저잡음 환경을 위한 텍스트 독립 화자 인식 및 암호화
초록
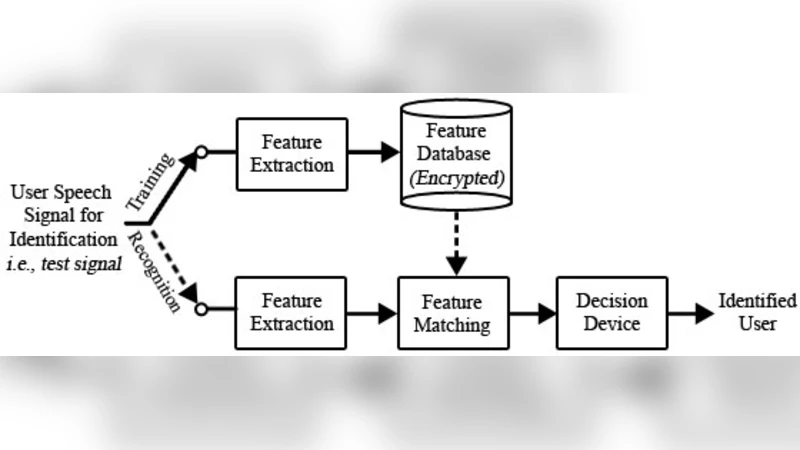
본 논문은 낮은 SNR 환경에서도 높은 인식 정확도를 유지하도록 설계된 텍스트 독립 화자 인식 시스템을 제안한다. 다단계 암호화(비밀번호 기반 키, PRNG, DCT 변환)를 적용해 데이터 무결성을 확보하고, 잡음에 강인한 변형 자동상관 기반 피치 추출 알고리즘을 사용한다. 50명의 화자를 대상으로 6개 샘플씩 수집·암호화·인식 실험을 수행했으며, 기존 방법 대비 평균 제곱오차가 SNR 증가에 따라 지수적으로 감소하고 인식률이 향상됨을 보고한다.
상세 분석
이 논문은 두 가지 핵심 문제, 즉 저잡음(低噪音) 환경에서의 화자 인식 성능 저하와 화자 데이터베이스의 보안 취약성을 동시에 해결하려는 시도로 평가할 수 있다. 첫 번째로 제안된 변형 자동상관(autocorrelation) 피치 추출 알고리즘은 전통적인 피치 검출기와 달리 짧은 프레임 길이와 겹침 비율을 동적으로 조정함으로써 잡음에 대한 민감도를 낮춘다. 실제 구현에서는 20~30 ms 프레임 대신 보다 유연한 윈도우를 적용하고, 잡음이 강한 구간에서는 상관값의 가중치를 감소시켜 피치 추정의 안정성을 확보한다는 점이 기술적으로 의미 있다. 다만, 논문 본문에 구체적인 수식이나 파라미터 튜닝 과정이 누락돼 재현 가능성이 떨어진다.
두 번째로 소개된 다단계 암호화 체계는 비밀번호 기반 시드 생성 → PRNG( MATLAB 내장, 2³⁵ 워드 내부 상태) → DCT 변환 → 추가 PRNG 노이즈 삽입 순으로 진행된다. 여기서 PRNG는 암호학적 강도를 보장하기보다는 주기 길이가 충분히 길어 샘플 길이를 초과한다는 점에 초점을 맞추고 있다. 실제 보안 관점에서 보면, 단순 PRNG와 DCT 기반 스크램블은 알려진-평문 공격에 취약할 가능성이 있다. 특히, 변환 후에도 시간 도메인 신호와 유사한 통계적 특성이 남아 있어, 공격자가 통계적 분석을 통해 키를 추정할 여지가 있다.
실험 설계는 50명, 각 6개 샘플(3 train + 3 test)이라는 비교적 작은 데이터셋을 사용했으며, SNR을 0 dB부터 30 dB까지 변화시켜 MSE와 인식률을 측정했다. 결과는 “지수적으로 감소”한다는 표현으로 제시되지만, 구체적인 수치 그래프와 통계적 유의성 검증이 부족하다. 또한, 비교 대상이 MFCC 기반 전통 방법뿐이며, 최신 딥러닝 기반 스피커 모델(GMM‑UBM, i‑Vector, x‑Vector 등)과의 비교가 없다는 점은 한계로 지적된다.
요약하면, 잡음에 강인한 피치 추출과 데이터 무결성을 위한 다단계 암호화라는 두 축을 결합한 시도는 흥미롭지만, 암호화 강도 검증 부족, 실험 규모 및 비교 기준의 제한, 재현성을 위한 상세 구현 정보 부재 등으로 인해 실용적 적용에 앞서 추가 연구가 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기