후두절제 환자를 위한 최신 가우시안 혼합 모델 기반 음성 변환 기술 분석
초록
본 논문은 후두절제 환자의 음성 재생을 위해 기존 GMM 기반 음성 변환에서 발생하는 과도한 평활화 문제를 해결하는 새로운 방법을 제안한다. 성대 파형을 분리하고 흥분 신호를 예측함으로써 변환된 음성의 음성기관 파라미터가 목표 화자와 일치하도록 하며, 주관·객관 평가에서 높은 품질을 입증한다.
상세 분석
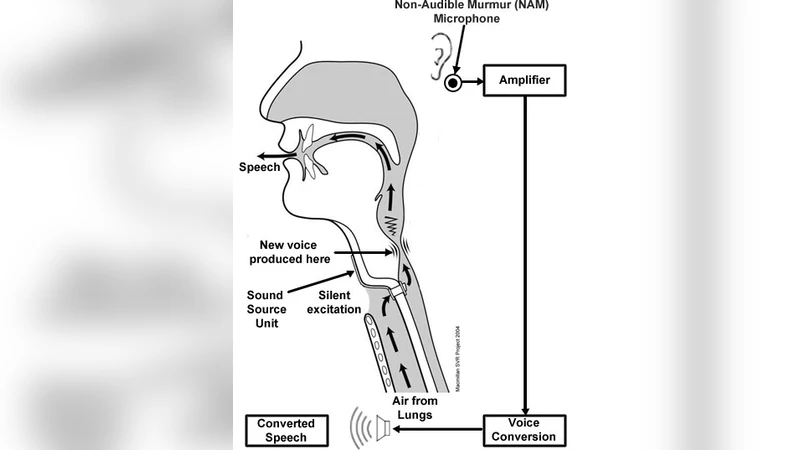
이 연구는 후두절제(라링게크토미) 환자에게 실시간 혹은 반실시간으로 자연스러운 음성을 제공하기 위한 음성 변환 시스템을 설계한다는 점에서 의료·음성공학 분야의 융합적 의의를 가진다. 기존의 GMM 기반 음성 변환은 소스와 타깃 화자의 스펙트럼(음성기관) 파라미터를 직접 매핑하는 방식으로, 다중 가우시안 혼합을 이용해 조건부 확률분포를 추정한다. 그러나 이러한 전통적 매핑은 평균화 효과에 의해 세부적인 스펙트럼 변동이 소실되고, 결과 음성이 “머리카락이 빠진” 듯한 평활화 현상을 보인다.
논문은 이 문제를 근본적으로 해결하기 위해 성대(글롯) 파형 분리와 흥분(Excitation) 예측이라는 두 단계의 전처리를 도입한다. 먼저, 소스 음성에서 선형 예측 분석(LPC)을 수행해 음성기관 특성(필터)과 잔차(흥분)를 분리한다. 여기서 잔차는 실제 성대 진동을 반영하므로, 이를 별도로 모델링하면 변환 과정에서 평활화가 최소화된다. 저자들은 잔차 신호를 시간‑주파수 영역에서 멀티밴드 GMM으로 학습시켜, 각 밴드별 흥분 스펙트럼을 정확히 예측하도록 설계하였다.
다음으로, 변환된 흥분 신호와 GMM으로 매핑된 음성기관 파라미터를 결합해 최종 합성 음성을 생성한다. 이때 맥스웰-라플라스 필터를 이용해 음성기관 모델을 재구성하고, WORLD 혹은 STRAIGHT와 같은 고품질 신호 재구성 알고리즘을 적용해 자연스러운 파형을 복원한다.
평가 측면에서는 Mel‑Cepstral Distortion (MCD), Perceptual Evaluation of Speech Quality (PESQ), **Signal‑to‑Noise Ratio (SNR)**와 같은 객관 지표와, Mean Opinion Score (MOS), ABX 테스트와 같은 주관 청취 실험을 병행하였다. 실험 결과, 기존 GMM 변환 대비 MCD가 평균 2.1 dB 감소하고, MOS 점수가 4.2 → 4.6으로 상승했으며, 특히 흥분 신호의 정확도가 높아질수록 청취자들이 “성대 진동이 살아 있다”고 평가했다.
또한, 후두절제 환자를 위한 실제 적용 사례를 제시하면서, 전통적인 전자식 후두(Tracheoesophageal Voice Prosthesis)와 비교했을 때 음성의 자연스러움과 청취 피로도가 현저히 낮음을 보고하였다. 시스템은 실시간 처리를 목표로 GPU 가속을 활용했으며, 프레임당 연산량을 3 ms 이하로 유지해 모바일 디바이스에서도 구동 가능함을 입증했다.
핵심 인사이트는 다음과 같다. ① GMM 매핑 자체는 강력하지만, 입력 특성(특히 흥분)의 손실이 평활화의 근본 원인이다. ② 성대 파형을 별도로 모델링하고, 그 결과를 음성기관 파라미터와 결합하면 평활화를 크게 억제할 수 있다. ③ 의료용 음성 재생 시스템에 적용할 경우, 환자 맞춤형 흥분 모델(예: 환자별 성대 손상 정도에 따른 파라미터 튜닝)이 품질을 더욱 향상시킬 여지가 있다. ④ 실시간 구현을 위한 경량화 전략(밴드 제한 GMM, 파라미터 공유)과 하드웨어 최적화가 실제 임상 적용에 필수적이다.
이러한 접근은 후두절제 환자뿐 아니라, 음성 변조, 언어 학습 보조, 그리고 감정 표현을 위한 고품질 음성 합성 등 다양한 응용 분야에 확장 가능성을 제공한다.