연속 프레임을 활용한 컨볼루션 LSTM 잔차망 기반 딥페이크 비디오 탐지
초록
본 논문은 연속된 영상 프레임을 입력으로 받아 시공간 정보를 학습하는 ConvLSTM‑Residual 구조(CLRNet)를 제안하고, Few‑Shot 전이 학습을 통해 다양한 딥페이크 생성 기법에 대한 일반화 성능을 크게 향상시켰다.
상세 분석
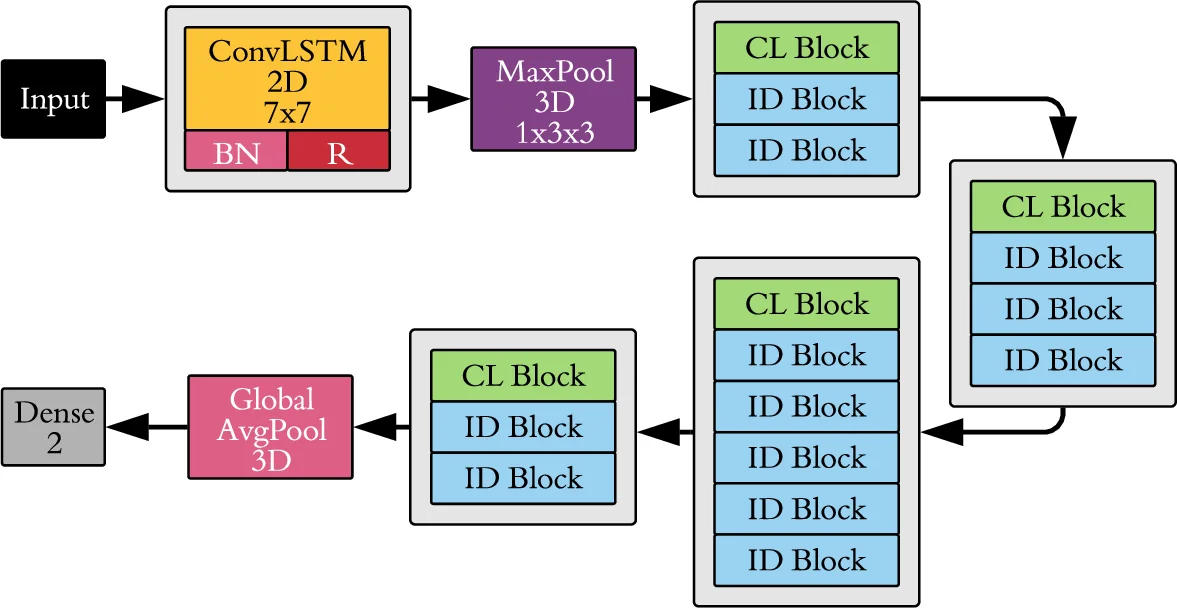
CLRNet은 기존 이미지 단일 프레임 기반 탐지기의 한계를 극복하기 위해 시공간적 특징을 직접 추출할 수 있는 ConvLSTM 셀을 Residual 블록 형태로 쌓은 하이브리드 아키텍처이다. ConvLSTM은 3차원 텐서(시간 × 높이 × 폭)를 그대로 유지하면서 입력‑상태‑출력 간의 컨볼루션 연산을 수행해 공간 정보를 손실 없이 전달한다. 논문에서는 두 종류의 블록을 정의했는데, CL 블록은 ConvLSTM → Dropout → BatchNorm → ReLU 순으로 구성되고, ID 블록은 동일 구조를 갖지만 shortcut 경로가 추가되어 잔차 연결을 구현한다. 이러한 설계는 깊은 네트워크에서도 기울기 소실을 방지하고, 프레임 간 미세한 밝기·대조·얼굴 부위 변형 등 인위적 아티팩트를 효과적으로 포착한다.
데이터 전처리 단계에서는 MTCNN으로 얼굴을 검출·정렬하고 240 × 240 크기로 리사이즈한 뒤, 5프레임씩 16개의 샘플을 추출한다. 밝기, 채널 시프트, 줌, 회전, 수평 플립 등 5가지 데이터 증강을 적용해 일반화 능력을 강화하였다. 학습은 FaceForensics++의 5가지 변조 유형(DeepFake, FaceSwap, Face2Face, NeuralTextures, DeepFakeDetection)에서 각각 750개의 비디오(실제 + 가짜)로 수행하고, 검증·테스트에 125개씩을 사용했다. 전이 학습 전략은 (1) 단일 소스 → 단일 타깃, (2) 다중 소스 → 단일 타깃, (3) 단일 소스 → 다중 타깃의 세 가지를 실험했으며, 특히 Few‑Shot(각 타깃당 10 real + 10 fake) 설정에서 높은 정확도를 기록했다.
실험 결과, CLRNet은 동일 데이터셋 내에서 기존 SOTA(예: Xception, MesoNet, Two‑Stream 등) 대비 평균 3~5%p의 정확도 향상을 보였으며, 전이 학습 시에도 다른 변조 기법에 대한 성능 저하가 최소화되었다. 특히, 프레임 간 차이 영상을 시각화한 결과(그림 1)에서 딥페이크는 실제 영상에 비해 눈에 띄는 불연속성을 보이며, ConvLSTM이 이러한 불연속성을 학습해 높은 판별력을 얻는 것이 확인되었다. 한계점으로는 ConvLSTM의 연산량이 일반 CNN보다 높아 실시간 적용에 비용이 들 수 있고, 5프레임이라는 고정된 시퀀스 길이가 다양한 영상 길이에 최적화되지 않을 가능성이 있다. 또한, 실험에 사용된 데이터가 주로 압축된 얼굴 중심 영상이므로, 배경이 복잡하거나 전체 장면을 포함한 비디오에 대한 일반화 검증이 추가로 필요하다. 향후 연구에서는 경량화된 ConvLSTM 변형, 가변 길이 시퀀스 처리, 그리고 멀티모달(오디오·텍스트) 정보를 결합한 통합 탐지 체계로 확장할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기