시각과 언어의 결합으로 광고 아이디어를 추천하는 AI 시스템
초록
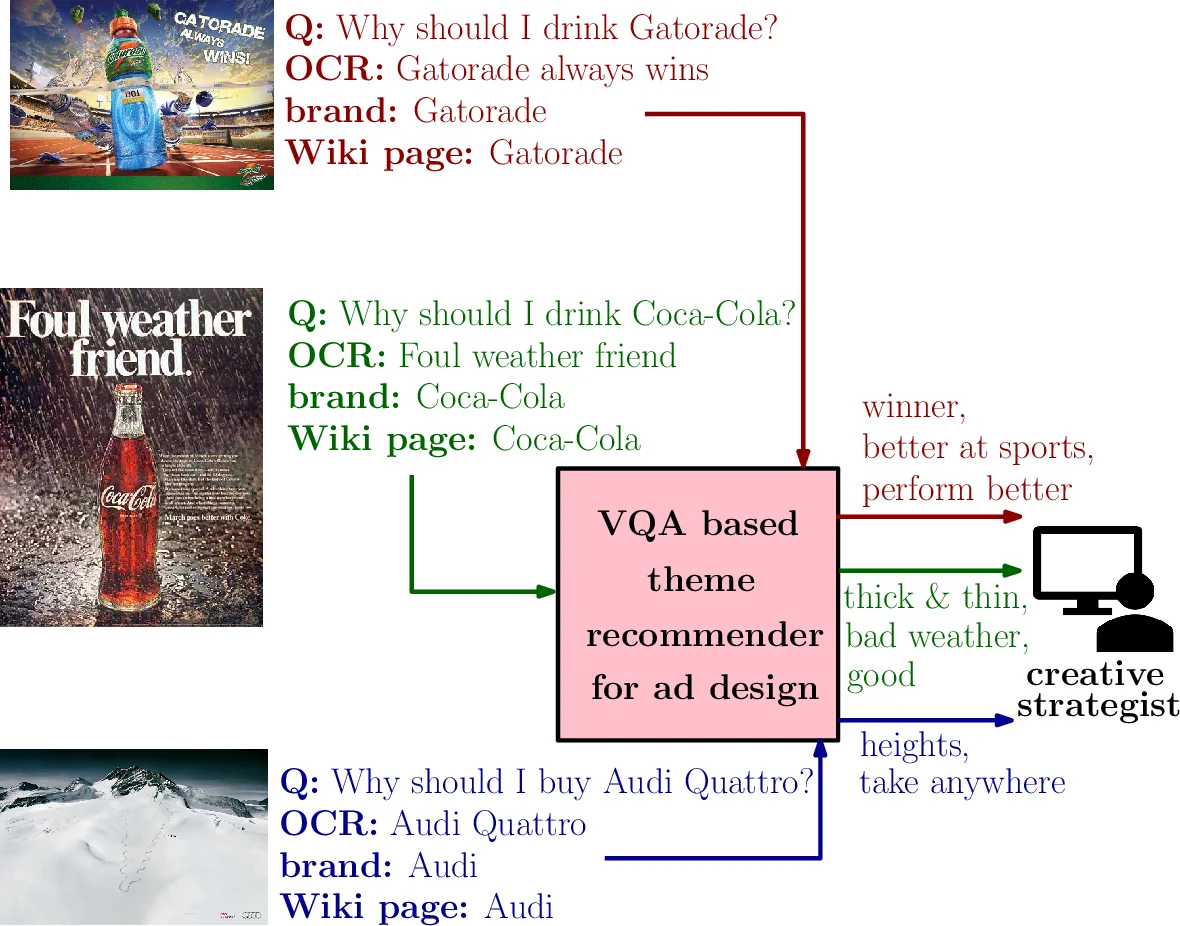
이 연구는 온라인 광고의 피로도를 줄이고 새 캠페인에 활용할 테마(핵심 문구)를 자동으로 추천하는 시스템을 제안합니다. 과거 광고의 이미지, 광고 내 텍스트, 브랜드 위키피디아 정보를 종합하여 학습한 시각-언어 결합 표현 기반의 VQA 모델을 통해 광고 기획자에게 창의적인 테마 후보를 제안합니다. 실험 결과, 텍스트나 이미지 단독 사용보다 다중 모달 정보를 활용한 접근법이 훨씬 우수한 성능을 보였습니다.
상세 분석
본 논문의 기술적 핵심은 광고 크리에이티브 설계라는 실용적 문제를 ‘시각적 질의응답(VQA)’ 작업으로 재정의하고, 트랜스포머 기반의 크로스모달리티 인코더를 활용해 해결한 점에 있습니다. 기존 VQA 연구와의 차별점은 질문에 답변하는 대상이 단순 이미지 내용이 아닌, 광고가 유발하려는 감정과 테마라는 점입니다.
시스템은 세 가지 입력을 처리합니다: 1) 광고 이미지(Faster R-CNN으로 추출한 객체 ROI 특징), 2) 텍스트(광고 내 OCR 텍스트, 광고 관련 질문, 브랜드 위키피디아 문서), 3) 공간 정보(객체 바운딩 박스). 텍스트와 이미지 특징은 각각 임베딩 레이어를 거친 후, LXMERT 아키텍처를 참조한 크로스모달리티 인코더에 입력됩니다. 이 인코더는 언어 인코더, 객체-관계 인코더, 그리고 두 모달리티 간 상호작용을 학습하는 교차 주의력 계층으로 구성되어, 최종적으로 시각과 언어 정보가 융합된 하나의 임베딩 벡터를 생성합니다.
연구자는 이 문제를 해결하기 위해 ‘분류’와 ‘순위 지정’ 두 가지 프레임워크를 실험했습니다. 분류 방식은 미리 정의된 핵심 문구 어휘집에 대해 소프트맥스 확률을 계산하는 반면, 순위 지정 방식(DRMM 모델 활용)은 주어진 입력에 대해 핵심 문구들의 관련성을 순서대로 배열합니다. 공개 데이터셋을 이용한 실험에서 크로스모달리티 표현을 사용한 접근법은 이미지나 텍스트 단독 표현을 사용하는 방법보다 분류 정확도와 순위 지정 정밀도/재현율에서 현저히 우수한 성능을 입증했습니다. 이는 광고 테마 추천과 같은 복잡한 인지 작업에는 이미지의 시각적 콘텍스트와 브랜드에 대한 배경 지식(위키피디아) 및 광고 문구를 통합적으로 이해하는 것이 필수적임을 시사합니다.
댓글 및 학술 토론
Loading comments...
의견 남기기