COVID 19 논문 자동 군집화 및 시각화 도구
초록
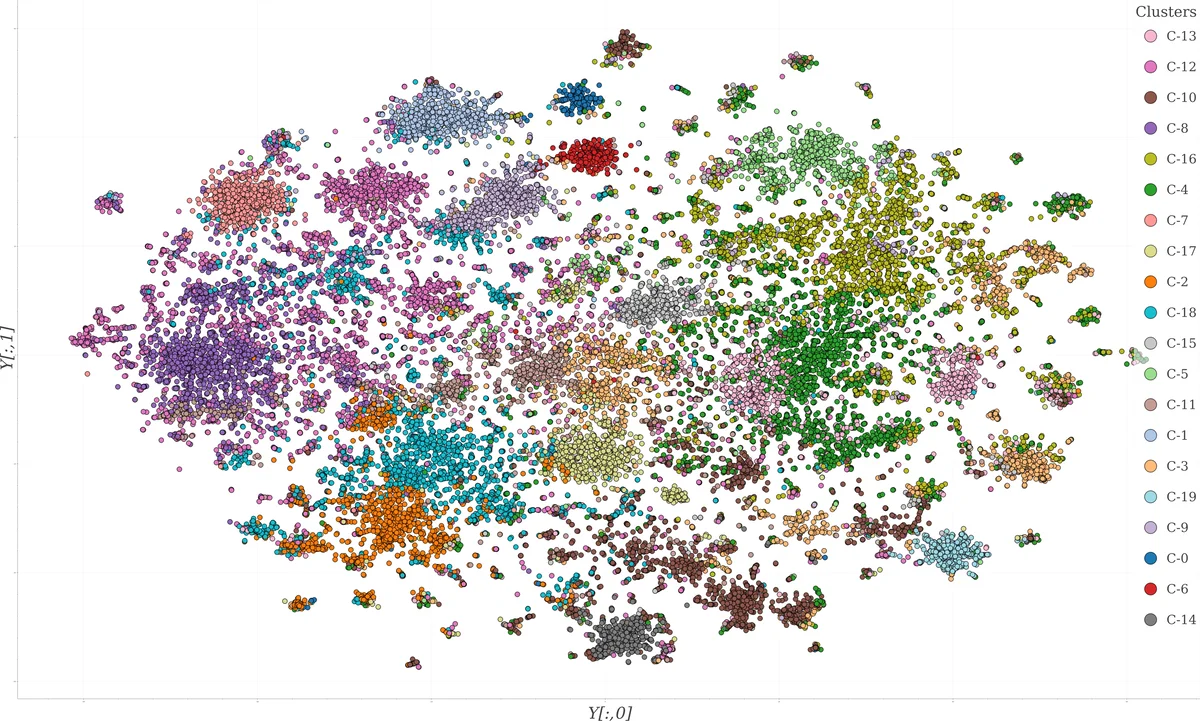
본 논문은 CORD‑19 데이터셋을 대상으로 TF‑IDF 기반 벡터화 후 PCA와 k‑means, t‑SNE를 결합해 논문을 주제별로 군집화하고 2차원 인터랙티브 플롯으로 시각화하는 방법을 제시한다. 5만여 편의 논문을 20개의 클러스터로 구분해 연구자들이 관련 문헌을 빠르게 탐색하도록 지원한다.
상세 분석
이 연구는 급증하는 COVID‑19 관련 문헌을 효율적으로 탐색하기 위한 파이프라인을 구현하였다. 먼저 SciSpacy를 이용해 본문 텍스트를 정제하고, 불용어·구두점·대소문자를 제거한 뒤 TF‑IDF로 2¹² 차원의 희소 벡터(X₁)를 생성한다. 차원 저주를 완화하기 위해 PCA를 적용해 95 % 분산을 유지하는 고차원 임베딩(X₂)을 얻는다. X₂에 k‑means를 적용해 클러스터 라벨을 생성하고, 최적 k값은 왜곡(distortion) 곡선의 변곡점을 이용해 k≈20으로 설정하였다. 시각화 단계에서는 원본 TF‑IDF 행렬 X₁을 t‑SNE에 투입해 2차원 좌표(Y)를 도출하고, 앞서 얻은 라벨을 색상으로 매핑한다. 이렇게 만든 인터랙티브 플롯은 웹 기반으로 구현돼 논문 초록·링크에 즉시 접근할 수 있다.
핵심적인 기술적 통찰은 다음과 같다. 첫째, PCA와 k‑means를 결합해 고차원 공간에서 군집 구조를 파악하고, t‑SNE를 별도로 적용해 시각적 가시성을 확보함으로써 차원 축소와 군집화의 상호 보완성을 극대화했다. 둘째, 2¹² 차원 제한은 메모리 사용량을 현실적인 수준으로 유지하면서도 주요 토픽을 충분히 포착하도록 설계되었다. 셋째, 변곡점 기반 k 선택은 과도한 클러스터 분할을 방지하고, 인간이 직관적으로 해석 가능한 군집 수를 제공한다.
한계점으로는 (1) k‑means가 구형 클러스터 가정을 갖고 있어 비구형 토픽 구조를 완전히 반영하지 못한다는 점, (2) t‑SNE가 매 실행마다 결과가 달라지는 비결정론적 특성으로 인해 재현성이 낮을 수 있다는 점, (3) 영어 논문만을 대상으로 했기 때문에 비영어권 연구가 배제된다는 점을 들 수 있다. 향후 연구에서는 DBSCAN·HDBSCAN 같은 밀도 기반 군집화와 UMAP 같은 대안 차원 축소 기법을 도입해 구조적 다양성을 보완하고, 다국어 전처리 파이프라인을 구축해 포괄성을 확대할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기