워드 임베딩 기반 의미 상호작용: 시뮬레이션을 통한 정량적 평가
초록
**
본 논문은 시각 텍스트 분석에서 의미 상호작용(SI)의 입력 특징으로 전통적인 bag‑of‑words 대신 사전 학습된 워드 임베딩을 사용했을 때, 사용자의 의도를 더 정확히 학습할 수 있는지를 검증한다. 인간 중심의 정성적 평가와, 라벨이 있는 텍스트 데이터셋을 이용해 사용자의 드래그·드롭 행동을 시뮬레이션하는 정량적 알고리즘 평가를 결합하여 두 SI 모델(SI‑keyword, SI‑embedding)을 비교한다. 실험 결과, 임베딩 기반 SI가 분류 정확도와 시각적 군집 형성 측면에서 일관되게 우수함을 보여준다.
**
상세 분석
**
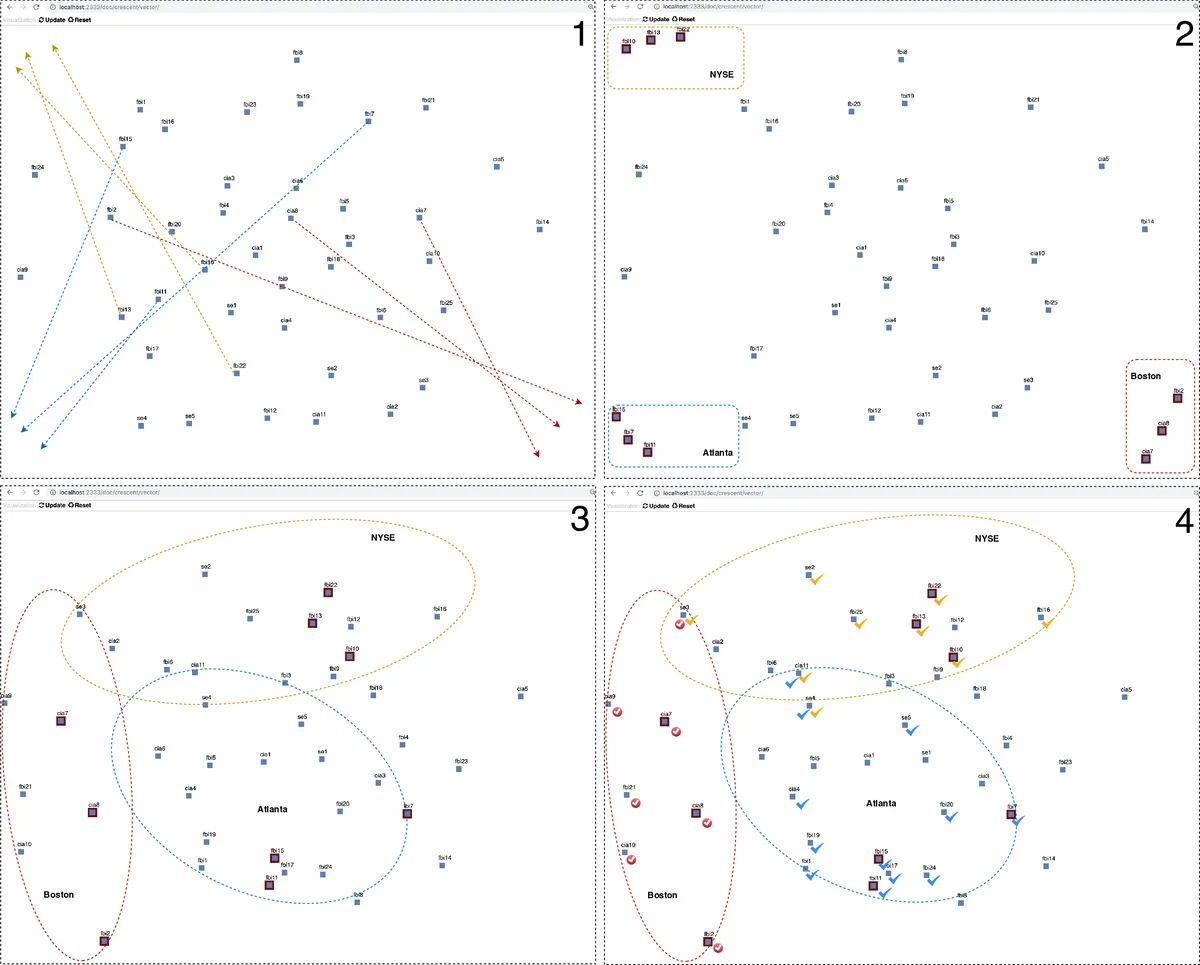
이 연구는 의미 상호작용(Semantic Interaction, SI)의 핵심 가정인 “사용자가 2차원 투영 공간에서 문서를 직접 이동시킴으로써 암묵적인 의도를 시스템에 전달한다”는 점에 주목한다. 기존 SI 시스템은 주로 TF‑IDF 기반의 키워드 벡터를 특징으로 사용했으며, 이는 단어 수준의 빈도 정보에 국한돼 의미적 추상화를 충분히 제공하지 못한다는 한계가 있다. 저자들은 이러한 한계를 극복하기 위해 사전 학습된 GloVe 임베딩(300 차원)을 평균화하여 문서 수준의 밀집 표현을 만든다. 임베딩은 단어 간 의미적 유사성을 내재하고 있어, 사용자가 ‘문서 A와 B는 비슷하다’는 직관을 더 잘 반영할 수 있다.
