PySS3 : 파이썬 기반 SS3 텍스트 분류기와 시각화 도구
SS3는 텍스트 스트림의 조기 위험 탐지를 위해 설계된 증분 학습 및 시각적 설명이 가능한 분류기이다. 본 논문은 SS3를 파이썬 패키지(PySS3)로 구현하고, “Live Test”와 명령줄 도구를 포함한 시각화 기능을 제공함으로써 일반 텍스트 분류에도 손쉽게 적용할 수 있게 한다.
저자: Sergio G. Burdisso, Marcelo Errecalde, Manuel Montes-y-Gomez
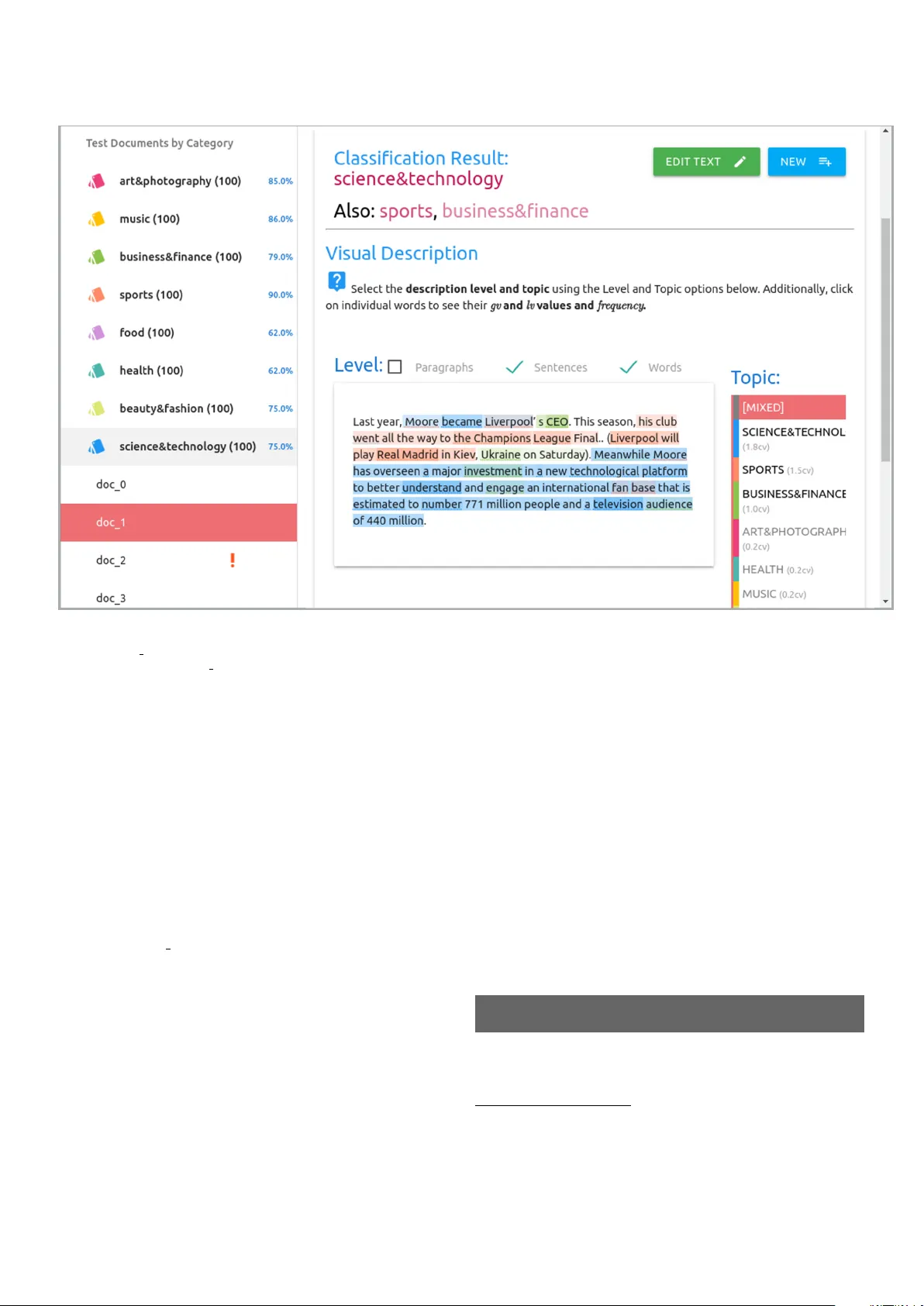
본 논문은 최근 CLEF eRisk 과제에서 우수한 성능을 보인 SS3 텍스트 분류기를 파이썬 패키지 형태로 구현한 PySS3를 소개한다. SS3는 텍스트 스트림에서 조기 위험을 탐지하기 위해 설계된 모델로, 증분 학습(incremental training)과 실시간 분류(incremental classification)를 지원한다는 점이 기존 머신러닝 분류기와 차별화된다. 또한 각 단어가 특정 카테고리에 얼마나 독점적으로 기여하는지를 0‑1 범위의 신뢰도 점수 gᵥ(w,c) 로 표현하고, 이를 계층적 블록(문단‑문장‑단어) 구조에 재귀적으로 집계함으로써 최종 카테고리‑신뢰도 d 벡터를 도출한다.
