변분 자동인코더 기반 음성 감정 잠재 표현 학습
본 연구는 변분 자동인코더(VAE)와 조건부 변분 자동인코더(CVAE)를 이용해 IEMOCAP 데이터셋의 음성 신호에서 감정에 대한 잠재 표현을 학습하고, 이를 LSTM 분류기에 입력함으로써 감정 인식 정확도를 향상시키는 것을 목표로 한다. 실험 결과, VAE‑LSTM 및 CVAE‑LSTM 모델이 기존 자동인코더‑LSTM 및 최신 CNN·BLSTM 기반 방법들을 능가하며, 특히 CVAE‑LSTM은 64.93%의 가중 정확도를 기록하여 현재 최고…
저자: Siddique Latif, Rajib Rana, Junaid Qadir
본 논문은 변분 자동인코더(VAE)와 그 변형인 조건부 변분 자동인코더(CVAE)를 활용해 음성 감정 인식에 필요한 효과적인 특징을 자동으로 학습하는 방법을 제안한다. 기존 음성 감정 인식 연구는 주로 MFCC, eGeMAPS, 로그멜 등 수작업으로 설계된 음향 특징에 의존해 왔으며, 이러한 접근법은 감정 표현의 복잡한 변동성을 충분히 포착하지 못한다는 한계가 있다. 최근 이미지 분야에서 딥러닝 기반 생성 모델이 뛰어난 특징 추출 능력을 보인 것에 착안해, 저자는 VAE가 제공하는 확률적 잠재 공간을 음성 신호에 적용함으로써 감정 구분에 유리한 저차원 표현을 얻고자 한다.
연구는 크게 네 단계로 구성된다. 첫 번째는 음성 신호 전처리 단계로, 25 ms 해밍 윈도우와 10 ms 프레임 쉬프트를 적용해 스펙트로그램을 만든 뒤, 80개의 멜 필터뱅크를 사용해 로그멜 파워 스펙트럼을 추출한다. 이렇게 얻은 800차원 피처를 100 ms 길이의 세그먼트 단위로 나누어 VAE에 입력한다. 두 번째 단계는 VAE 모델 설계이다. 인코더는 512와 256개의 은닉 유닛을 가진 두 개의 완전 연결 층을 거쳐 평균(µ)과 분산(σ) 파라미터를 출력하고, 재파라미터화 트릭을 통해 표준 정규분포에서 샘플링한 노이즈와 결합해 128차원 잠재 벡터 z를 생성한다. 디코더는 대칭 구조로 z를 입력받아 원본 로그멜 피처를 복원한다. 학습 목표는 재구성 손실(제곱 오차)과 KL 발산을 동시에 최소화하는 것이며, Adam 옵티마이저(β1=0.999, β2=0.99, ε=1e‑8, lr=1e‑3)를 사용한다.
세 번째 단계는 CVAE 확장이다. VAE와 동일한 구조를 유지하되, 인코더와 디코더 모두에 감정 레이블(c)을 원-핫 형태로 결합한다. 이를 통해 잠재 공간이 레이블에 조건화되어, 같은 음성이라도 다른 감정 라벨에 따라 서로 다른 z를 생성하도록 유도한다. CVAE는 레이블 정보를 활용함으로써 감정 구분에 더 직관적인 특징을 제공한다는 가설을 검증한다.
네 번째 단계는 학습된 잠재 특징을 이용한 감정 분류이다. 저자는 LSTM 네트워크를 선택했는데, 이는 감정이 시간적 맥락에 크게 의존한다는 점에서 적합하기 때문이다. LSTM은 두 개의 연속된 층으로 구성되며, 각 층은 하이퍼볼릭 탄젠트 활성화 함수를 사용한다. 두 번째 LSTM 층의 출력은 완전 연결 층을 거쳐 소프트맥스 레이어에 전달되어, 네 가지 감정 클래스(중립, 행복/흥분, 슬픔, 분노) 혹은 연속 차원(각성, 힘, 가치)의 세 구간(저·중·고) 중 하나로 예측한다. 과적합 방지를 위해 조기 종료와 최대 20 epoch 제한을 적용하였다.
