베이지안 신경망을 활용한 지속 학습 프레임워크
본 논문은 베이지안 신경망(BNN) 위에 가우시안 혼합 분포를 도입해 작업별 파라미터를 관리함으로써, 과거 데이터를 재사용하지 않고도 새로운 과제에 적응하면서 파라미터 폭발을 억제하는 지속 학습 방법(CBLN)을 제안한다. EM 기반 가우시안 혼합 모델을 통해 중복된 컴포넌트를 제거하고, 테스트 시 에피스테믹 불확실성을 최소화하는 컴포넌트를 선택해 예측한다. MNIST와 UCR 시계열 데이터에서 기존 최첨단 기법 대비catastrophic fo…
저자: HongLin Li, Payam Barnaghi, Shirin Enshaeifar
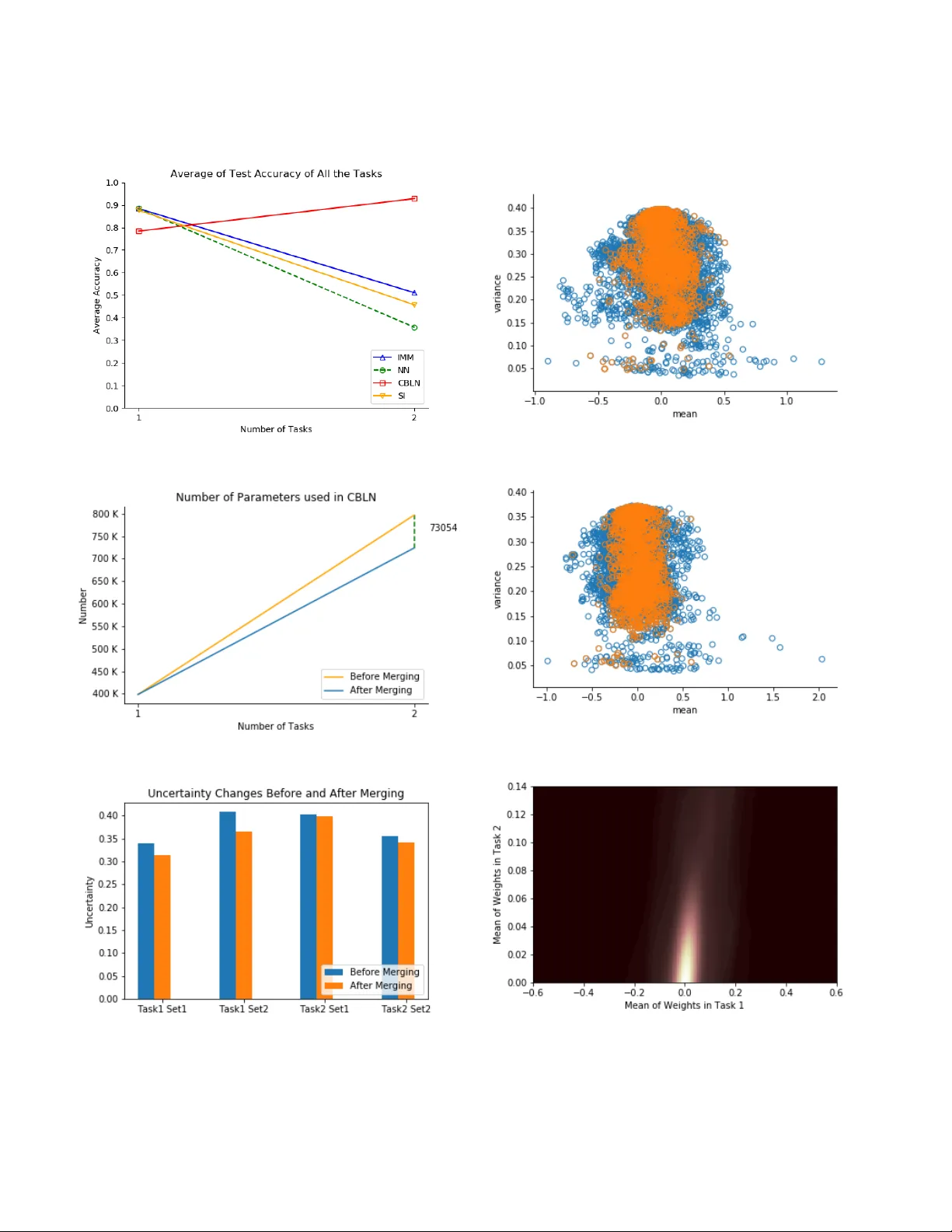
본 논문은 지속 학습(continual learning) 분야에서 발생하는 대표적인 문제인 재앙적 망각(catastrophic forgetting)을 베이지안 신경망(Bayesian Neural Network, BNN) 기반의 새로운 프레임워크인 Continual Bayesian Learning Networks(CBLN)으로 해결하고자 한다. 기존 접근법은 크게 정규화 기반(EWC, SI 등), 메모리 리플레이(생성 모델을 이용한 pseudo‑rehearsal), 동적 네트워크(새로운 뉴런/모델 추가)로 구분되며, 각각 파라미터 폭발, 메모리 요구량, 작업 라벨 의존성 등의 한계를 가지고 있다. CBLN은 이러한 한계를 동시에 극복하기 위해 다음과 같은 핵심 아이디어를 제시한다.
