데이터 기반 루프 불변식 추론의 확장성 향상
본 논문은 변수 수가 많은 프로그램에서도 데이터‑드리븐 방식으로 루프 불변식을 효율적으로 합성하기 위해, 관련 변수 탐지와 특성 생성에 머신러닝·ILP 기반 학습자를 도입한 도구 Oasis를 제안한다. 기존 LoopInvGen 대비 20 % 이상의 벤치마크를 해결하며, 정량적·정성적 평가를 통해 확장성 개선을 입증한다.
저자: Sahil Bhatia, Saswat Padhi, Nagarajan Natarajan
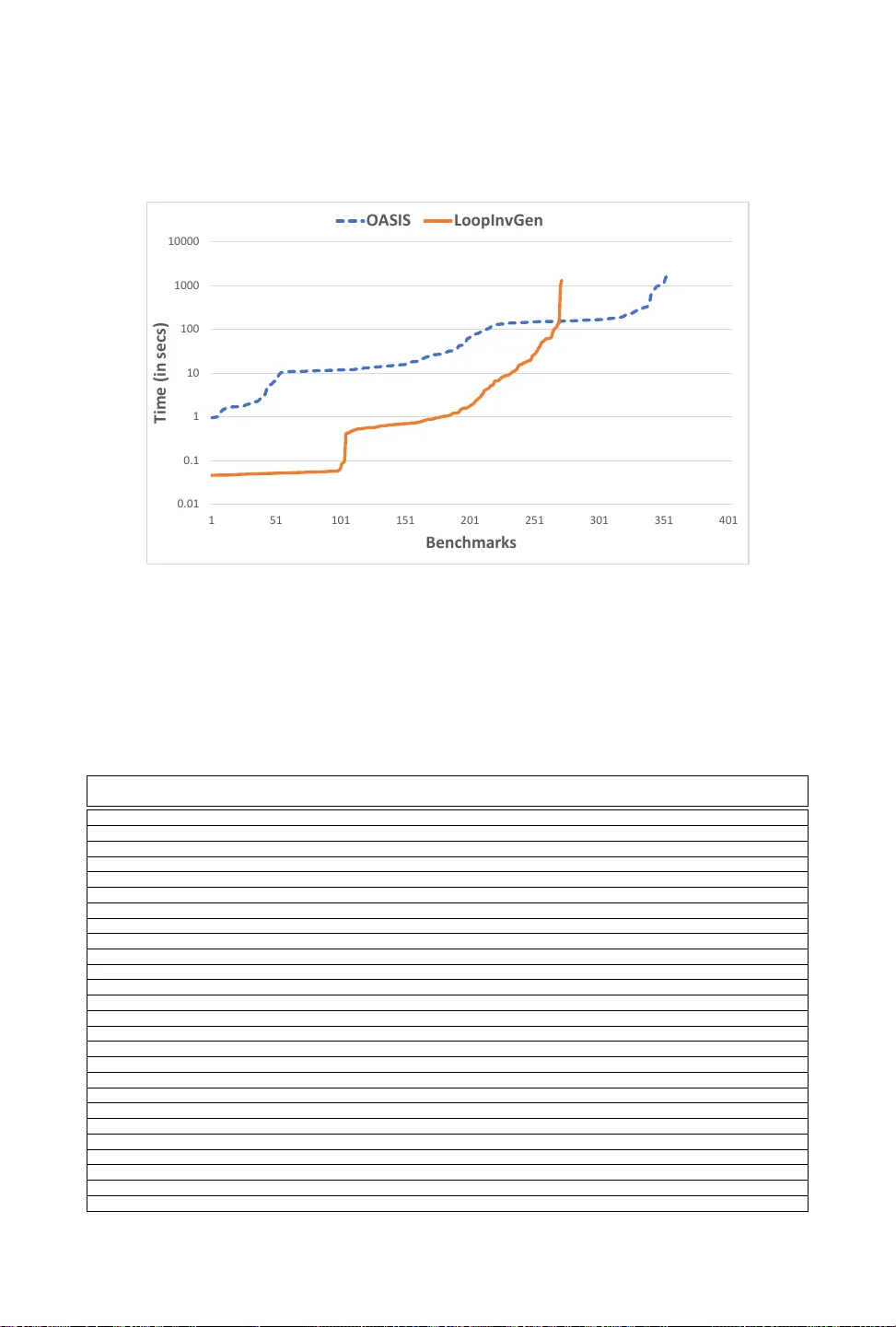
본 논문은 데이터‑드리븐 방식으로 루프 불변식을 자동 합성하는 기존 연구들이 변수 수가 적은 프로그램에만 적용 가능하다는 한계를 지적한다. 데이터‑드리븐 접근법은 학습자와 교사(teacher) 사이의 활성 학습 루프를 기반으로 하며, 학습자는 예제 집합으로부터 후보 불변식을 생성하고, 교사는 이를 검증하거나 반례를 제공한다. 변수 수가 증가하면 (1) 학습자가 부정확한 후보를 자주 생성하고, (2) 특성(피처) 열거 과정이 지수적으로 늘어나 학습·검증 비용이 급증한다.