평가 방법으로는 두 가지 축을 제시한다. 첫 번째는 인간 중심의 정성적 평가로, 인텔리전스 분석가가 Crescent 데이터셋(테러 관련 가상의 보고서)에서 SI‑embedding과 SI‑keyword를 사용해 군집을 형성하고, 전문가가 결과 시각화를 검토한다. 여기서 SI‑embedding은 명확한 군집 경계를 만들고, 다중 주제 문서를 자연스럽게 중간에 배치하는 반면, SI‑keyword는 군집이 흐릿하고 과도한 키워드에 과적합되는 현상이 관찰되었다.
두 번째는 알고리즘 중심의 정량적 평가이다. 라벨이 있는 20Newsgroup과 VISpubdata 데이터셋을 이용해 사용자의 ‘문서 이동’ 행동을 시뮬레이션한다. 각 인터랙션 루프마다 5개의 문서를 두 클래스로 이동시켜 SI 모델이 가중치를 업데이트하도록 하고, 업데이트된 모델을 k‑NN( k=3) 분류기에 적용해 정확도를 측정한다. 결과는 네 개의 작업(T_rec, T_religion, T_sys, T_vis) 모두에서 SI‑embedding이 평균 정확도와 최종 정확도에서 SI‑keyword를 크게 앞선다(예: T_rec에서 0.92 vs 0.50 수준). 이는 임베딩이 고차원 의미 공간을 보다 효과적으로 학습하고, 증분적인 인터랙션에도 안정적으로 적응함을 의미한다.
이 논문의 주요 기여는 (1) 워드 임베딩을 SI에 적용한 새로운 파이프라인을 제시하고, (2) 인간 중심 평가의 재현성·확장성 문제를 보완하기 위한 시뮬레이션 기반 정량 평가 프레임워크를 구축했다는 점이다. 또한 실험을 통해 임베딩 기반 SI가 텍스트 분석에서 사용자의 미묘한 의도를 포착하는 데 유리함을 실증하였다. 향후 연구에서는 더 복잡한 문서 구조(문단, 문서 간 관계)와 다양한 임베딩(문맥 기반 BERT 등)을 적용해 SI의 일반화 가능성을 탐색할 여지가 있다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기