악의적 전문가 앞에 무너지는 학습 시스템: 곱셈 가중치 알고리즘의 취약성 분석
본 연구는 곱셈 가중치(MW) 규칙을 사용하는 학습 시스템에서, 한 명의 전문가가 악의적으로 행동할 때 시스템 성능에 미치는 영향을 분석합니다. 오프라인 환경에서는 단순히 항상 거짓말하는 정책이 최적에 근접하며, 온라인 환경에서는 동적 프로그래밍을 통해 최적 공격 정책을 효율적으로 계산할 수 있음을 보입니다. 이는 널리 사용되는 학습 알고리즘의 취약성 평가에 새로운 방향을 제시합니다.
저자: S. Rasoul Etesami, Negar Kiyavash, Vincent Leon
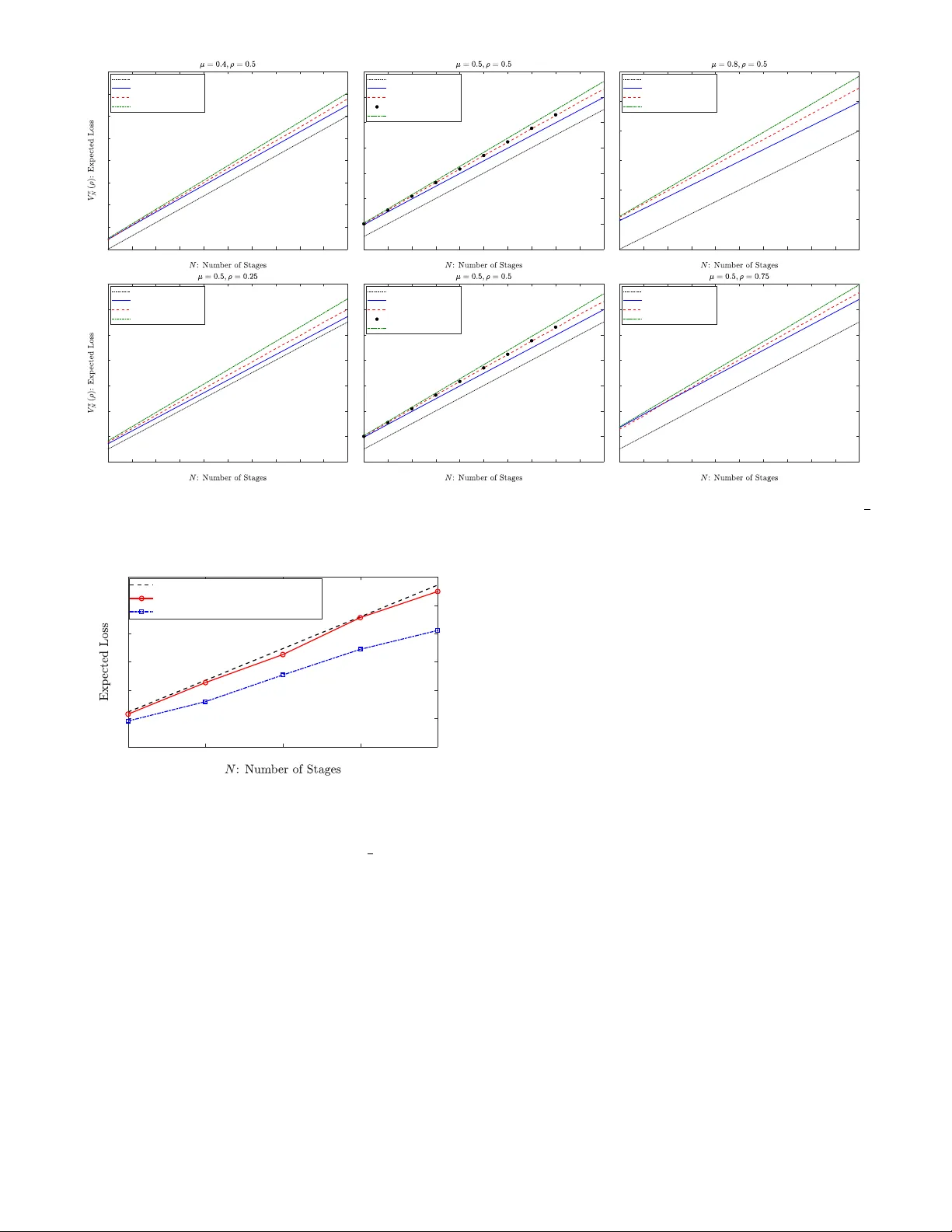
이 논문은 곱셈 가중치(MW) 알고리즘을 기반으로 전문가들의 조언을 종합하여 예측을 수행하는 학습 시스템을 분석합니다. 시스템에는 두 명의 전문가가 있으며, 그중 한 명은 정직하게 일정 확률(μ)로 정확한 예측을 제공하고, 다른 한 명은 시스템이 입는 누적 손실(예측값과 실제값의 절대차 합)을 최대화하려는 악의적 전문가(공격자)입니다. 공격자는 실제 결과를 알고 있으며, 시스템의 예측 규칙(MW 업데이트)도 알고 있다고 가정합니다.
