FPGA 기반 DNA 서열 정렬 가속화 종합 조사
초록
본 논문은 DNA 서열 정렬에 널리 사용되는 세 가지 알고리즘(페어와이즈 동적 프로그래밍, 해시 테이블 기반, BWT‑FM 인덱스)과 이들에 대한 FPGA 가속기 구현을 체계적으로 정리한다. FPGA의 대규모 병렬성, 재구성 가능성, 에너지 효율성을 활용한 설계 사례들을 비교 분석하고, 각 접근법의 장·단점 및 시간에 따른 발전 흐름을 제시한다.
상세 분석
본 설문은 현대 유전체학에서 데이터 생성 속도가 연산 능력 향상을 앞서는 현상을 강조하며, 특히 DNA 읽기(read)와 레퍼런스 게놈 간 정렬 단계가 전체 파이프라인의 병목임을 지적한다. 이를 해결하기 위해 FPGA가 제공하는 대규모 병렬 연산 구조와 낮은 전력 소모가 매력적인 대안으로 부각된다. 논문은 정렬 알고리즘을 크게 세 부류로 나누어 각각의 특성과 FPGA 구현상의 핵심 포인트를 상세히 분석한다.
첫 번째 부류인 페어와이즈 시퀀스 정렬(PSA)은 Needleman‑Wunsch(NW)와 Smith‑Waterman(SW)와 같은 동적 프로그래밍(DP) 기반 알고리즘을 포함한다. DP 매트릭스의 각 셀은 상·좌·대각선 셀에 의존하므로 전통적인 순차 처리에서는 O(m·n) 복잡도가 발생한다. FPGA에서는 대각선 별 독립성을 이용해 systolic array 형태의 Processing Element(PE)들을 배열함으로써 한 사이클에 다수의 셀을 동시에 계산한다. 논문은 Lipton 등 초기 VLSI 구현부터 최신 고속 PE 설계까지, 점수 계산을 단순화(삽입·삭제 1점, 치환 2점)하고 파이프라인 깊이를 최소화한 사례들을 제시한다. 또한, PE 간 데이터 흐름을 최적화하기 위한 레지스터 체인, 블록 RAM 활용, 그리고 스코어링 매트릭스의 온‑칩 저장 전략을 논의한다.
두 번째 부류는 해시 테이블 기반 방법이다. SSAHA와 같은 알고리즘은 레퍼런스 서열을 k‑tuple(보통 2~12bp) 단위로 해시화하고, 읽기 서열의 k‑tuple을 빠르게 매칭시켜 후보 위치를 추출한다. FPGA 구현에서는 대용량 해시 테이블을 BRAM 혹은 외부 DDR과 결합해 파이프라인화하고, 해시 충돌 해결을 위한 체이닝 또는 오픈 어드레싱을 하드웨어 수준에서 구현한다. 핵심은 해시 생성과 조회를 동시에 수행하면서 메모리 대역폭을 효율적으로 사용하도록 메모리 인터리빙과 멀티포트 BRAM을 활용하는 것이다. 논문은 이러한 설계가 DP 기반에 비해 연산량은 크게 감소하지만, 해시 테이블 구축 비용과 메모리 사용량이 크게 늘어나는 트레이드오프를 가지고 있음을 강조한다.
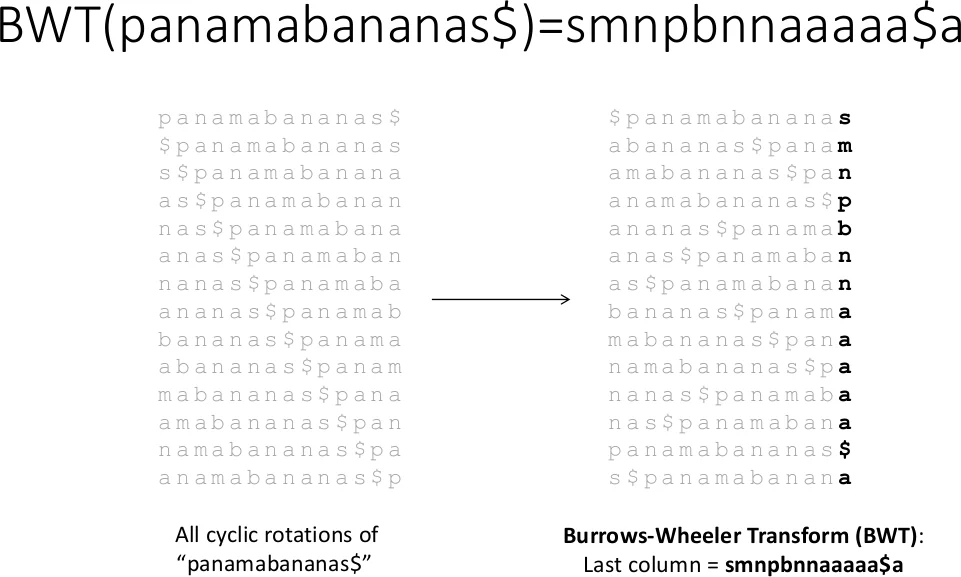
세 번째 부류는 Burrows‑Wheeler Transform(BWT)와 FM‑index를 이용한 압축 기반 정렬이다. BWT는 레퍼런스 서열을 압축 저장하면서도 역방향 검색을 가능하게 하며, FM‑index는 O(1)에 가까운 패턴 매칭을 제공한다. FPGA에서는 BWT 변환 결과와 i(s), c(n,s) 테이블을 온‑칩 메모리 혹은 고속 외부 메모리에 배치하고, 검색 단계에서 top/bottom 포인터를 반복적으로 업데이트하는 루프를 파이프라인화한다. 논문은 Bowtie, BWA 등 소프트웨어 구현의 핵심 연산을 하드웨어 가속기로 옮겨, 특히 대규모 레퍼런스(인간 게놈)에서도 메모리 접근 병목을 최소화하는 설계 기법을 상세히 설명한다. 또한, 압축률이 높은 DNA 특성을 활용해 런‑길이 인코딩을 하드웨어에서 직접 수행함으로써 메모리 사용량을 크게 절감한다는 점을 강조한다.
전반적으로 논문은 각 알고리즘 부류가 FPGA에 매핑될 때 발생하는 데이터 의존성, 메모리 대역폭, 스케일링 한계 등을 비교한다. DP 기반은 높은 연산 집약도와 정밀도 보장을 제공하지만, PE 수가 늘어날수록 라우팅 복잡도가 급증한다. 해시 기반은 빠른 후보 탐색이 가능하지만, 해시 테이블 크기가 급증하면 BRAM 한계에 부딪힌다. BWT‑FM 기반은 메모리 효율이 뛰어나 대규모 레퍼런스에 적합하지만, 반복적인 포인터 업데이트 로직이 파이프라인 깊이를 증가시켜 설계 난이도가 높다. 마지막으로, 논문은 최근 연구들이 이들 접근법을 혼합하거나 하이브리드 구조(예: DP와 BWT를 결합)로 전환하면서 성능·전력 효율을 지속적으로 개선하고 있음을 언급한다.
댓글 및 학술 토론
Loading comments...
의견 남기기