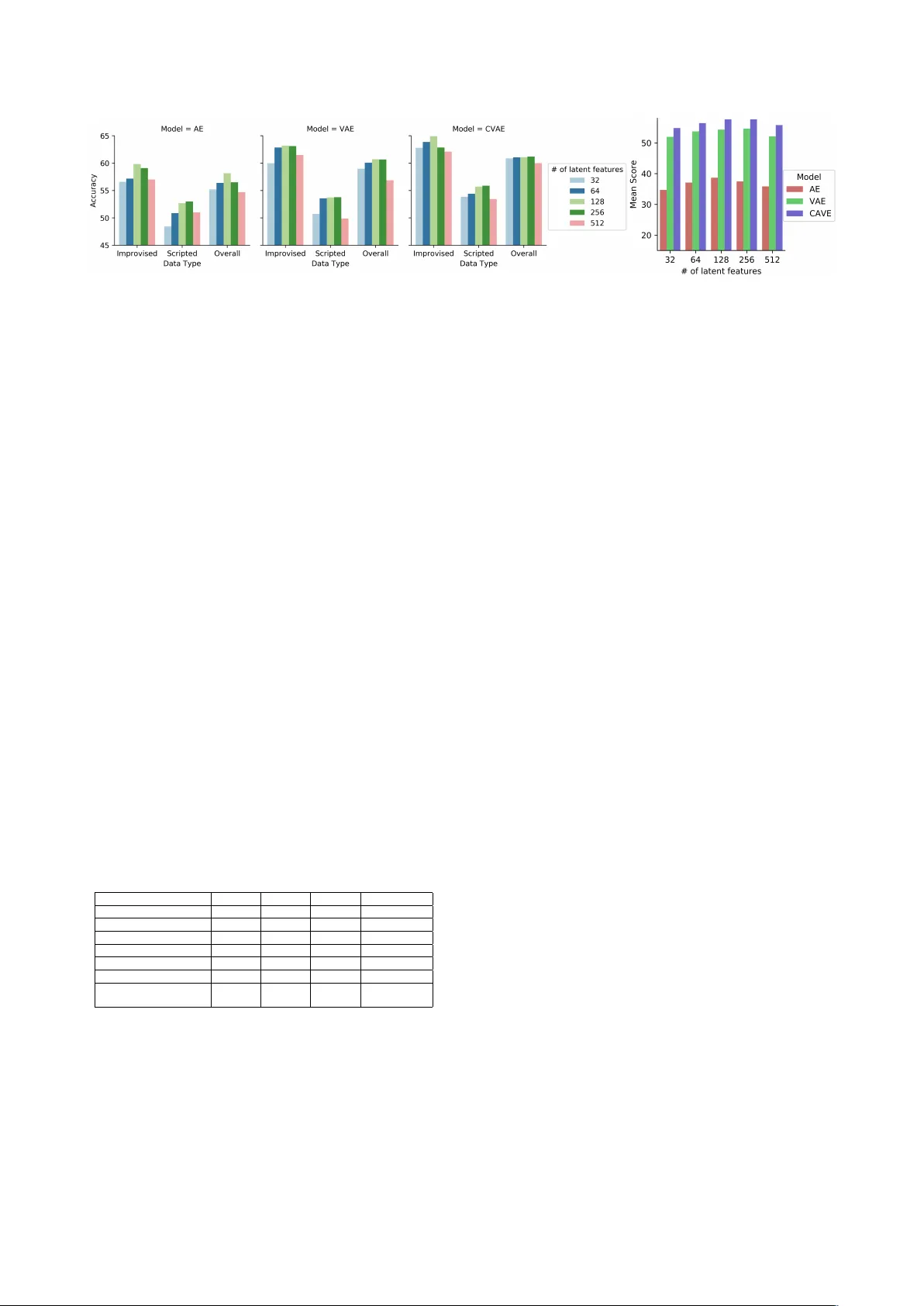
실험은 IEMOCAP 코퍼스를 사용했으며, 10명의 화자(5세션) 데이터를 스피커 독립 방식으로 학습·검증하였다. 데이터는 즉흥 대화와 스크립트 대화로 구분되며, 감정 라벨은 중립, 행복(흥분 포함), 슬픔, 분노 네 클래스로 재구성하였다. 또한 연속 차원 라벨을 1~5 스케일로 정규화하고, 3구간(저·중·고)으로 변환해 다중 클래스 분류를 수행했다. 평가 지표는 가중 정확도(WA)와 비가중 정확도(UA)이며, 10‑fold 교차 검증을 통해 평균 성능을 보고한다.
결과는 다음과 같다. 동일한 구조의 전통적 자동인코더(AE)와 비교했을 때, VAE‑LSTM은 WA 60.71% (전체 데이터)에서 3~5% 정도 향상된 성능을 보였다. CVAE‑LSTM은 라벨 조건화를 통해 WA 64.93%를 달성했으며, 이는 기존 최고 성능인 BLSTM 기반 62.85%와 비교해 유의미하게 높은 수치이다. 또한, 감정 차원별 실험에서는 잠재 특징 수를 64, 128, 256으로 변동시켰을 때 평균 F‑score가 0.58~0.62 사이에서 최적화되는 것을 확인했다. 이러한 결과는 VAE가 음성 신호의 복잡한 통계적 구조를 효과적으로 압축하고, CVAE가 감정 라벨 정보를 활용해 더욱 구별 가능한 표현을 만든다는 가설을 뒷받침한다.
논문은 몇 가지 제한점을 언급한다. 첫째, IEMOCAP는 영어 대화에 한정된 데이터이며, 다른 언어·문화권에서의 일반화 가능성을 검증하지 않았다. 둘째, CVAE에서 레이블을 직접 결합하는 방식은 라벨이 정확히 알려진 상황에만 적용 가능하므로, 라벨이 없는 실제 서비스 환경에서는 추가적인 반지도 학습이나 준지도 방법이 필요하다. 셋째, VAE와 LSTM을 별도로 학습하는 파이프라인 구조는 최적화가 어려울 수 있어, 엔드‑투‑엔드 방식의 통합 학습이 향후 연구 과제로 제시된다.
결론적으로, 본 연구는 변분 자동인코더 기반 잠재 특징이 음성 감정 인식에 유용함을 실증하고, 조건부 변분 모델이 라벨 정보를 활용해 성능을 더욱 끌어올릴 수 있음을 보여준다. 향후 연구에서는 다국어 데이터, 대규모 비지도 사전 학습, 그리고 VAE‑LSTM을 하나의 그래프 안에서 공동 최적화하는 방법을 탐색함으로써 실용적인 감정 인식 시스템 구축에 기여할 수 있을 것으로 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기