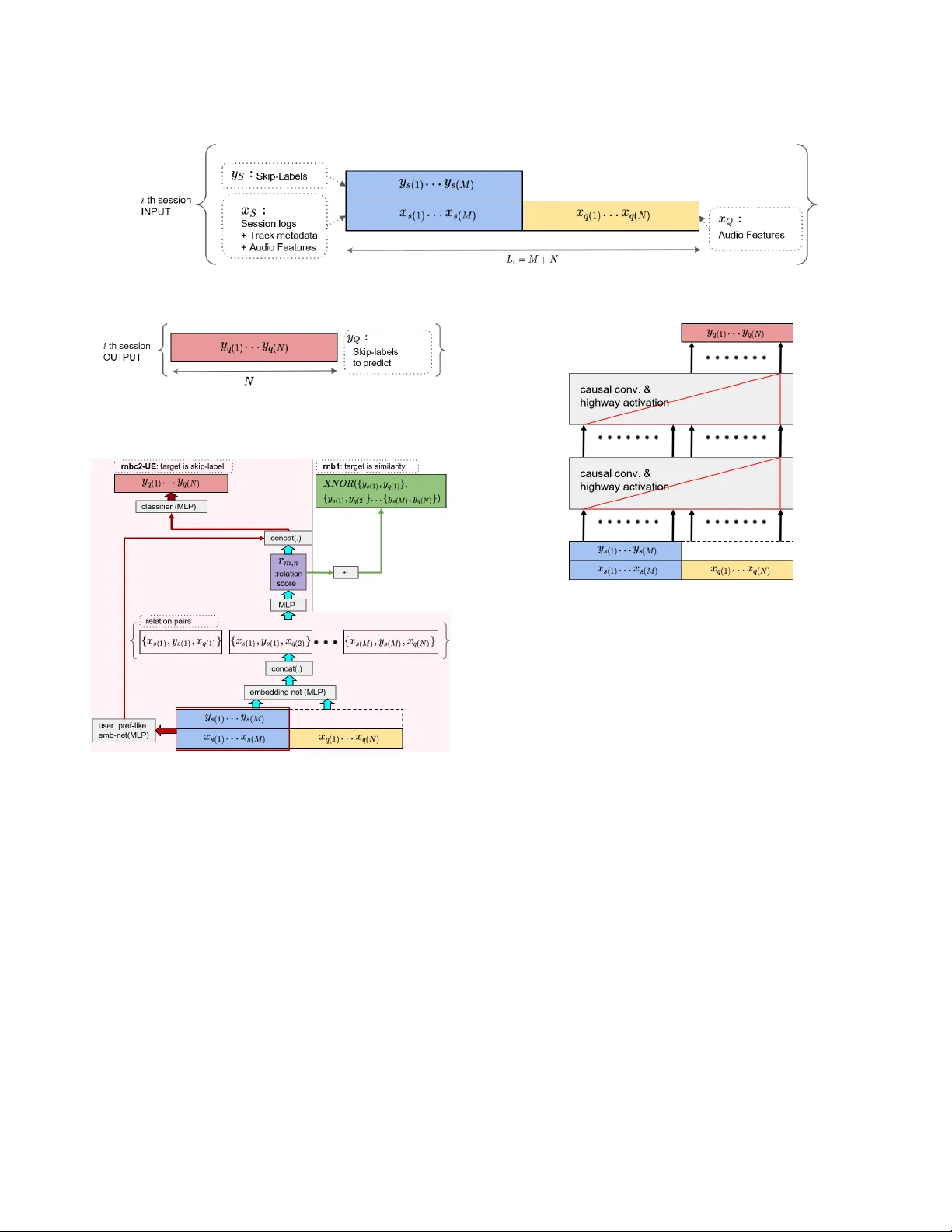
본 논문은 2019년 WSDM Cup에서 제시된 Spotify Sequential Skip Prediction Challenge에 참가한 팀 mimbres(논문에서는 mimbres로 표기)의 솔루션을 상세히 기술한다. 챌린지는 청취 세션 데이터를 활용해, 세션의 앞 절반(지원 집합)에서 제공되는 음향 특징과 사용자 로그를 바탕으로 뒤 절반(쿼리 집합) 트랙의 스킵 여부를 예측하는 과제이다. 세션 길이는 10~20 트랙이며, 지원 집합에는 스킵 라벨(Y_s)과 로그가, 쿼리 집합에는 음향 특징만 제공된다. 목표는 {X_s, Y_s, X_q}를 입력으로 Y_q를 예측하는 것이다.
