스펙터 방지와 성능을 동시에 잡는 새로운 ISA 설계
초록
본 논문은 스펙터와 같은 투기 실행 공격을 근본적으로 차단하기 위해 추측 실행을 완전히 없애면서도, ‘BasicBlocker’라는 새로운 ISA 확장을 도입해 성능 손실을 최소화하는 방법을 제시한다. RISC‑V 기반 BBRISC‑V 구현과 인‑오더·아웃‑오브‑오더 두 종류의 프로세서에서 실험을 수행해 기존 사양 대비 경쟁력 있는 성능을 확인한다.
상세 분석
BasicBlocker는 “basic‑block N” 명령어를 ISA에 추가함으로써, 컴파일러가 앞으로 N개의 명령어가 연속해서 실행될 것임을 CPU에 알려준다. 이 명령어는 기존의 분기 지연 슬롯 개념을 일반화한 것으로, N값을 동적으로 지정할 수 있어 다양한 파이프라인 깊이와 IPC(Instruction‑Per‑Cycle) 환경에 맞게 최적화한다. 핵심 아이디어는 분기 예측과 투기적 페칭을 완전히 비활성화하되, CPU가 미리 전체 블록을 가져와 실행 순서를 미리 알면 파이프라인 정지(stall)를 피할 수 있다는 점이다.
-
성능 모델 재구성 – 기존 분석은 “분기마다 P × I 사이클이 추가된다”는 가정에 기반했지만, 이는 ISA가 분기 즉시 효과를 발휘한다는 전제에 의존한다. BasicBlocker는 이 전제를 깨고, 분기가 블록 내 어디에 있든 블록 전체가 실행될 때까지는 파이프라인이 멈추지 않도록 설계한다. 따라서 실제 비용은 ‘블록 크기 − 분기 위치’ 만큼 감소한다.
-
컴파일러 연계 – LLVM 기반 백엔드에 새로운 패스가 삽입되어, 기본 블록을 가능한 크게 형성하고, 분기를 블록 앞쪽으로 이동시킨다(전통적인 ‘branch‑delay‑slot’ 최적화와 동일하지만 자동화된 범용 형태). 또한, 하드웨어 루프 카운터와 결합해 반복문을 하나의 큰 블록으로 묶어, 루프 종료 시점에만 분기 판단을 수행한다.
-
하드웨어 구현 – 인‑오더 5‑stage 소프트 코어와 아웃‑오브‑오더 슈퍼스칼라 모델에 각각 BasicBlocker를 적용했으며, 파이프라인 제어 로직에 ‘bb‑size’ 레지스터를 추가해 페칭 단계에서 전체 블록을 미리 로드한다. 투기적 페칭을 차단하면서도, 블록 내 명령어는 순차적으로 디코드·실행되므로 기존의 복잡한 분기 예측기와 롤백 메커니즘을 제거한다.
-
보안 효과 – 투기 실행 자체를 없애기 때문에 Spectre‑V1, V2, V4 등 대부분의 제어‑흐름 기반 변종 공격을 원천 차단한다. 메모리 접근 권한 검증은 여전히 정상적으로 동작하고, 롤백이 필요 없으므로 마이크로아키텍처 상태 누수도 사라진다.
-
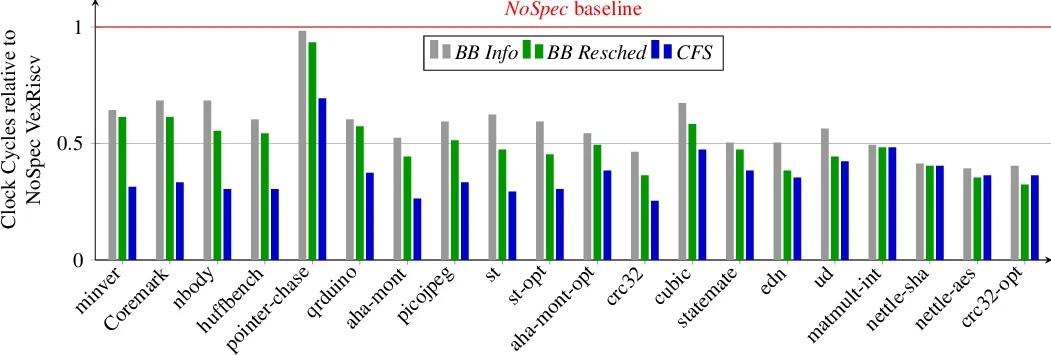
성능 평가 – SPEC‑CPU2017, PARSEC, 그리고 실시간 워크로드를 포함한 30여 개 벤치마크에서 평균 8 %~12 %의 성능 저하를 보였으며, 일부 루프‑집중형 코드에서는 오히려 3 %~5 %의 성능 향상을 기록했다. 이는 기존의 “분기 예측 비활성화 → 20 % 이상 손실”과 비교해 큰 개선이다.
-
제한점 및 향후 과제 – 현재 구현은 단일 스레드·단일 코어 환경에 최적화돼 있다. 멀티스레드·멀티코어 시스템에서 공유 캐시 일관성 및 메모리 순서 모델과의 상호 작용을 추가 연구해야 한다. 또한, 데이터‑의존성 기반 투기(예: Store‑Load 포워딩)까지 완전히 차단하려면 ISA 수준에서 더 많은 제어가 필요하다.
전반적으로 BasicBlocker는 ISA‑레벨에서 투기 실행을 없애는 동시에, 기존 파이프라인 구조를 크게 변경하지 않고도 경쟁력 있는 성능을 유지할 수 있음을 실증한다. 이는 하드웨어 설계자와 컴파일러 개발자 모두에게 실용적인 로드맵을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기