일반 네트워크를 위한 계단식 코딩 분산 컴퓨팅의 조합 설계
초록
본 논문은 계단식 코딩 분산 컴퓨팅(CDC)에서 입력 파일과 Reduce 함수의 할당을 동시에 최적화하는 새로운 조합 설계(하이퍼큐보이드)를 제안한다. 제안 방식은 이질적인 저장·연산 능력을 가진 노드들을 지원하며, 기존 동질 네트워크 설계보다 적은 파일·함수 수와 낮은 통신 부하를 달성한다. 또한, 입력·함수 할당을 고정했을 때 정보이론적 하한과 비교해 상수 배 이내의 최적성을 보인다.
상세 분석
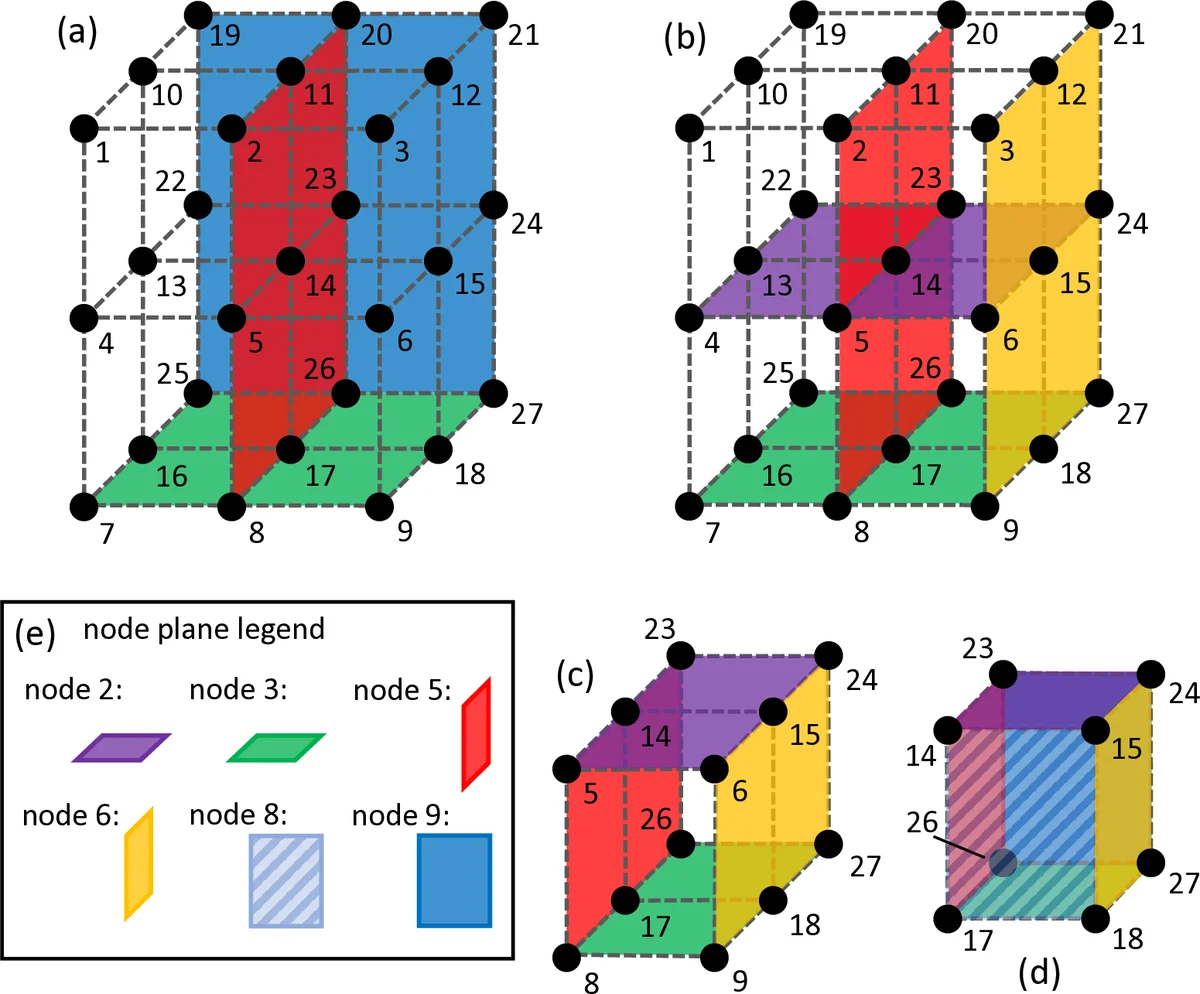
본 연구는 기존 CDC 연구가 주로 동질적인 클러스터를 전제로 설계된 점을 지적하고, 실제 데이터센터와 클라우드 환경에서 흔히 나타나는 저장 용량·연산 능력의 이질성을 고려한 설계가 필요함을 강조한다. 이를 위해 저자들은 ‘하이퍼큐보이드(Hyper‑Cuboid)’라 불리는 고차원 격자 구조를 활용한다. 격자상의 각 점은 하나의 입력 파일과 하나의 Reduce 함수에 대응하며, 노드들은 격자의 행·열·면 등 특정 하위 집합에 속하는 점들을 할당받는다. 이때 파일 복제 정도 r(각 파일이 매핑되는 노드 수)와 함수 복제 정도 s(각 Reduce 함수가 실행되는 노드 수)가 격자 차원의 크기로 직접 결정된다.
