양자 최적화 알고리즘으로 게임 이론의 난제를 풀다
초록
본 연구는 로젠탈의 이산형 혼잡 게임에서 최적의 내쉬 균형과 사회적 최적 해를 찾는 문제를 양자 근사 최적화 알고리즘(QAOA)의 변형인 양자 교대 연산자 접근법을 사용해 해결 가능함을 입증했습니다. 게임의 전략과 제약 조건을 이징 모델 형태로 정형화하고, 소프트 제약(페널티 함수) 및 하드 제약(패리티 믹서) 두 가지 방식으로 양자 회로에 구현하여 시뮬레이션을 수행하였습니다. 이는 양자 컴퓨팅이 게임 이론과 기계 학습(예: GAN 훈련)의 복잡한 최적화 문제에 적용될 수 있는 초기 실증 사례를 제시합니다.
상세 분석
이 논문의 핵심 기술적 기여는 복잡한 게임 이론 문제를 양자 컴퓨터가 처리 가능한 최적화 문제로 정교하게 정형화한 데 있습니다. 구체적인 분석은 다음과 같습니다.
-
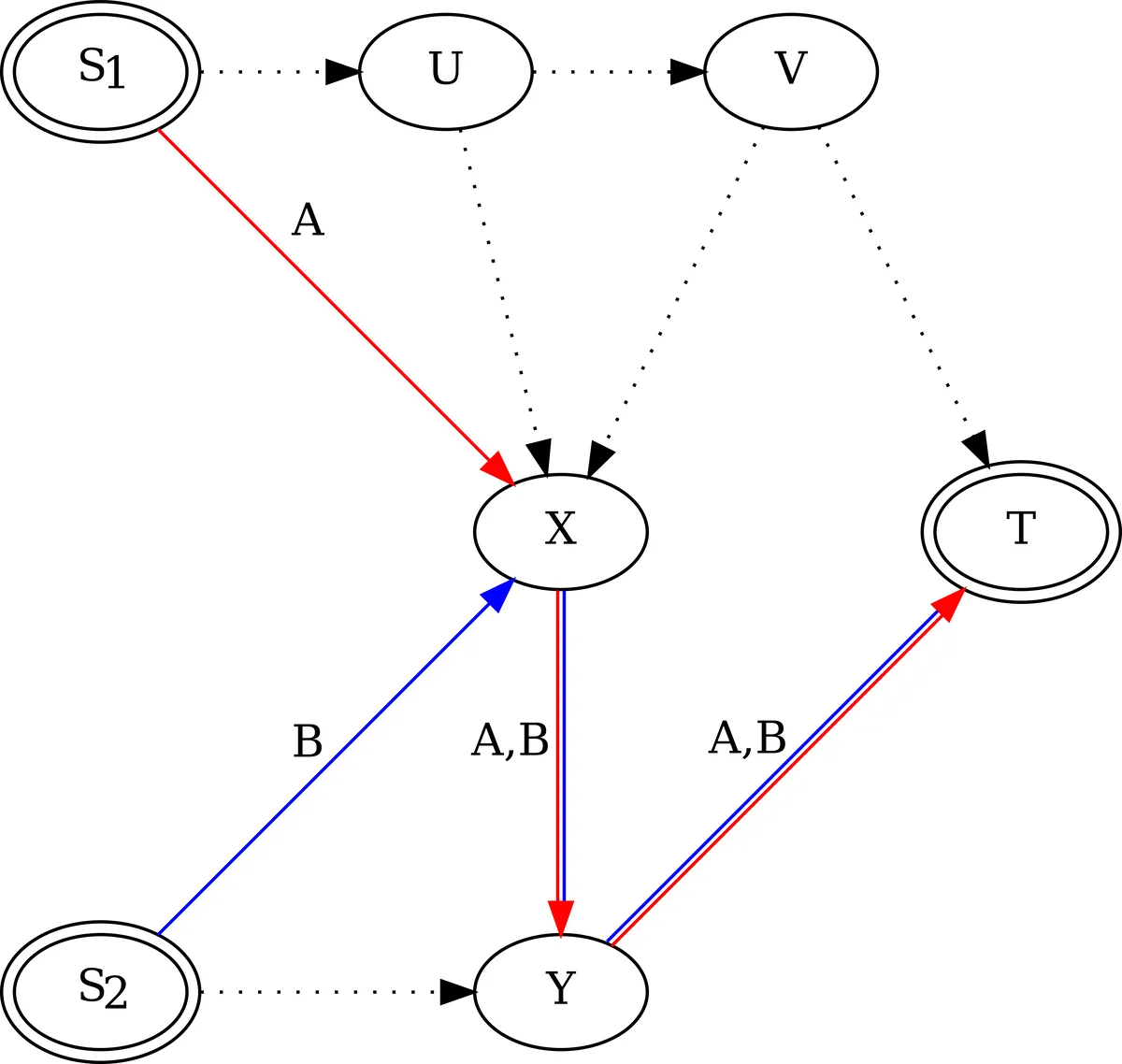
문제 정형화의 혁신성: 연구팀은 두 명의 플레이어가 각자 주어진 경로 중 하나를 선택하여 이동 시간(지연)을 최소화하는 비대칭 네트워크 혼잡 게임을 설정했습니다. 핵심은 내쉬 균형과 사회적 최적 해를 찾는 문제를 ‘퍼텐셜 함수’를 이용한 단일 목적 함수 최소화 문제로 변환한 것입니다. Eq.(15)에 제시된 최적 내쉬 균형을 위한 퍼텐셜 함수는 각 자원의 혼잡도에 따른 누적 지연을 합산하며, 이는 한 플레이어의 전략 변경이 야기하는 퍼텐셜 함수 값의 변화가 해당 플레이어의 효용 변화와 정확히 일치하도록 설계되어 게임의 균형 조건을 만족시킵니다.
-
양자 알고리즘의 이중 적용: 문제를 양자 회로에 매핑하기 위해 두 가지 QAOA 변형을 비교 적용했습니다.
- 소프트 제약 QAOA: 기존의 표준 QAOA 방식을 따르며, 각 플레이어가 정확히 하나의 경로를 선택해야 한다는 제약(Eq.(21))을 페널티 항(Eq.(27))으로 목적 함수에 추가합니다. 이 경우 믹싱 연산자