이를 해결하기 위해 저자들은 두 가지 핵심 기술을 도입한 도구 **Oasis**(Optimization And Search for Invariant Synthesis)를 설계한다. 첫 번째 기술은 **관련 변수 탐지**이다. 프로그램의 초기 상태와 전이 관계를 이용해 양성(Reachable)과 음성(Bad) 예제를 SMT 솔버로부터 수집한다. 여기서 각 예제는 변수에 대한 부분 맵이며, ‘don’t‑care’ 변수는 값이 지정되지 않은 상태를 의미한다. 기존 머신러닝 분류기는 전체 맵을 전제로 하지만, Oasis는 부분 맵을 그대로 활용할 수 있는 맞춤형 이진 분류 학습자를 만든다. 이 학습자는 ILP(정수선형계획) 모델에 “희소성” 제약을 추가해, 가능한 최소한의 변수만을 사용해 양성 예제를 모두 포함하고 음성 예제를 배제하는 분류자를 찾는다. 결과적으로 불필요한 변수는 자동으로 제외되어, 이후 단계에서 탐색 공간이 크게 축소된다.
두 번째 기술은 **특성(피처) 합성**이다. 기존 LoopInvGen은 Escher라는 열거 기반 피처 생성기를 사용해, 모든 가능한 논리식 크기를 차례로 탐색한다. 이는 변수 수가 늘어날수록 탐색 비용이 급증한다. Oasis는 동일한 “zero‑error” 요구조건을 만족하면서도, ILP 기반 학습자를 이용해 데이터에 가장 적합한 피처를 직접 추론한다. 이때도 ‘don’t‑care’ 변수를 그대로 보존함으로써, 전체 변수 공간을 완전 탐색하지 않아도 된다. 학습자는 “모든 양성 예제는 1, 모든 음성 예제는 0”이라는 강제 제약을 갖는 ILP 모델을 풀고, 사용 변수 수를 최소화하는 목적 함수를 최적화한다.
논문은 이 두 학습자를 하나의 프레임워크에 통합하고, 이를 기반으로 LoopInvGen의 파이프라인을 개선한다. 구체적으로, (1) 관련 변수 집합을 지속적으로 갱신하면서 학습자가 제시한 분류자를 검증하고, (2) 검증이 통과하면 해당 변수 집합에 대해 수정된 LoopInvGen이 특성을 합성한다. 특성 합성 단계에서도 기존 열거 기반 대신 ILP 학습자를 사용해, 필요한 피처를 빠르게 찾아낸다. 최종적으로 Boolean 함수 학습기가 여러 피처를 결합해 전체 불변식을 구성한다.
실험에서는 SyGuS 2019 인버전 트랙에 포함된 400여 개 벤치마크를 대상으로 Oasis와 기존 도구들을 비교한다. Oasis는 변수 수가 많고 많은 불필요한 변수가 포함된 프로그램에서 특히 높은 성공률을 보였으며, 전체 벤치마크 중 20 % 이상을 기존 LoopInvGen보다 더 많이 해결했다. 또한, 연역적 합성기인 CVC4 기반 도구와 혼합형 DryadSynth보다도 더 많은 사례를 해결했으며, 동일한 문제에 대해 실행 시간도 크게 단축되었다. 특히, 변수 수가 20~30개 수준으로 늘어날 때도 학습·열거 단계가 급격히 증가하지 않아, 실질적인 확장성 향상이 입증되었다.
결론적으로, 이 논문은 (1) 부분 맵을 직접 다루는 ILP 기반 희소 이진 분류 학습자를 설계해 관련 변수를 자동 식별하고, (2) 동일한 ILP 프레임워크를 이용해 zero‑error 피처를 효율적으로 합성함으로써, 데이터‑드리븐 루프 불변식 추론의 확장성을 크게 개선한다는 중요한 기여를 한다. 향후 연구에서는 더 복잡한 데이터 타입(예: 배열, 포인터)과 다중 루프 구조에 대한 적용 가능성을 탐색하고, ILP 솔버와 학습 알고리즘의 병렬화·분산화를 통해 더욱 큰 규모의 프로그램 검증에 도전할 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기