비디오 압축을 위한 혁신적인 CNN 구조 MFRNet
초록
MFRNet은 다중 레벨 특징 재검토와 잔차 밀집 블록을 결합한 새로운 CNN 아키텍처로, HEVC와 VVC의 포스트‑프로세싱 및 인‑루프 필터링에 적용되어 기존 방법 대비 PSNR·VMAF 기준 최대 21 %까지 BD‑Rate 감소를 달성한다.
상세 분석
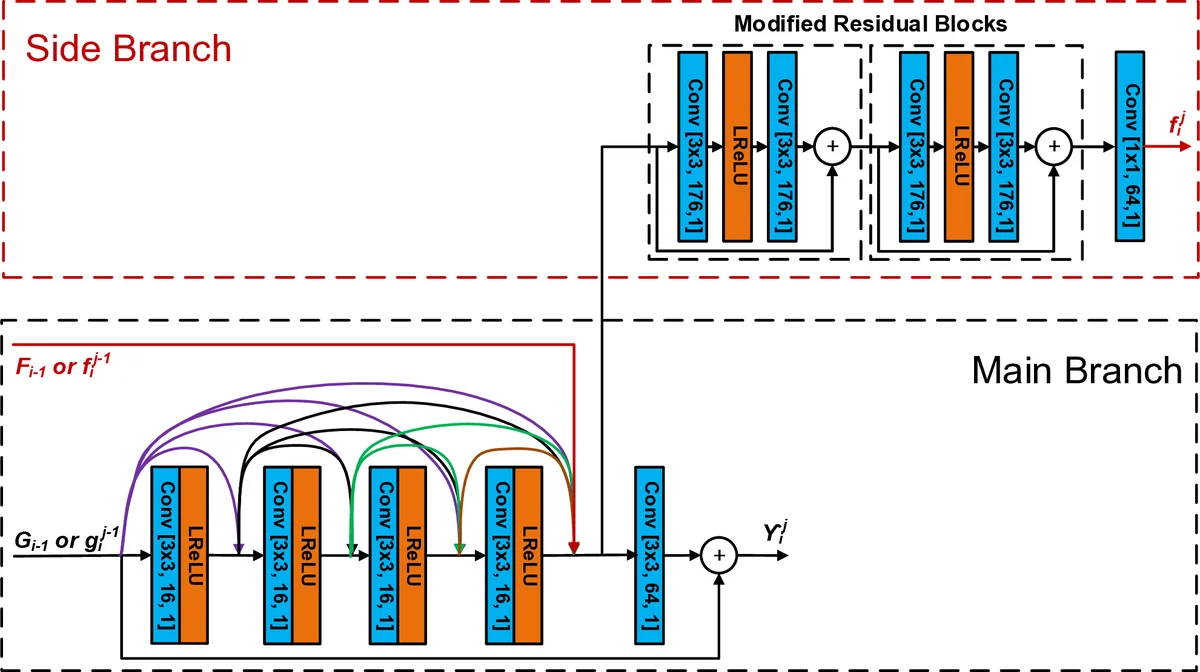
본 논문은 최신 비디오 코덱인 HEVC(HM 16.20)와 VVC(VTM 7.0)의 포스트‑프로세싱(PP) 및 인‑루프 필터링(ILF) 단계에 특화된 CNN 구조인 MFRNet을 제안한다. MFRNet의 핵심은 네 개의 Multi‑level Feature Review Residual dense Block(MFRB)으로 구성된 계층적(cascading) 구조이며, 각 MFRB는 세 개의 Feature Review Residual dense Block(FRB)으로 세분화된다. 기존 Residual dense block(RDB)과 달리 FRB는 메인 브랜치와 사이드 브랜치를 동시에 갖고, 이전 블록에서 생성된 고차원 특징(HDF)을 재사용하도록 설계되었다. 이를 통해 정보 흐름이 다중 경로로 확장되어 특징 소실을 최소화하고, 학습 안정성을 높인다.
MFRNet은 입력으로 96×96 크기의 YCbCr 4:4:4 패치를 받아 얕은 특징 추출 레이어(LReLU 활성화) 후 네 개의 MFRB를 순차적으로 통과시킨다. 각 MFRB 사이에는 1×1 컨볼루션을 통한 캐스케이딩 연결이 존재해 얕은 특징과 이전 MFRB의 출력(G₁, G₂, G₃)을 다음 블록에 전달한다. 또한, 첫 세 개 MFRB는 고차원 특징(F₁, F₂, F₃)을 다음 MFRB에 전달함으로써 특징 재검토(feature review) 메커니즘을 구현한다. 네 개의 MFRB와 첫 번째 복원 레이어(RL1) 후에는 스킵 연결을 적용해 입력 얕은 특징과 결합하고, 최종 복원 레이어(RL2)와 출력 레이어를 거쳐 잔차 신호를 생성한다. 최종 출력은 입력 패치와 잔차를 더해 고품질 복원 영상을 만든다.
학습은 BVI‑DVC 데이터베이스와 추가적인 고해상도 영상들을 활용해 L1 손실과 VMAF 기반 손실을 혼합한 다중 목표 함수를 사용한다. 학습 과정에서 데이터 증강, 배치 정규화, 그리고 Adam 옵티마이저를 적용해 수렴 속도를 높였다.
실험은 JVET Common Test Conditions의 Random Access(RA) 설정을 기준으로 진행했으며, HEVC와 VVC 각각에 MFRNet 기반 PP와 ILF를 삽입한 4가지 변형을 평가했다. 결과는 BD‑Rate 기준 PSNR와 VMAF 모두에서 기존 CNN 기반 방법(예: VRCNN, DRN, ResNet 등)보다 일관되게 우수했으며, 특히 HEVC ILF에서 VMAF 기준 최대 16 %·PP에서 21 %의 감소를 기록했다. VVC에서도 ILF에서 5.1 %, PP에서 7.1 %의 개선을 보였다.
또한, 동일 학습·평가 환경에서 13개의 대표적인 CNN 구조(AlexNet, VGG, ResNet, DenseNet 등)를 비교했을 때, MFRNet이 파라미터 수는 비슷하거나 약간 높지만, 재현성, 수렴 속도, 그리고 최종 코딩 효율성 면에서 전반적으로 우수함을 확인했다. 이는 다중 레벨 특징 재검토와 잔차 밀집 연결이 비디오 복원 작업에 특화된 특징 추출 능력을 크게 향상시킨 결과로 해석된다.
본 연구는 CNN 기반 비디오 코덱 개선에 있어 네트워크 설계 단계에서 정보 흐름을 어떻게 최적화할 수 있는지를 보여주는 좋은 사례이며, 향후 실시간 인코더/디코더에 적용하기 위한 경량화 및 하드웨어 최적화 연구가 필요함을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기