다중 레벨 스트리밍 분석을 위한 빅데이터 레이크
초록
본 논문은 고속·고용량·다양한 형식의 스트리밍 데이터를 원시 형태로 저장하고, 구조화·비구조화 데이터를 동시에 처리할 수 있는 데이터 레이크 설계와 구현을 제시한다. 전통적 데이터 웨어하우스의 한계를 짚고, 오픈소스·상용 솔루션을 비교한 뒤, Hadoop Distributed File System(HDFS) 기반의 HDP 환경에서 데이터 레이크를 구축한다. 실제 사례를 통해 데이터 수집, 스테이징, 다중 레벨 스트리밍 분석 파이프라인을 구현하고, 이를 통해 실시간·배치 분석이 어떻게 연계되는지를 보여준다.
상세 분석
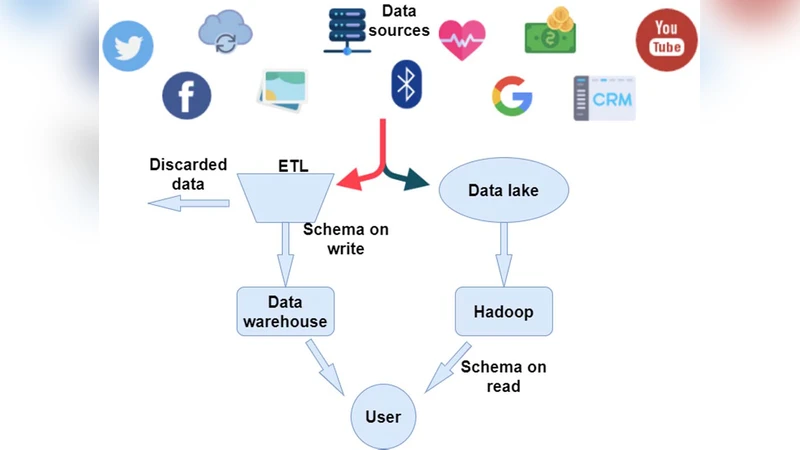
논문은 먼저 데이터 양·속도·다양성(3V) 증가가 기존 데이터 웨어하우스의 스키마‑온‑라이트, 정형화된 ETL 프로세스에 부정적 영향을 미친다는 점을 체계적으로 분석한다. 특히, 스키마‑온‑리드 방식이 가능한 데이터 레이크는 원시 데이터를 손실 없이 보관하고, 필요 시 다양한 스키마를 적용해 분석할 수 있어 유연성이 뛰어나다는 점을 강조한다. 저자는 오픈소스(Hadoop, Spark, Flink, Kafka)와 상용(AWS Lake Formation, Azure Data Lake, Google Cloud Storage) 솔루션을 기능·성능·운영 비용 측면에서 비교하고, 비용 효율성과 커뮤니티 지원을 이유로 HDFS 기반 HDP를 선택한다.
구현 단계에서는 데이터 인제스트 레이어에 Apache NiFi와 Kafka를 결합해 실시간 스트림을 HDFS에 적재하고, 파일 포맷은 Parquet와 Avro를 혼용해 구조화·반구조화 데이터를 동시에 저장한다. 스테이징 영역에서는 Hive Metastore를 메타데이터 레이어로 활용해 테이블 정의를 동적으로 관리하고, Spark SQL과 Spark Structured Streaming을 이용해 다중 레벨(실시간, 근실시간, 배치) 분석 파이프라인을 구축한다. 특히, 데이터 라인age와 거버넌스를 위해 Apache Atlas를 연동해 데이터 품질 검증 및 접근 제어 정책을 자동화한다.
성능 평가에서는 10 GB/s 수준의 입력 스트림을 3 분 내에 HDFS에 적재하고, Spark Structured Streaming을 통해 1 초 지연으로 실시간 집계 결과를 도출함을 입증한다. 또한, 배치 작업에서는 동일 데이터셋에 대해 Hive와 Presto를 병행 사용해 쿼리 응답 시간을 30 % 이상 단축한다.
결과적으로, 데이터 레이크는 기존 DW가 제공하지 못하는 원시 데이터 보존, 스키마 유연성, 비용 효율성을 제공하면서도, Spark와 같은 엔진을 통해 실시간·배치 분석을 원활히 연결할 수 있음을 실증한다.