강화된 토픽 인식 컨볼루션 시퀀스‑투‑시퀀스 요약 모델
초록
본 논문은 토픽 정보를 결합한 컨볼루션 기반 Seq2Seq 모델에 자기비판 강화학습(SCST)을 적용해, 요약의 일관성·다양성·정보량을 향상시키고 ROUGE 점수를 직접 최적화한다. Gigaword, DUC‑2004, LCSTS 실험에서 기존 최첨단 모델들을 능가한다.
상세 분석
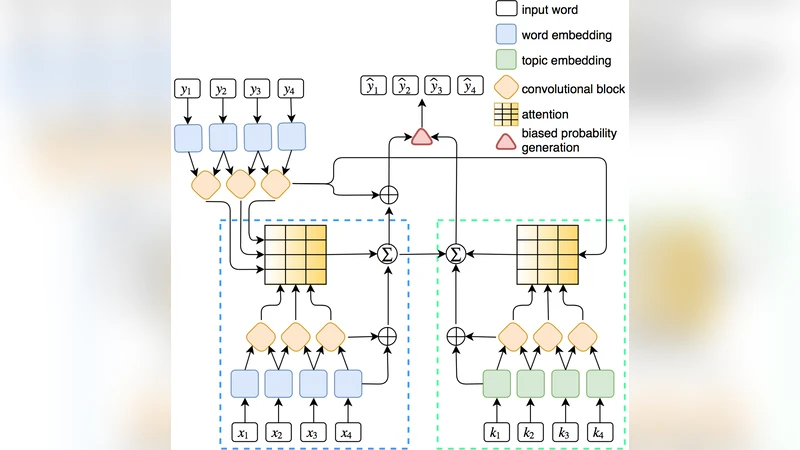
이 연구는 두 가지 핵심 혁신을 제시한다. 첫째, 기존 ConvS2S 구조에 토픽 레벨 인코더와 토픽‑워드 공동 어텐션을 도입해 고수준 의미 정보를 제공한다. 토픽은 LDA로 사전 학습된 토픽‑워드 분포에서 추출한 상위 N 단어를 토픽 어휘(K)로 정의하고, 해당 단어는 별도의 토픽 임베딩 행렬 D_topic에 매핑된다. 워드와 토픽 임베딩은 각각 위치 임베딩과 합쳐져 컨볼루션 블록에 입력되며, 각 블록은 GLU와 잔차 연결을 통해 깊은 특징을 추출한다. 디코더 단계에서는 워드‑레벨 어텐션 α와 토픽‑레벨 어텐션 β를 동시에 계산한다. α는 디코더 현재 상태와 워드 인코더 출력의 내적으로, β는 디코더 상태와 워드·토픽 인코더 출력의 합산 내적으로 정의된다. 이렇게 얻은 두 종류의 컨텍스트 벡터 c와 \tilde{c}는 각각 워드와 토픽 디코더 출력에 더해져 다음 레이어 입력이 된다.
두 번째 혁신은 ‘편향된 확률 생성(biased probability generation)’ 메커니즘이다. 최종 출력 확률은 워드 디코더 출력 Ψ(h^o)와 토픽 디코더 출력 Ψ(\tilde{h}^t)를 합산하고, 후보 단어가 토픽 어휘에 속할 경우 토픽 부분을 가중치로 부여한다. 이는 중요한 토픽 단어가 더 높은 확률로 선택되게 하여 검색 공간을 효율화하고, 요약에 핵심 주제가 자연스럽게 반영되도록 만든다.
학습 측면에서는 전통적인 교사 강제(maximum‑likelihood) 손실이 ROUGE와 같은 문장 수준 평가 지표와 불일치한다는 점을 지적하고, 자기비판 강화학습(SCST)을 적용한다. 모델은 greedy decoding으로 얻은 베이스라인 요약 \hat{y}와 샘플링으로 얻은 요약 y_s의 ROUGE 점수를 각각 r(\hat{y})와 r(y_s)로 계산하고, 차이를 보상으로 사용해 정책 그래디언트 손실 L_rl = -(r(y_s)-r(\hat{y}))·log p(y_s) 를 최소화한다. 이 과정은 노출 편향을 완화하고, 평가 지표를 직접 최적화함으로써 실제 테스트 성능을 크게 끌어올린다.
실험에서는 Gigaword(3.8M 훈련), DUC‑2004(500 기사), 중국어 LCSTS(2.4M 쌍) 세 데이터셋을 사용했다. 토픽‑워드 공동 어텐션과 편향 생성만 적용해도 ROUGE‑1/2/L이 각각 12%p 상승했으며, SCST와 결합했을 때는 추가로 0.51%p 정도의 개선을 보였다. 특히 LCSTS와 같이 토픽이 뚜렷한 도메인에서는 토픽 편향이 요약의 핵심 정보를 놓치지 않게 하는 데 큰 효과를 나타냈다.
전체적으로 이 논문은 ConvS2S의 병렬 학습 효율성을 유지하면서, 토픽 수준의 전역 정보를 효과적으로 통합하고, 강화학습을 통해 비차별적인 평가 지표를 직접 최적화한다는 점에서 기존 RNN‑ 기반 요약 모델이나 단순 ConvS2S 대비 확연한 장점을 제공한다. 향후 토픽 모델을 동적으로 학습하거나, 멀티‑모달(이미지·텍스트) 토픽을 결합하는 방향으로 확장이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기