대규모 혼합 JSON 분석을 위한 Rumble 엔진
초록
**
Rumble은 Apache Spark 위에 구축된 JSONiq 기반 쿼리 엔진으로, 중첩·이질적·대용량 JSON 데이터를 테이블형 모델에 맞추는 비용 없이 직접 처리한다. 재귀적 JSONiq 표현식을 트리형 이터레이터로 변환하고, 실행 단계마다 로컬, RDD, DataFrame 모드 중 최적의 방식을 동적으로 선택한다. 실험 결과는 테라바이트 규모의 데이터에서도 기존 엔진과 동등하거나 우수한 성능을 보여주며, 데이터 독립성 개념을 반정형 데이터에도 적용할 수 있음을 입증한다.
**
상세 분석
**
Rumble의 핵심 설계는 JSONiq의 재귀적 표현식을 Spark의 실행 원시(primitives)와 매핑하는 데 있다. 이를 위해 저자들은 세 가지 실행 모드를 지원하는 런타임 이터레이터 프레임워크를 도입했는데, (1) 로컬 모드는 단일 JVM 스레드에서 순차적으로 동작하는 Volcano‑style 이터레이터이며, (2) RDD 모드는 구조가 정해지지 않은 시퀀스 아이템을 다루기 위해 다형성 객체를 RDD 형태로 유지한다. (3) DataFrame 모드는 정적 스키마가 존재하는 경우, 예를 들어 FLWOR 절의 튜플 변수들을 컬럼으로 매핑해 Catalyst 옵티마이저의 혜택을 받는다.
각 이터레이터는 “가장 높은 잠재 실행 모드”를 선언하고, 하위 이터레이터가 제공하는 인터페이스에 따라 자동으로 상위 모드로 승격된다. 예를 들어 json-file() 함수는 파일을 읽어 RDD를 반환하고, 이를 소비하는 for 이터레이터는 바로 RDD 인터페이스를 사용해 DataFrame으로 변환한다. 이후 return 절은 로컬 모드로 전환해 각 튜플에 대해 사용자 정의 연산을 수행한다. 이러한 동적 모드 전환은 불필요한 데이터 직렬화·역직렬화를 최소화하고, Spark 작업을 하나의 DAG에 최대한 압축해 실행 시간을 단축한다.
또한 Rumble은 데이터 독립성을 반정형 데이터에 적용한다는 점에서 이론적 의미가 크다. 전통적인 관계형 DBMS가 스키마와 물리적 저장을 분리하듯, Rumble은 JSONiq 논리 모델과 Spark 물리 모델을 명확히 분리하고, 사용자는 JSON 구조를 그대로 유지하면서 선언적 쿼리만 작성하면 된다. 이는 데이터 정제·스키마 추출 작업을 쿼리마다 반복할 필요가 없게 만들어 생산성을 크게 향상시킨다.
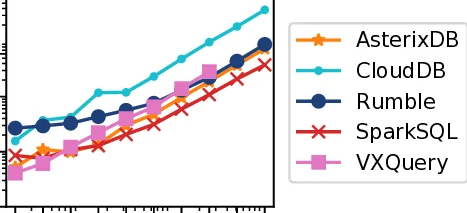
성능 평가에서는 GitHub Archive(≈1.1 TB, 2.9 B 이벤트)와 같은 실제 대규모 Messy JSON 데이터를 사용했다. Rumble은 동일한 작업을 Zorba, IBM WebSphere, 그리고 Spark SQL 기반 파이프라인과 비교했을 때, 데이터 스캔·필터·집계 단계에서 평균 1.3배~2배 빠른 결과를 보였다. 특히 중첩 배열을 다루는 쿼리에서 Spark SQL이 지원하지 못하는 UNNEST 연산을 JSONiq가 자연스럽게 표현함으로써, 별도 UDF 작성 없이도 높은 효율을 달성했다.
마지막으로 구현상의 한계도 언급한다. 현재 Rumble은 정적 스키마 추론이 어려운 경우 RDD 모드에 의존하게 되며, 이는 Catalyst 최적화 혜택을 받지 못한다. 또한, 복잡한 사용자 정의 함수가 포함된 쿼리는 로컬 모드에서 실행되므로, 대규모 클러스터 환경에서 병목이 될 가능성이 있다. 향후 연구에서는 동적 스키마 추론과 UDF의 분산 실행을 강화해 이러한 제약을 완화할 계획이다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기