핵심 아이디어는 두 단계의 Shuffle 과정을 도입하는 것이다. 첫 번째 라운드에서는 ‘요청 노드 수가 1인’ 중간값(Intermediate Value, IV)을 XOR 기반 코딩으로 두 노드에게 동시에 전송함으로써 전송량을 절반으로 줄인다. 두 번째 라운드에서는 ‘요청 노드 수가 2인’ IV를 3개의 패킷으로 분할하고, 각 노드가 보유한 패킷을 선형 결합한 형태로 전송한다. 전송된 선형 결합 행렬은 전역적으로 전치 가능한 전치 행렬(A)와 동형이므로, 각 노드는 자신이 필요로 하는 모든 패킷을 역행렬 연산만으로 복구할 수 있다. 이 설계는 기존 CDC에서 요구되던 대규모 랜덤 선형 조합 연산을 크게 감소시켜 인코딩·디코딩 복잡도를 낮춘다.
또한, 저자들은 제안 설계가 요구하는 파일·함수 수가 기존 설계에 비해 지수적으로 감소한다는 점을 강조한다. 기존 Li et al.의 계단식 CDC는 r·s·K 정도의 파일·함수가 필요했으나, 하이퍼큐보이드 구조는 K^(1/2) 수준으로 축소된다. 이는 시스템 규모가 커질수록 스토리지·관리 비용을 크게 절감한다는 실질적 이점을 제공한다.
이론적 분석에서는 계산 부하 r와 통신 부하 L 사이의 근본적인 trade‑off 곡선을 도출하고, 제안 설계가 L* (r,s) ≤ c·L_opt (c는 상수) 를 만족함을 증명한다. 특히, 동질 네트워크에서도 기존 Li et al.이 제시한 ‘근사 최적’ 한계를 깰 수 있음을 수치 예시(예: K=4, r=s=2)로 보여준다. 이때 L_c≈0.417는 기존 L_1≈0.444보다 작으며, 이는 함수 할당 자유도가 기존 가정(각 Reduce 함수가 정확히 s 노드에만 할당)보다 넓어졌기 때문에 가능한 결과이다.
이질 네트워크에 대해서는 각 노드의 저장 용량 M_k와 연산 능력에 따라 격자 차원을 비균등하게 설정한다. 예를 들어, 저장 용량이 큰 노드는 격자의 여러 차원을 동시에 차지하도록 하여 파일 복제율을 높이고, 작은 노드는 복제율을 낮춘다. 이렇게 하면 전체 시스템의 평균 r는 유지하면서, 통신 부하는 각 노드의 요청 패턴에 맞춰 최적화된다. 저자들은 이러한 비대칭 설계가 동일 파라미터(전체 파일 수, 전체 함수 수) 하에서 동질 설계보다 더 낮은 L을 달성함을 시뮬레이션을 통해 검증한다.
요약하면, 본 논문은 (1) 입력 파일과 Reduce 함수의 동시 할당을 위한 조합적 설계, (2) 다중 라운드 Shuffle를 통한 효율적 코딩, (3) 이질 네트워크 지원 및 (4) 정보이론적 하한에 근접한 상수 배 최적성을 제공한다는 점에서 CDC 분야에 중요한 진전을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기