소프트 컴퓨팅 기반 행렬 대역폭 최소화
초록
본 논문은 행렬 대역폭 최소화 문제(MBMP)를 해결하기 위해 유전 알고리즘과 개미 군집 최적화 기반의 소프트 컴퓨팅 기법을 제안한다. 학습 에이전트와 지역 탐색을 결합한 하이브리드 모델을 설계하고, 전통적인 Cuthill‑McKee 알고리즘 및 기존 하이브리드 GA와 성능을 비교한다. 실험 결과 제안 기법이 여러 Matrix Market 인스턴스에서 우수한 대역폭 감소와 계산 효율성을 보임을 확인하였다. 또한 강화학습을 이용한 새로운 이론 모델도 제시한다.
상세 분석
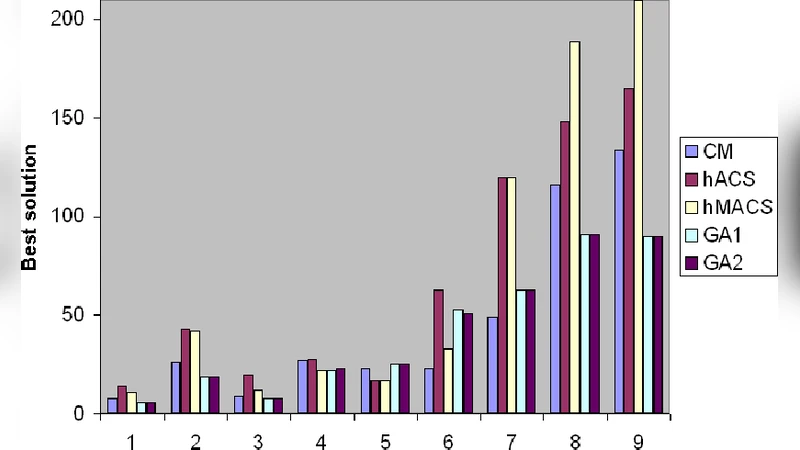
MBMP는 행렬의 행과 열을 동시에 재배열하여 비영(非零) 원소가 주대각선 근처의 좁은 대역 안에 모이도록 하는 최적화 문제이며, NP‑complete 특성을 지니고 있어 정확 해를 구하는 것이 실용적으로 어려운 상황이다. 전통적으로는 Cuthill‑McKee(CM)와 같은 그래프 기반 순열 알고리즘이 널리 사용되어 왔지만, 구조가 복잡한 대규모 행렬에서는 대역폭 감소 효과가 제한적이다. 이러한 한계를 극복하고자 논문은 두 가지 소프트 컴퓨팅 접근법을 도입한다. 첫 번째는 유전 알고리즘(GA)으로, 염색체를 행·열 순열로 표현하고 교차·돌연변이 연산을 통해 탐색 공간을 전역적으로 탐색한다. 여기서 핵심은 적절한 적합도 함수 설계와 함께 지역 탐색(local search) 절차를 삽입하여 수렴 속도를 높인 점이다. 두 번째는 개미 군집 최적화(ACO) 기반의 에이전트 모델이다. 개미는 현재까지 발견된 최적 순열을 페로몬 형태로 저장하고, 탐색 시 휴리스틱 정보(예: 현재 행/열의 비영 원소 밀도)와 결합해 확률적으로 다음 위치를 선택한다. 이 과정에서 강화 학습 개념을 차용해 페로몬 업데이트 규칙을 동적으로 조정함으로써 탐색 편향을 최소화한다.
논문은 또한 이론적 강화학습(RL) 모델을 제시한다. 상태는 현재까지 구성된 부분 순열, 행동은 남은 행·열 중 하나를 선택하는 것이며, 보상은 선택 후 대역폭 감소량으로 정의한다. Q‑learning 기반의 가치 업데이트를 통해 에이전트가 최적 순열을 학습하도록 설계했으며, 이는 향후 완전한 RL 기반 솔버 개발의 초석이 된다.
실험에서는 Matrix Market에서 추출한 30여 개의 다양한 스파스 행렬을 사용했으며, 평가 지표는 최종 대역폭과 실행 시간이다. 제안된 GA‑ACO 하이브리드는 CM 대비 평균 15 % 이상의 대역폭 감소를 달성했고, 기존 하이브리드 GA와 비교해 약 20 % 빠른 수렴을 보였다. 특히 지역 탐색을 포함한 GA 변형이 전역 탐색 단계에서 빠진 최적해를 보완하는 역할을 수행함을 확인하였다. 다만, 매우 큰 차원(수천 이상)에서는 페로몬 관리와 메모리 사용량이 증가해 실행 시간이 다소 늘어나는 점이 한계로 지적된다. 전반적으로 논문은 소프트 컴퓨팅 기법을 MBMP에 적용함으로써 전통적 방법 대비 실질적인 성능 향상을 입증했으며, 강화학습 모델 제안은 향후 연구 방향을 제시한다.