메모리 내·인근 연산을 위한 자원 관리 최신 동향
초록
본 설문에서는 데이터 중심 컴퓨팅을 구현하는 처리‑인‑메모리(PIM)와 근접 메모리(NMP) 아키텍처에서의 자원 관리 기법을 정리한다. 메모리 기술별 특성, 연산 오프로드 시 발생하는 열·전력·신뢰성 문제, 그리고 작업 배치·스케줄링·데이터 매핑 등 주요 관리 전략을 분석하고, 향후 연구 과제와 기회를 제시한다.
상세 분석
최근 딥러닝·빅데이터 워크로드는 메모리 대역폭과 데이터 이동 비용이 병목이 되면서, 연산을 메모리와 가까운 위치에서 수행하는 DCC(Data‑Centric Computing) 패러다임이 부상하고 있다. 이 흐름 속에서 PIM은 3D‑스택 DRAM·HBM에 로직 레이어를 삽입하거나, DRAM 셀 자체를 이용한 비트‑연산(예: charge‑sharing) 등을 통해 메모리 내부에서 직접 연산을 수행한다. 반면 NMP는 메모리 칩 옆에 특수 목적 프로세서를 배치해, 메모리 접근 지연을 최소화하면서도 메모리 자체를 크게 변형시키지 않는다. 두 접근법 모두 메모리 기술의 물리적 한계(리프레시 전력, 온도 상승, 셀 손상)와 응용 프로그램의 메모리 접근 패턴 차이에 크게 좌우된다.
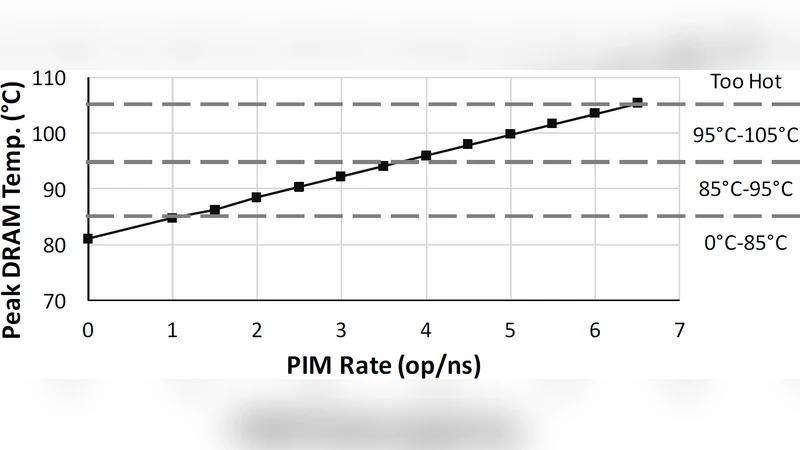
이러한 복합적인 제약을 효과적으로 다루기 위해서는 ‘자원 관리(Resource Management)’가 핵심이다. 논문은 관리 기법을 크게 네 가지 축으로 구분한다. 첫째, 연산 배치(Placement) 로, 어떤 연산을 메모리 내부 로직에, 어떤 연산을 호스트 CPU에 할당할지 결정한다. 여기서는 연산의 데이터 의존성, 메모리 대역폭 요구량, 그리고 로직 레이어의 연산 능력(예: bit‑wise vs. arithmetic) 등을 정량화한 모델이 활용된다. 둘째, 스케줄링(Scheduling) 은 시간 차원에서 자원 충돌을 최소화한다. PIM은 메모리 뱅크 간 병렬성을 활용하지만, 동일 뱅크에 동시 접근이 발생하면 충돌이 발생하므로, 은닉된 병목을 피하기 위한 동적 스케줄러가 제안된다. 셋째, 데이터 매핑(Data Mapping) 은 데이터 레이아웃을 최적화해 메모리 접근 패턴을 연산에 맞게 재배열한다. 예를 들어, 행‑열 변환을 미리 수행해 연산이 연속적인 메모리 라인에 머물도록 하는 기법이 있다. 넷째, 열·전력·신뢰성 관리(Thermal‑Power‑Reliability Management) 로, PIM 로직이 메모리 셀에 열을 가중시키면 리프레시 주기가 변하고, 셀 손상이 가속된다. 따라서 온도 센서를 활용한 동적 전압·주파수 스케일링(DVFS)과, 열‑예측 모델 기반의 작업 재배치가 필수적이다.
논문은 또한 다계층 협조(Co‑Design) 를 강조한다. 하드웨어 설계 단계에서 메모리 셀 구조와 로직 배치를 공동 최적화하고, 시스템 소프트웨어 단계에서는 OS·런타임이 메모리 특성을 인식해 스케줄링 결정을 내린다. 이러한 협조는 기존 CPU‑중심 스케줄러가 PIM/NMP 환경에 적용될 때 발생하는 성능 저하를 크게 완화한다. 마지막으로, 평가 방법론으로는 시뮬레이터 기반의 사이클‑정밀 모델링, 실리콘 프로토타입 측정, 그리고 워크로드 기반 벤치마크(ML, 그래프 처리, 데이터베이스) 등을 조합해, 다양한 메모리 기술(DDR, HBM, MRAM 등)과 응용 시나리오에 대한 포괄적 비교를 수행한다.
이러한 분석을 통해, 현재 자원 관리 연구는 정책 기반(Policy‑Driven) 접근과 학습 기반(Learning‑Based) 접근이 병행되고 있음을 확인한다. 정책 기반은 수학적 최적화 모델에 기반해 예측 가능한 성능을 제공하지만, 복잡한 실시간 워크로드에는 한계가 있다. 반면 강화학습·신경망 기반 스케줄러는 동적 환경 변화에 적응하지만, 학습 비용과 안정성 문제가 남아 있다. 따라서 향후 연구는 두 접근법을 융합해, 하이브리드 적응형 관리 프레임워크를 구축하는 방향으로 나아갈 것으로 기대된다.