혼합 정밀도 연산을 활용한 수치 방법 종합 조사
초록
본 보고서는 Exascale Computing Project의 멀티프리시전 팀이 수행한 조사로, 최신 하드웨어에서 제공되는 반정밀도(FP16·bfloat16)와 텐서 코어 등 저정밀 연산 유닛을 활용한 다양한 수치 선형대수 알고리즘을 정리한다. 저정밀 BLAS, 혼합 정밀도 반복 정제, GMRES‑IR, 혼합‑정밀도 분해·특이값·고유값 해법, 데이터·통신 압축, 희소 행렬 직접·반복 해법, 프리컨디셔너, 그리고 xSDK 라이브러리와의 연동까지 포괄적으로 다루며, 성능·정밀도 트레이드오프와 향후 연구 과제를 제시한다.
상세 분석
최근 머신러닝·AI 수요에 대응해 NVIDIA, AMD, Google 등 주요 벤더가 FP16·bfloat16과 같은 저정밀 특수 연산 유닛을 상용화하면서, 전통적인 64‑bit 연산 중심의 수치 소프트웨어 스택에 큰 변화를 요구하고 있다. 특히 NVIDIA V100·A100 등 Volta·Ampere 아키텍처는 텐서 코어를 통해 4×4·4 매트릭스 곱을 FP16 입력·FP32 출력 형태로 수행할 수 있으며, 이론상 FP32 대비 8~12배의 연산량을 제공한다. 이러한 하드웨어 특성을 활용하기 위해 보고서는 저정밀 BLAS, 특히 HGEMM(half‑precision GEMM)과 배치 HGEMM을 중심으로 성능·정밀도 분석을 제시한다. 실험 결과, 텐서 코어를 활성화한 FP16 입력·FP32 출력 GEMM은 비활성화 시보다 2배 이상의 정확도를 유지하면서 5배 이상의 처리량을 달성한다는 점이 강조된다.
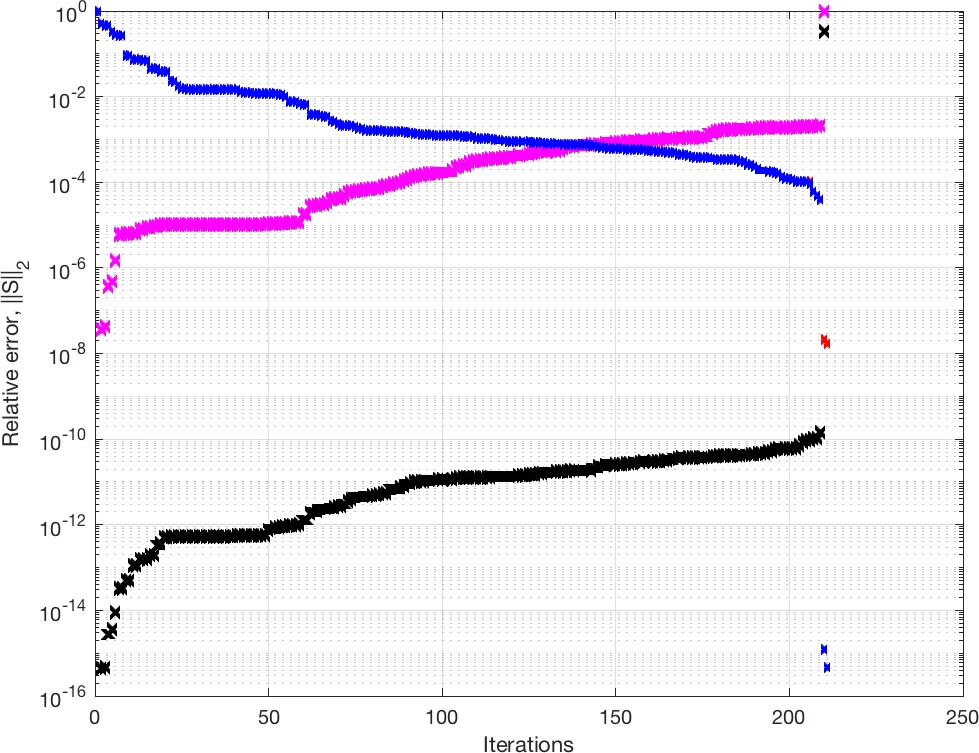
혼합 정밀도 알고리즘의 핵심 아이디어는 저정밀 연산으로 초기 해를 빠르게 구한 뒤, 고정밀(주로 FP64) 반복 정제를 통해 최종 정확도를 회복하는 것이다. 보고서는 고전적 반복 정제(classical iterative refinement)와 GMRES‑IR(Iterative Refinement) 방식을 상세히 설명하고, 스케일링·시프팅 기법을 통해 수치적 안정성을 확보하는 방법을 제시한다. 또한, 혼합 정밀도 LU·Cholesky·QR 분해, 양자화 정수 LU, 대칭 고유값 문제 등 다양한 행렬 분해 기법에 대한 구현 현황과 성능 결과를 제시한다. 특히 양자화 정수 LU는 8‑bit 정수 연산으로 메모리 대역폭을 크게 절감하면서도, 적절한 스케일링·시프팅을 통해 실용적인 정확도를 얻을 수 있음을 보여준다.
데이터·통신 압축 파트에서는 mixed‑precision MPI, 근사 FFT, 동적 스플리팅 등 메모리·네트워크 비용을 낮추는 기술을 소개한다. 특히 mixed‑precision MPI는 전송 데이터의 일부를 저정밀 형식으로 변환해 전송량을 절감하고, 수신 측에서 고정밀 복원을 수행함으로써 전체 통신 비용을 크게 감소시킨다.
희소 행렬 분야에서는 멀티프리시전 LU·QR, 직접 해법, 그리고 Krylov 서브스페이스 메서드(Lanczos‑CG, Arnoldi‑GMRES 등)의 혼합 정밀도 구현을 다룬다. 이들 방법은 저정밀 행렬-벡터 곱을 이용해 메모리 대역폭을 절감하고, 고정밀 재정밀도 단계에서 수렴성을 보장한다. 특히 GMRES‑IR은 저정밀 사전조건자와 결합했을 때, 기존 FP64 GMRES 대비 2~3배의 속도 향상을 기록한다.
프리컨디셔너 섹션에서는 멀티그리드, 대역폭 제한을 고려한 저정밀 스무딩, 그리고 다중 정밀도 전처리기의 설계 원칙을 제시한다. 여기서 핵심은 연산과 메모리 포맷을 분리(decoupling)함으로써, 예를 들어 저정밀 스무딩 단계에서는 FP16을, 교정 단계에서는 FP64를 사용하는 전략이다.
마지막으로 xSDK 생태계(Ginkgo, hypre, Kokkos Kernels, MAGMA, PETSc 등)와의 연동 상황을 정리하고, IEEE‑754 포맷 에뮬레이터와 라운딩 오류 분석을 통해 혼합 정밀도 알고리즘의 이론적 근거를 제공한다. 전체적으로 보고서는 하드웨어 트렌드와 소프트웨어 스택을 연결하는 교량 역할을 수행하며, 향후 Exascale 수준의 애플리케이션에서 혼합 정밀도가 차지할 비중을 전망한다.
댓글 및 학술 토론
Loading comments...
의견 남기기