원시 음성으로 감정 인식을 위한 다중 시간 해상도 병렬 CNN‑LSTM 모델
초록
본 논문은 원시 음성 신호에서 감정을 인식하기 위해 서로 다른 필터 길이를 갖는 병렬 컨볼루션 레이어를 도입하고, 이를 LSTM과 완전 연결층과 결합한 하이브리드 네트워크를 제안한다. 3개의 병렬 CNN 레이어가 짧은, 중간, 긴 시간 해상도의 특징을 동시에 추출하고, LSTM이 장기 컨텍스트를 모델링한다. IEMOCAP와 MSP‑IMPROV 데이터셋에서 leave‑one‑speaker‑out 평가와 데이터 증강을 적용한 결과, 제안 모델은 기존 손수 설계된 특징 기반 SVM 및 CNN‑MFB 대비 경쟁력 있는 정확도를 달성했으며, 병렬 레이어 수, 풀링 방식, 분류 블록 구성 등에 대한 상세한 Ablation 연구도 수행하였다.
상세 분석
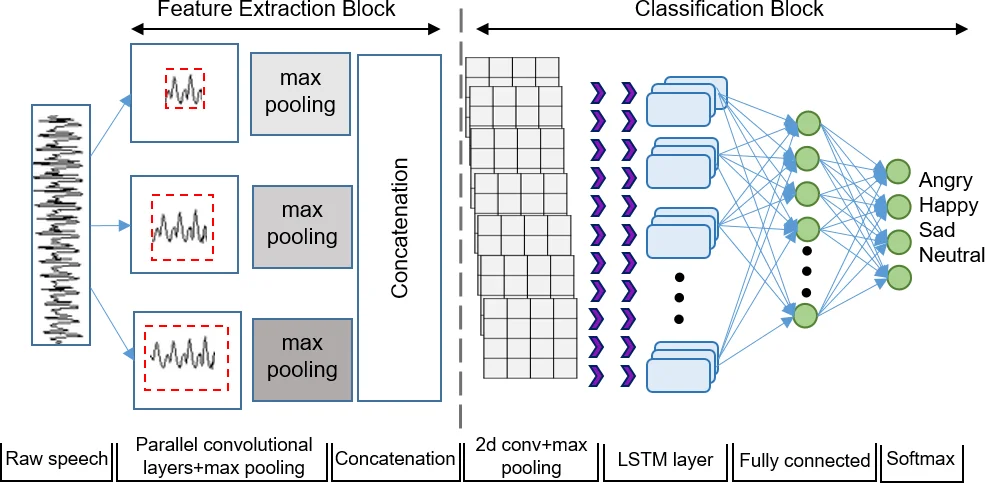
본 연구는 감정 인식에 있어 전통적인 손수 설계된 음향 특징(예: MFCC, LogMel, eGeMAPS 등)이 최적의 표현이 아닐 수 있다는 가정 하에, 원시 파형을 직접 입력으로 사용하는 엔드‑투‑엔드 학습 방식을 채택하였다. 핵심 기여는 서로 다른 필터 길이(15 ms, 25 ms, 100 ms)를 갖는 3개의 병렬 1‑D 컨볼루션 레이어를 사용해 다중 시간 해상도의 특징을 동시에 추출한다는 점이다. 이는 기존 연구에서 단일 레이어 내 다중 필터 폭을 적용한 것과 차별화되며, 각 레이어가 동일한 입력 구간에 대해 서로 다른 수용 영역을 갖게 함으로써 짧은 발화부터 긴 억양까지 다양한 감정 단서를 포착한다.
컨볼루션 출력은 각각 max‑pooling을 통해 시간 차원을 축소하고, 이후 concat 연산으로 하나의 특징 벡터로 결합된다. 이 특징은 2‑D CNN(2×2 필터, 32채널) → max‑pooling → LSTM(128 셀) → Fully‑Connected(1024) → 소프트맥스 순서의 분류 블록에 전달된다. LSTM은 감정이 문맥에 의존한다는 점을 활용해 장기 의존성을 모델링하고, 최종 FC 레이어는 판별력을 강화한다.
학습 과정에서는 RMSProp(초기 학습률 1e‑4)과 배치 정규화, 드롭아웃(0.3) 등을 적용해 안정성을 확보했으며, 데이터 증강으로는 속도 변형(0.9×, 1.1×)을 두 번 적용해 훈련 샘플을 3배로 늘렸다. 평가 방식은 leave‑one‑speaker‑out이며, 성능 지표는 클래스 불균형에 강인한 unweighted average recall (UAR)를 사용했다.
실험 결과, 제안 모델은 IEMOCAP에서 60.23 % ± 3.2, MSP‑IMPROV에서 52.43 % ± 4.1의 UAR을 기록했으며, 이는 기존 CNN+MFB(61.8 %/52.6 %)와 비슷하거나 약간 낮지만, 순수 원시 파형만을 사용한 점에서 의미가 크다. Ablation 연구에서는 병렬 레이어 수가 3개일 때 최적 성능을 보였으며, max‑pooling이 l2, average보다 우수했다. 분류 블록 구성에서도 CNN‑LSTM‑DNN 조합이 단일 DNN이나 LSTM만 사용할 때보다 현저히 높은 성능을 보였다. 입력 길이 분석에서는 6 초가 가장 높은 UAR을 제공했으며, 짧은 구간(1‑2 초)에서도 큰 성능 저하 없이 감정 인식이 가능함을 확인했다.
한계점으로는 데이터 증강에 크게 의존한다는 점, 그리고 실시간 적용 시 메모리·연산 비용이 아직 충분히 검증되지 않았다는 점을 들 수 있다. 또한, 감정 라벨이 4가지(angry, happy, neutral, sad)로 제한되어 있어 다중 라벨·연속형 감정 표현에 대한 확장성이 남아 있다. 향후 연구에서는 보다 경량화된 아키텍처 설계, 멀티모달(텍스트·영상) 통합, 그리고 연속 감정 스코어 예측으로의 확장이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기