B는 모든 가능한 상태를 탐색하는 단순한 형태(Eq.(7))를 사용합니다. - 하드 제약 QAOA (양자 교대 연산자 접근법): 제약 조건을 만족하는 상태의 공간(가능해 공간)으로 탐색을 제한하는 방식을 채택합니다. 이를 위해 ‘원-핫(one-hot)’ 인코딩을 구현하는 패리티 믹서(Eq.(8))를 설계하여 사용합니다. 이 믹서는 인접한 큐비트들 간의 XY 상호작용을 통해, 각 플레이어에 해당하는 큐비트 블록 내에서 정확히 하나의 큐비트만 |1> 상태가 되도록 유지합니다.
- 소프트 제약 QAOA: 기존의 표준 QAOA 방식을 따르며, 각 플레이어가 정확히 하나의 경로를 선택해야 한다는 제약(Eq.(21))을 페널티 항(Eq.(27))으로 목적 함수에 추가합니다. 이 경우 믹싱 연산자
-
실험 및 통찰: 소규모 2-플레이어 게임에 대한 이상적인 양자 시뮬레이터 실험을 통해 두 방식의 실행 가능성을 확인했습니다. 논문은 하드 제약 방식을 사용한 양자 교대 연산자 접근법이 제약 조건을 정확히 준수하는 탐색 공간을 정의함으로써, 불필요한 불량 해 탐색을 줄이고 알고리즘 성능을 잠재적으로 향상시킬 수 있음을 시사합니다. 또한, 리소스 지연 함수를 선형으로 단순화했음에도 문제의 복잡도(최적 내쉬 균형 찾기는 NP-하드)가 유지된다는 점을 지적하며, 양자 알고리즘이 본질적으로 어려운 문제에 대한 접근법이 될 수 있음을 강조합니다.
-
향후 연구 방향성: 이 작업은 GAN 훈련의 근본적인 난제인 최적 내쉬 균형 수렴 실패 및 모드 붕괴 문제를 양자 최적화 관점에서 해결할 수 있는 이론적 토대를 마련했습니다. 양자-고전 하이브리드 방식으로 복잡한 게임의 균형을 찾는 방법은 금융 리스크 모델링, 합성 데이터 생성, 교통 흐름 최적화 등 다양한 분야에 적용 가능성을 열어줍니다.
댓글 및 학술 토론
Loading comments...
의견 남기기