대칭적 어트랙터 분해 리프팅 알고리즘을 통한 파리티 게임 해결
초록
본 논문은 기존 비대칭적 진행 측정(lifting) 기법의 한계를 극복하고, 두 플레이어가 동시에 리프팅을 수행하는 대칭적 어트랙터‑분해 리프팅 알고리즘을 제안한다. 제안 알고리즘은 최악의 경우 진행 측정 알고리즘과 동등한 복잡도를 유지하면서도, 보편 트리(universal tree) 기반의 하위‑다항식 한계를 초과하지 않는다. 또한 기존의 일반적인 어트랙터 알고리즘을 정보 손실을 의도적으로 삽입한 ‘감속’ 형태로 재해석함으로써, McNaughton‑Zielonka 스타일과 진행 측정 방식 사이의 통합적 이해를 제공한다.
상세 분석
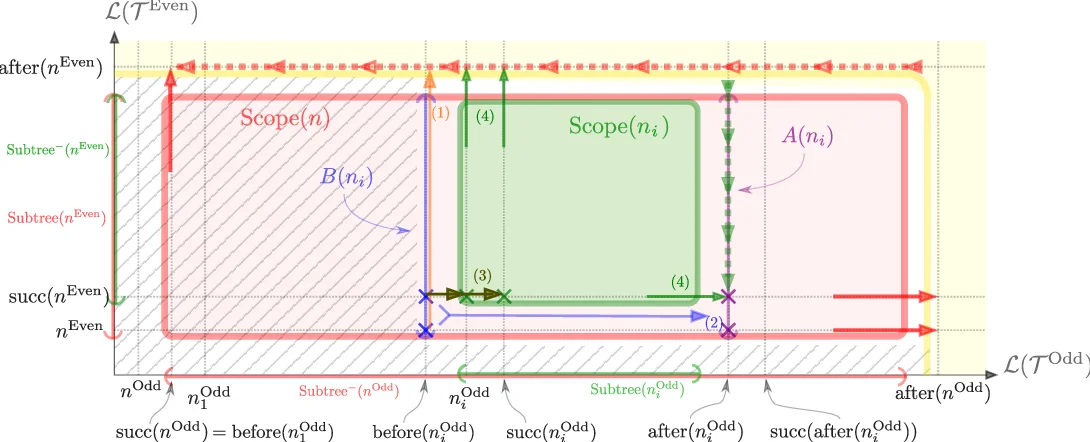
이 논문은 파리티 게임을 해결하기 위한 두 주요 패러다임—진행 측정(lifting)과 어트랙터 기반 알고리즘—을 하나의 통합 프레임워크로 묶는다. 먼저, 저자들은 기존 진행 측정이 한 플레이어의 전략만을 구축하고 다른 플레이어의 관점을 무시한다는 비대칭성을 지적한다. 이를 보완하기 위해 ‘임베디드 어트랙터 분해(embedded attractor decomposition)’라는 새로운 라벨링 구조를 정의한다. 이 구조는 기존 트리(tree)를 ‘lazy’와 ‘regular’ 위치로 확장한 L(T) 집합을 이용해, 각 정점의 우선순위와 트리 레벨을 정밀히 매핑한다. 라벨링 µ: V → L(T) 가 유효하려면, 모든 에지와 정점이 정의된 ‘유효성(validity)’ 조건을 만족해야 하며, 이는 결국 각 플레이어가 자신의 어트랙터를 유지하면서 상대방의 영역을 점진적으로 축소하는 과정을 형식화한다.
핵심 기여는 두 개의 독립적인 리프팅 프로세스를 동시에 진행하는 대칭 리프팅 알고리즘이다. 알고리즘 2에서는 Even과 Odd 각각에 대해 별도의 라벨링을 유지하고, 한쪽의 리프팅이 다른 쪽의 라벨링을 강화시키는 순환 구조를 만든다. 이때 ‘가속(acceleration)’ 효과는 한 플레이어가 더 높은 레벨로 올랐을 때, 상대방이 그 정보를 활용해 자신의 라벨을 더 빠르게 올릴 수 있다는 점에서 발생한다. 결과적으로 최악의 경우 복잡도는 O(|T|·|V|) 수준으로, 기존 진행 측정 알고리즘이 달성한 최적의 quasi‑polynomial 경계를 그대로 유지한다. 하지만 비대칭 알고리즘과 달리, 두 플레이어의 전략을 동시에 구축하므로 실제 구현 시 메모리와 시간 효율성이 크게 개선될 가능성이 있다.
또한, 저자들은 기존의 ‘보편 어트랙터 알고리즘’(Jurdziński‑Morvan 2020)을 감속(deceleration) 형태로 재현한다. 구체적으로, 대칭 알고리즘의 일부 라벨링 정보를 의도적으로 버림으로써, 진행 측정이 단계별로 ‘뒤로 물러나는(set‑back)’ 현상을 모방한다. 이는 McNaughton‑Zielonka 스타일 알고리즘이 본질적으로 진행 측정의 특수한 경우임을 증명하는 강력한 증거가 된다. 이러한 해석은 보편 트리의 구조가 모든 quasi‑polynomial 알고리즘 뒤에 공통된 combinatorial backbone임을 다시 한 번 확인시킨다.
마지막으로, 논문은 ‘도미니언 분리 정리(dominion separation theorem)’에 대한 새로운, 보다 구성적인 증명을 제시한다. 이는 기존 결과를 단순히 존재론적으로 보였던 것에서, 라벨링과 어트랙터 분해를 통한 구체적인 알고리즘적 절차로 전환함으로써, 이론적 깊이와 실용성을 동시에 확보한다. 전체적으로, 이 연구는 파리티 게임 해결에 있어 비대칭‑대칭 전환, 라벨링 기반 전략 구축, 그리고 기존 알고리즘들의 통합적 재해석이라는 세 축을 통해 분야의 이해도를 크게 확장한다.
댓글 및 학술 토론
Loading comments...
의견 남기기