시퀀스‑투‑시퀀스 모델을 활용한 코드 자동 교정 및 피라미드 인코더 효율성 연구
초록
본 논문은 Juliet Test Suite와 ITC 벤치마크를 활용해 다양한 seq2seq 모델을 코드 오류 교정에 적용하고, 피라미드 인코더를 도입해 연산·메모리 효율을 크게 향상시키면서도 기존 모델과 동등한 복구율을 유지함을 보였다. C/C++ 코드에서는 75 %의 복구율, Java에서는 56 %를 달성했으며, 작은 데이터셋에 대한 전이 학습 역시 성공적으로 수행하였다.
상세 분석
본 연구는 프로그래밍 언어 교정(PLC) 분야에 seq2seq 모델을 적용한 최초 사례 중 하나로, 기존의 규칙 기반 접근법과 달리 데이터‑드리븐 방식을 채택하였다. 저자들은 두 가지 주요 모델군, 즉 다층 GRU 기반 RNN과 Transformer 구조를 선택했으며, 각각에 피라미드 인코더(Pyramid Encoder)를 삽입해 입력 시퀀스 길이를 단계적으로 절반으로 축소하였다. 피라미드 인코더는 각 레이어에서 인접한 두 hidden state를 tanh‑활성화와 선형 변환을 통해 결합함으로써, 정보 손실을 최소화하면서도 연산량을 크게 감소시킨다. 이는 특히 코드의 평균 길이가 수백 토큰에 달하는 PLC 작업에서 메모리 사용량을 최대 600 % 절감하고, 처리 속도를 50 %~130 % 가속화하는 효과를 보였다.
실험에서는 Juliet Test Suite(C/C++ v1.2, Java v1.3)에서 전처리 과정을 거쳐 각각 31,082개와 23,015개의 ‘잘못된‑수정된’ 코드 쌍을 확보하였다. 변수명 재명명과 죽은 코드 제거, 조건문 분기 정규화 등을 통해 어휘 집합을 약 1,000개 수준으로 축소함으로써 OOV 문제를 완화했다. 모델 학습은 GTX 1080 Ti GPU에서 수행되었으며, 평가 지표는 1‑candidate와 5‑candidate 복구율(beam width = 5)로 정의하였다.
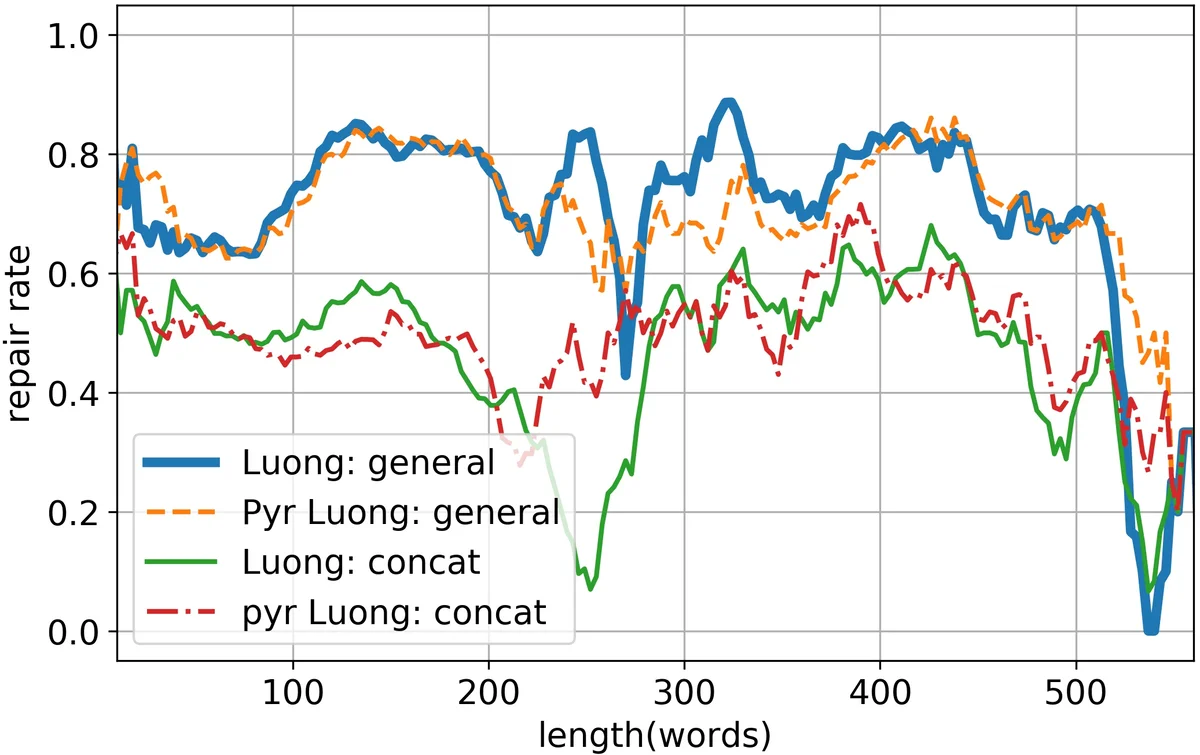
표 1·2의 결과는 피라미드 인코더가 대부분의 어텐션 메커니즘(Bahdanau, Luong‑dot, Luong‑general, Luong‑concat, Transformer)과 결합했을 때 복구율 저하가 거의 없음을 보여준다. 다만 Luong‑local 어텐션은 피라미드 구조와의 호환성이 낮아 성능이 크게 떨어졌다. 이는 피라미드 인코더가 출력 시퀀스를 ‘거칠게’ 요약함에 따라 지역적 어텐션이 정확한 중심을 잡기 어려워진 결과로 해석된다.
전이 학습 실험에서는 Juliet 데이터셋으로 사전 학습한 모델을 ITC(685개 코드) 벤치마크에 미세조정했으며, 오류 유형 분류 정확도가 기존 작은 데이터셋만을 사용한 경우보다 현저히 향상되었다. 이는 대규모 자동 생성 코드 데이터가 실제 현업 코드에 대한 일반화 능력을 제공한다는 중요한 시사점을 제공한다.
전체적으로 본 논문은 (1) seq2seq 기반 PLC의 가능성을 실증, (2) 피라미드 인코더를 통한 효율성 개선, (3) 대규모 데이터 사전 학습을 통한 소규모 데이터셋 활용 방안 제시라는 세 축을 성공적으로 결합하였다. 향후 연구에서는 피라미드 인코더와 최신 Transformer 변형(예: Longformer, Performer) 간의 시너지 효과를 탐색하고, 실제 개발 환경에서 실시간 코드 자동 교정 시스템으로 확장하는 것이 과제로 남는다.
댓글 및 학술 토론
Loading comments...
의견 남기기