스트리밍 데이터 근접 이웃 탐색을 위한 서브선형 메모리 스케치
본 논문은 한 번의 패스만 허용되는 스트리밍 환경에서 데이터셋을 $O(N^{b}\log^{3}N)$ 크기의 스케치로 압축하고, 안정적인 쿼리에 대해 $O(N^{b+1}\log^{3}N)$ 시간 내에 정확한 $v$-최근접 이웃을 복구할 수 있음을 보인다. 핵심은 LSH 기반 추정기, 온라인 커널 밀도 추정, 그리고 압축 센싱을 결합한 RACE‑CMS 구조이며, 구글 플러스 친구 추천 실험을 통해 기존 랜덤 프로젝션 대비 수십 배 이상의 메모리 절…
저자: Benjamin Coleman, Richard G. Baraniuk, Anshumali Shrivastava
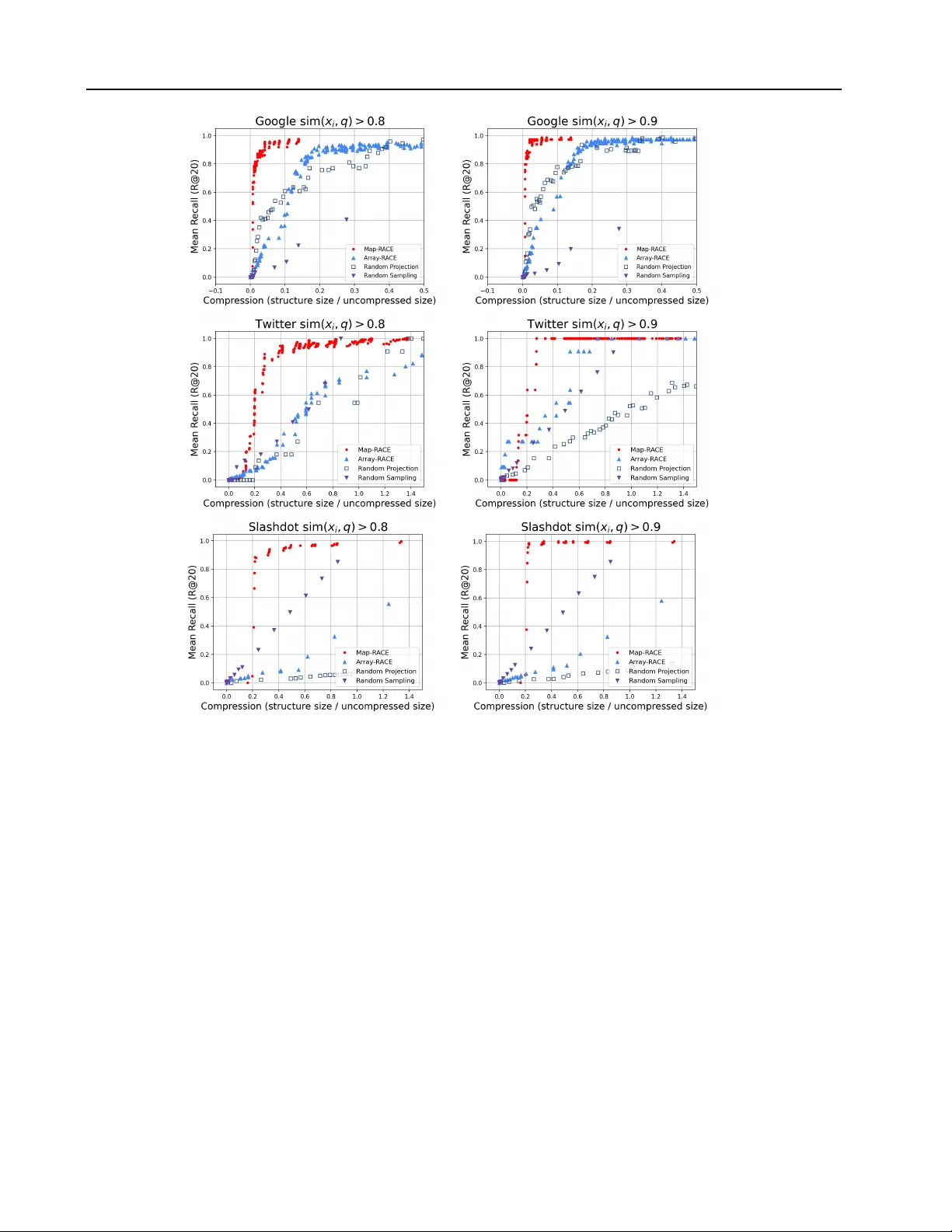
본 논문은 “스트리밍 데이터 근접 이웃 탐색을 위한 서브선형 메모리 스케치”라는 제목 아래, 대규모 데이터 스트림에서 전체 데이터를 저장하지 못하는 상황에서도 정확한 $v$‑nearest neighbor(v‑NN) 검색을 가능하게 하는 새로운 스케치 구조를 제안한다. 문제 정의는 전통적인 ANNS와 달리, 데이터가 한 번만 관찰되는 일회성 스트림이며, 메모리 사용량을 $O(N)$ 수준 이하로 제한해야 한다는 제약을 포함한다. 저자들은 이러한 제약을 극복하기 위해 세 가지 핵심 기술을 결합한다.
1. **LSH‑ 기반 ACE(Repeated Array‑of‑Counts Estimator)**
기존의 Count‑Min Sketch(CMS)는 해시 함수를 무작위로 선택해 카운트를 누적한다. 여기서는 무작위 해시 대신 LSH 함수를 사용해, 동일한 해시 값을 갖는 데이터 포인트가 실제로 높은 유사도를 가질 확률이 높도록 만든다. 이렇게 하면 해시 버킷에 누적된 카운트 $A
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기