연구는 공격자의 행동 제약에 따라 두 가지 시나리오로 나뉘어 분석됩니다.
1. **오프라인 공격자**: 공격자가 전체 예측 단계(N번)에 대한 모든 결정을 처음에 한꺼번에 내리고 그대로 따라야 하는 설정입니다. 이 경우, 가능한 공격 전략의 수는 2^N으로 매우 많지만, 저자들은 **"항상 거짓 예측을 보고하는"** 단순한 탐욕적 정책이 놀랍게도 최적 정책에 매우 근접함을 증명합니다. 구체적으로, 이 단순 정책으로 인한 시스템 손실은 최적 오프라인 정책으로 인한 손실의 \(1+O(\sqrt{\frac{\ln N}{N}})\) 배 내에 있습니다. 이는 N이 증가함에 따라 단순 공격이 사실상 최적 공격과 동등한 효과를 낸다는 뜻이며, MW 알고리즘이 악의적 내부자에 대해 심각한 취약점을 가질 수 있음을 보여줍니다. 저자들은 최적 오프라인 정책의 구조를 밀접하게 모방하는 정책을 제시하며 이 결과를 뒷받침합니다.
2. **온라인 공격자**: 공격자가 각 예측 단계마다 과거의 모든 정보(상대적 가중치, 전문가들의 예측 기록, 실제 결과)를 확인한 후 그 시점의 예측을 적응적으로 결정할 수 있는 설정입니다. 이 경우 최적 정책은 더 복잡한 구조를 가질 수 있습니다. 저자들은 이 문제를 **동적 프로그래밍(DP)** 으로 정식화합니다. 핵심 통찰은 시스템의 관련 상태를 악의적 전문가의 **상대적 가중치(ρ)** 하나로 축약할 수 있다는 점입니다. 이를 통해 DP의 상태 공간이 단계 수 N에 대해 선형으로 증가하도록 만들고, 최적 온라인 공격 정책을 \(O(N^3)\) 시간에 계산할 수 있는 효율적인 알고리즘을 제시합니다.
논문은 또한 악의적 전문가의 예측 정확도 분포를 모르는 더 약한 공격자 모델에 대해서도 논의하며, 시뮬레이션을 통해 이론적 결과를 검증합니다.
결론적으로, 이 연구는 널리 사용되는 MW 학습 알고리즘이 내부 악의적 행위자에게 얼마나 취약한지를 체계적으로 분석한 것입니다. 오프라인 공격에 대한 근사 최적성 결과는 알고리즘의 근본적 취약성을, 온라인 공격에 대한 효율적 최적 정책 계산법은 실제 공격 시나리오를 평가할 수 있는 도구를 제공합니다. 이는 협업 필터링, 분산 감지, 센서 융합 등 내부 위협이 존재할 수 있는 다양한 기계 학습 응용 분야의 보안과 견고성 평가에 중요한 기여를 합니다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기