1. **베이지안 가중치 모델링**: 각 작업마다 BNN을 학습하고, 가중치를 다변량 가우시안(대각 공분산)으로 추정한다. 이렇게 하면 작업 간 가중치 분포가 독립적이라고 가정할 수 있어, 사후분포를 단순히 가우시안 혼합 형태로 표현한다.
2. **가우시안 혼합 모델을 통한 파라미터 압축**: K개의 작업을 학습하면 K개의 가우시안 컴포넌트가 생기지만, EM 기반 GMM을 이용해 이들을 클러스터링한다. 평균이 유사한 컴포넌트는 하나로 병합하고, 혼합 비중 α가 사전에 정의한 임계값(t = ½K) 이하인 컴포넌트는 제거한다. 결과적으로 최종 사후분포는 n ≤ K개의 가우시안 컴포넌트로 압축된다. 이는 파라미터 수가 작업 수에 비례해 기하급수적으로 증가하는 것을 방지한다.
3. **불확실성 기반 테스트 선택**: 테스트 시에는 각 가우시안 컴포넌트에서 Monte‑Carlo 샘플을 추출해 예측 분포를 만든 뒤, 에피스테믹 불확실성(예측 점수의 분산) 혹은 엔트로피, MUMMI 등 다양한 불확실성 지표를 계산한다. 가장 낮은 불확실성을 보이는 컴포넌트를 선택해 최종 예측을 수행한다. 이 과정에서 별도의 작업 라벨을 제공할 필요가 없으며, 모델 자체가 “어떤 작업에 가장 적합한 파라미터”를 자동으로 판단한다.
4. **실험 설계 및 결과**: MNIST(이미지 분류)와 UCR Two‑Patterns(시계열 분류) 두 데이터셋을 사용해 10개 및 4개의 작업을 순차적으로 학습하였다. 각 작업마다 이전 데이터에 접근하지 않고, 새로운 작업이 주어졌을 때만 학습을 진행하였다. 비교 대상은 일반 신경망(NN), Incremental Moment Matching(IMM), Synaptic Intelligence(SI) 등이다. CBLN은 평균 정확도와 파라미터 효율성 모두에서 기존 방법들을 앞섰으며, 특히 작업 수가 늘어날수록 파라미터 증가율이 현저히 낮아 재앙적 망각을 효과적으로 억제함을 보였다.
5. **한계와 향후 과제**: 현재 CBLN은 가중치 공분산을 대각선으로 제한함으로써 계산량을 줄였지만, 복잡한 상관관계를 포착하지 못한다는 점이 있다. 또한 EM 초기화와 혼합 비중 임계값에 대한 민감도가 존재한다. 향후 연구에서는 비대각 공분산을 허용하는 베이지안 추정, 더 정교한 불확실성 측정(예: MUMMI와 엔트로피의 결합), 그리고 대규모 비정형 데이터에 대한 확장성을 검증할 필요가 있다.
요약하면, CBLN은 베이지안 신경망 위에 가우시안 혼합 모델을 적용해 작업별 파라미터를 효율적으로 관리하고, 불확실성 기반 선택 메커니즘을 통해 테스트 단계에서 자동으로 적절한 파라미터 집합을 선택함으로써, 재앙적 망각을 최소화하면서도 파라미터 폭발을 방지하는 지속 학습 프레임워크를 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기