연구는 두 가지 큰 범주의 모델을 설계하였다. 첫 번째는 메트릭 학습(metric learning) 기반 접근법이다. 이 접근법은 순서 정보를 가정하지 않고, 지원‑쿼리 쌍을 비교하는 관계 네트워크(Relation Network, RN)를 학습한다. 구체적으로, 입력 x_s와 x_q를 각각 256 차원의 임베딩으로 변환한 뒤, RN에 전달해 관계 점수 r_{m,n}를 산출한다. 초기 모델(rnb1)은 관계 점수를 XNOR 기반 이진 유사도와 MSE 손실로 학습하였다. 이후 rnb2‑UE는 두 개의 추가 임베딩 레이어를 삽입해 사용자 선호를 더 잘 반영하도록 개선했으며, rnbc2‑UE는 목표를 유사도에서 직접 스킵 라벨 예측으로 바꾸어 성능을 1%p 상승시켰다. 그러나 메트릭 학습은 트랙 간 시간적 연관성을 무시하기 때문에, 실제 청취 흐름을 모델링하는 데 한계가 있었다.
두 번째는 시퀀스 학습(sequence learning) 기반 접근법이다. 여기서는 인과적(dilated causal) 컨볼루션 레이어와 highway 혹은 GLU 활성화를 결합한 구조를 사용한다. 기본 모델(seq1eH)은 1‑stack 인코더를, 최종 모델(seq1HL)은 2‑stack 인코더를 적용해 깊이를 늘렸다. dilation 파라미터는 {1,2,4,8,16}이며, 커널 크기는 2로 설정해 넓은 수용 영역을 확보한다. 비자동회귀(non‑AR) 설계와 인스턴스 정규화(instance norm)를 도입해 학습 안정성을 높였으며, 손실은 Y_q에 대한 binary cross‑entropy를 사용했다.
추가로, 지원과 쿼리 각각에 별도 인코더를 두고 dot‑product attention을 적용한 att(seq1eH(S), seq1eH(Q)) 모델과, SNAIL‑style 멀티‑head attention(8 heads)을 결합한 변형 모델도 실험되었다. 흥미롭게도, attention을 포함한 모델들은 시퀀스 학습만 사용한 모델보다 약간 낮은 MAA를 보였으며, 가장 높은 성능은 attention 없이 순수 dilated convolution 기반 seq1HL이 0.638(MAA, validation)으로 나타났다.
실험 설정은 전체 훈련 데이터의 80%를 학습, 20%를 검증에 사용했으며, Adam 옵티마이저(lr=1e‑3, 30% decay per epoch)와 배치 크기 2048을 적용했다. 메트릭 학습 모델은 MAA가 -0.540~0.574 수준인 반면, 시퀀스 학습 모델은 0.630 이상을 기록했다. 특히, Teacher 모델은 쿼리 단계에 사용자 로그와 음향 특징을 모두 제공했을 때 MAA가 0.849로 크게 상승했으며, 이는 로그 정보가 스킵 예측에 매우 중요한 역할을 함을 시사한다.
논문의 주요 기여는 다음과 같다. (1) 동일 데이터셋에 메트릭 학습과 시퀀스 학습을 적용해 성능 차이를 정량적으로 비교하였다. (2) 시퀀스 학습이 실제 스트리밍 환경에서 사용자 행동을 예측하는 데 더 효과적임을 입증하였다. (3) 쿼리 단계에 로그 정보를 제공했을 때 성능이 크게 향상된다는 실험 결과를 제시하였다. 한계점으로는 외부 데이터나 사전 학습된 모델을 활용하지 않았으며, 메트릭 학습이 순서 정보를 전혀 활용하지 못한다는 구조적 제약이 있다. 향후 연구에서는 메트릭 학습에 순차 정보를 통합하거나, 로그 정보를 자동으로 압축·전달하는 지식 증류(distillation) 기법을 탐색할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기