보조 분류기 변분 오토인코더 기반 비평행 다대다 음성 변환
본 논문은 비평행 다대다 음성 변환을 위해 보조 분류기 변분 오토인코더(ACVAE)를 제안한다. 완전 합성곱 구조를 이용해 시간 의존성을 학습하고, 정보이론적 정규화를 통해 클래스 라벨이 변환 과정에서 사라지지 않도록 한다. 또한 변환 후 스펙트럼 세부 정보를 원본 음성에 전이시켜 버즈 현상을 완화한다.
저자: Hirokazu Kameoka, Takuhiro Kaneko, Kou Tanaka
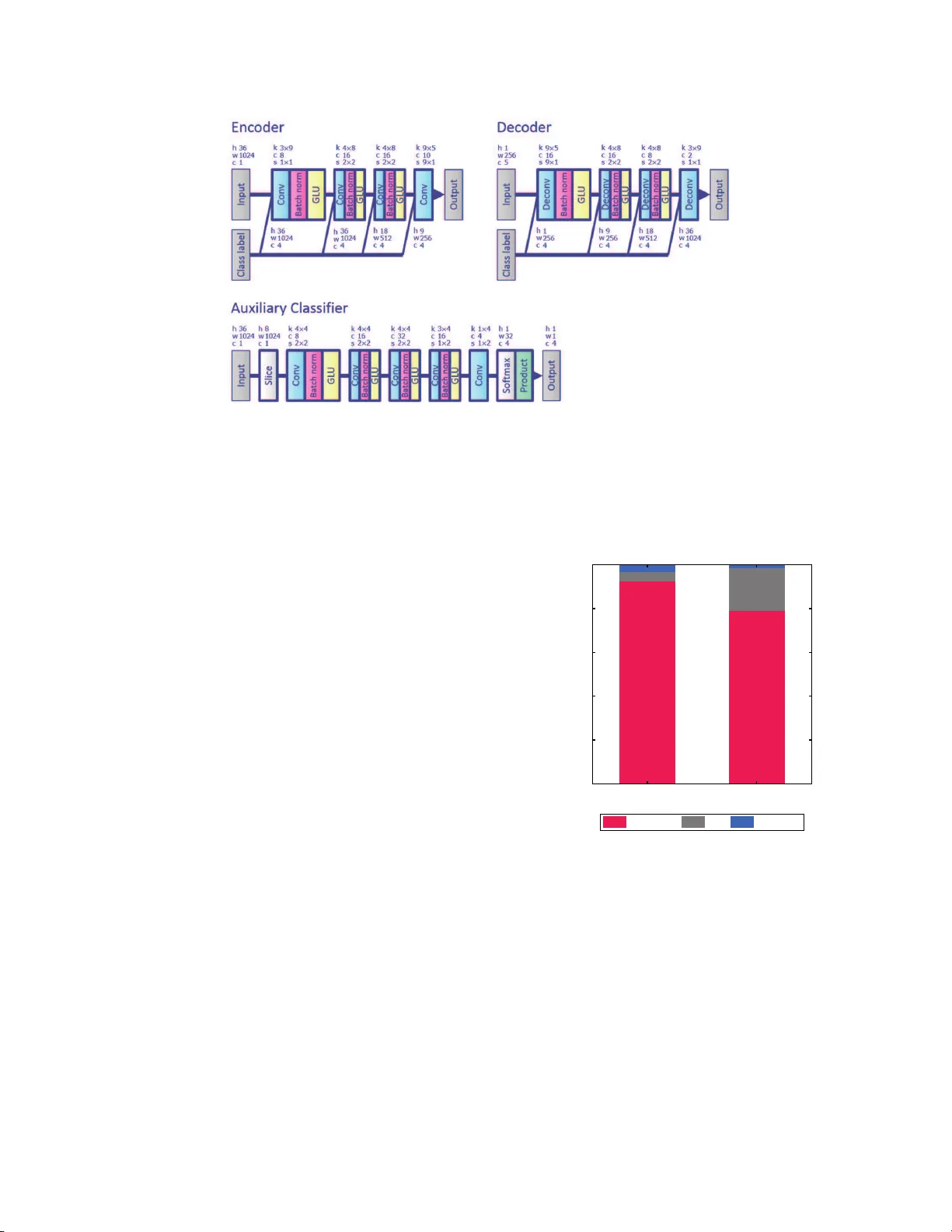
본 논문은 비평행 다대다 음성 변환(Voice Conversion, VC) 문제를 해결하기 위해 ‘보조 분류기 변분 오토인코더(Auxiliary‑Classifier VAE, ACVAE)’라는 새로운 모델을 제안한다. 기존 CVAE 기반 VC는 (1) 프레임‑단위 입력·출력으로 시간적 연속성을 충분히 학습하지 못하고, (2) 인코더·디코더가 라벨 c를 무시해 변환 시 목표 화자 정보가 반영되지 않으며, (3) 가우시안 출력으로 인한 스펙트럼 과도 평활(버즈 현상)이라는 세 가지 주요 한계가 있었다.
첫 번째 한계 극복을 위해 저자들은 완전 합성곱 신경망(Fully‑Convolutional Network, FCN)을 인코더와 디코더에 적용하였다. 입력은 멜‑스펙트로그램 형태의 시퀀스 x∈ℝ^{Q×N}이며, FCN은 1‑D 컨볼루션 레이어와 적절한 패딩·스트라이드 조합을 통해 입력 길이와 동일한 길이의 출력 시퀀스를 생성한다. 이렇게 하면 인접 프레임뿐 아니라 넓은 수용 영역을 갖는 필터를 통해 장·단기 시간 의존성을 동시에 학습할 수 있다. RNN보다 파라미터 효율이 높고, 병렬 연산이 가능하다는 부가 장점도 있다.
두 번째 한계인 라벨 무시 문제를 해결하기 위해 정보‑이론적 정규화 기법을 도입한다. 변환된 출력 x̂에 대해 보조 분류기 rψ(c|x̂) 를 학습시키고, 변환 과정에서 라벨 c와 출력 x̂ 사이의 조건부 상호 정보 I(c; x̂ | z)를 최대화한다. 구체적으로, 변분 하한을 이용해 L(φ,θ,ψ)=E_{(c̃,x̃)∼p_D} E_{z∼qφ(z|x̃,c̃)} E_{c∼p(c)} E_{x∼pθ(x|z,c)}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기