SS3의 핵심은 gᵥ 함수이다. gᵥ 는 세 가지 하위 함수 lᵥ, sg, sn 에 의해 구성되며, 각각 로컬 빈도 평활화(σ), 다른 카테고리와의 구별도(λ), 다중 카테고리 억제(ρ)를 담당한다. lᵥ 는 카테고리 c 내 단어 w 의 빈도를 정규화하고, σ 파라미터로 평활화 정도를 조절한다. sg 는 시그모이드 형태로 lᵥ 값이 다른 카테고리 대비 얼마나 큰지를 평가해 0‑1 사이의 가중치를 부여한다. λ가 클수록 lᵥ 값이 평균에서 크게 벗어나야 높은 sg 값을 얻는다. sn 은 해당 단어가 여러 카테고리에서 높은 sg 값을 가질 경우 전체 신뢰도를 감소시키는 역할을 하며, ρ 파라미터가 클수록 억제 강도가 강해진다. 이러한 설계는 단어가 특정 카테고리에 독점적으로 기여할 때 높은 신뢰도를 부여하고, 흔히 나타나는 일반 단어는 신뢰도를 낮춰 클래스 불균형과 잡음에 강인한 모델을 만든다.
분류 파이프라인은 두 단계로 이루어진다. 첫 번째 단계에서는 입력 문서를 문단‑문장‑단어 계층으로 분해한다. 두 번째 단계에서는 각 단어에 gᵥ 벡터를 계산하고, 이를 문장‑문단 수준으로 재귀적으로 집계한다. 기본 집계 연산은 벡터 합이지만, PySS3는 사용자가 직접 정의한 집계 함수를 삽입할 수 있는 API를 제공한다. 최종적으로 얻어진 d 벡터는 각 카테고리별 신뢰도 점수를 담고 있으며, 가장 높은 점수를 가진 카테고리가 예측 결과가 된다.
PySS3는 파이썬 2·3을 모두 지원하고, Linux, macOS, Windows에서 동작한다. GitHub 저장소는 Travis CI와 연동돼 다양한 OS·Python 버전에서 자동 테스트가 수행되며, 코드 품질과 호환성을 지속적으로 검증한다. 배포는 PyPI를 통해 이루어지며, pip install pyss3 명령 한 줄로 설치가 가능하다.
패키지는 크게 네 부분으로 구성된다.
1) **pyss3** 핵심 모듈: SS3 클래스를 제공해 Scikit‑learn과 유사한 fit, predict, set_hyperparameters 등의 메서드를 지원한다. 또한 기존 논문에서 제안된 변형(예: n‑gram 실시간 인식)도 옵션으로 제공한다.
2) **pyss3.server**: 웹 기반 “Live Test” 도구를 구현한다. 사용자는 학습된 모델을 서버에 로드하고, 테스트 문서를 실시간으로 입력하거나 기존 테스트 셋을 선택해 결과를 확인한다. 결과는 단어‑문장‑문단 수준에서 색상으로 강조되어, 모델이 어떤 텍스트 구간에 높은 신뢰도를 부여했는지 직관적으로 파악할 수 있다. 오류 사례도 즉시 시각화돼 빠른 디버깅이 가능하다.
3) **pyss3.cmd**: 명령줄 인터페이스 도구다. pyss3 명령을 통해 모델 학습, 교차 검증, 그리드 서치, 평가 결과 저장 등을 코딩 없이 수행한다. 특히 평가 이력과 하이퍼파라미터 조합을 자동으로 기록하고, HTML 기반 3D 플롯으로 시각화해 파라미터‑성능 관계를 한눈에 볼 수 있다.
4) **pyss3.util**: 데이터 로딩, 전처리, 평가(Accuracy, Evaluation 클래스) 등을 지원하는 유틸리티 모음이다. Dataset.load_from_files 함수를 이용해 폴더 구조에서 텍스트와 라벨을 손쉽게 읽어올 수 있다.
논문은 세 가지 사용 예시를 제시한다. 첫 번째 예시는 기본 파라미터로 SS3 모델을 학습하고 predict 로 정확도를 출력하는 전형적인 파이썬 스크립트이다. 두 번째 예시는 학습 후 Live Test 도구를 실행해 인터랙티브하게 모델을 테스트하고, 시각적 설명을 통해 문서 내 핵심 토픽 전환을 확인한다. 세 번째 예시는 Evaluation.grid_search 메서드로 σ, λ, ρ 세 하이퍼파라미터를 그리드 탐색하고, Evaluation.plot 으로 3D 인터랙티브 플롯을 생성해 최적 파라미터 조합을 도출한다. 최적 파라미터는 set_hyperparameters 또는 새 SS3 인스턴스 생성 시 직접 적용할 수 있다.
이러한 기능들은 SS3가 원래 조기 위험 탐지에 특화된 모델이었음에도 불구하고, 일반 텍스트 분류, 감성 분석, 토픽 분류 등 다양한 NLP 작업에 손쉽게 적용될 수 있게 만든다. 특히 시각적 설명 도구는 “Explainable AI” 요구에 부합해, 모델이 왜 특정 라벨을 선택했는지 근거를 사용자에게 투명하게 제공한다. 이는 모델 신뢰성 향상과 실무 적용 시 위험 관리에 큰 도움이 된다.
결론적으로, PySS3는 SS3 모델의 핵심 아이디어를 유지하면서 파이썬 친화적인 API, 자동화된 하이퍼파라미터 탐색, 실시간 시각화 도구 등을 통합한 종합 솔루션이다. 오픈소스로 공개됨으로써 연구자와 개발자가 새로운 텍스트 분류 알고리즘을 빠르게 시험하고, 설명 가능성을 확보하며, 실제 서비스에 배포하는 과정을 크게 단축시킬 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기