RoBERTa와 CRF, 전이학습을 활용한 선전 기술 탐지 시스템
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
본 논문은 SemEval‑2020 Task 11의 두 하위 과제(선전 구간 식별과 기술 분류)를 해결하기 위해 RoBERTa 기반 모델에 선형 체인 CRF와 전이학습, 다양한 후처리 기법을 결합한 앙상블 시스템을 제안한다. 실험 결과, 구간 식별에서는 F1 0.491로 3위, 기술 분류에서는 F1 0.62로 2위를 기록하였다.
상세 분석
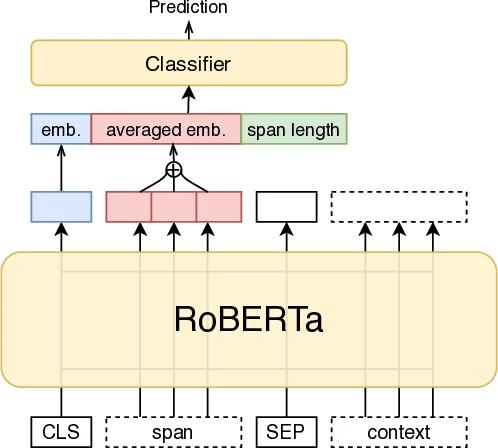
이 연구는 최신 사전학습 언어 모델인 RoBERTa‑large를 핵심 인코더로 사용하면서, 두 가지 주요 기술적 확장을 도입한다. 첫째, 구간 식별(SI)에서는 토큰‑레벨 BIO 라벨링을 수행한 뒤, RoBERTa가 출력한 로짓을 선형 체인 CRF에 전달한다. CRF는 라벨 전이 제약을 학습해 “O → I‑PROP”와 같은 불가능한 전이를 억제함으로써 라벨 일관성을 크게 향상시킨다. 특히, BPE 토큰 중 단어 시작 토큰만을 CRF에 입력함으로써 토큰화 오류를 최소화하였다. 둘째, 기술 분류(TC)에서는 다중 라벨 문제를 단일 라벨 형태로 변환해 학습하고, 테스트 시 n‑best 예측을 활용해 다중 라벨을 복원한다. 여기서 핵심은 (1)
댓글 및 학술 토론
Loading comments...
의견 남기기