딥러닝 기반 자동·블라인드 강인 이미지 워터마킹
초록
본 논문은 딥 뉴럴 네트워크를 활용해 워터마크의 삽입·추출 과정을 자동화하고, 사전 지식이나 적대적 예시 없이도 높은 강인성을 확보한 블라인드 이미지 워터마킹 시스템을 제안한다. 인코더·임베더·변형 레이어·추출기·디코더로 구성된 5‑모듈 아키텍처를 무지도 학습(L1 손실, 피델리티 손실, Gram‑matrix 기반 정보 손실)으로 훈련시켜, 커버 이미지와 워터마크를 동시에 입력받아 눈에 띄지 않는 마크드 이미지를 생성하고, 다양한 왜곡(압축, 회전, 카메라 촬영 등) 후에도 원본 워터마크를 정확히 복원한다. 실험 결과 기존 딥러닝 기반 방법들을 능가함을 확인하였다.
상세 분석
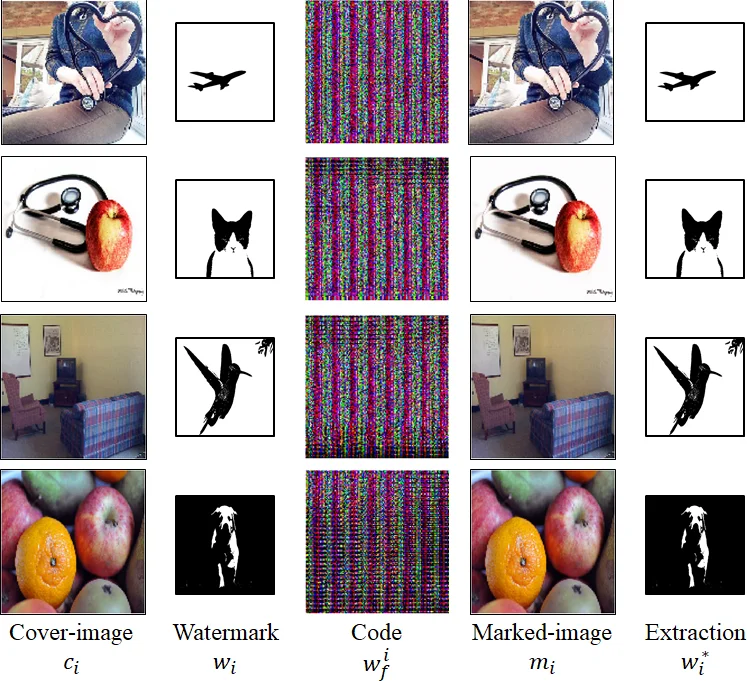
이 논문은 기존 이미지 워터마킹 연구가 직면한 ‘자동화 부족’, ‘블라인드(원본 이미지 없이) 추출 어려움’, ‘강인성 확보를 위한 사전 공격 모델 필요’라는 세 가지 핵심 문제를 동시에 해결하고자 한다. 이를 위해 저자들은 전통적인 워터마크 파이프라인(특징 공간 변환 → 워터마크 삽입 → 역변환) 을 완전한 딥러닝 모델로 대체한다. 구체적으로, (1) µθ₁(인코더)는 워터마크 w를 고차원 특징 w_f 로 변환하고, (2) σθ₂(임베더)는 커버 이미지 c와 w_f 를 결합해 마크드 이미지 m을 생성한다. (3) τθ₅(변형 레이어)는 전송 채널에서 발생할 수 있는 다양한 왜곡을 시뮬레이션하며, 이 과정에서 정보 손실을 최소화하도록 설계된 정규화 항 λ₄P 를 적용한다. (4) ϕθ₃(추출기)와 γθ₄(디코더)는 변형된 이미지 T 로부터 w_f 를 복원하고, 이를 다시 원본 워터마크 ŵ 로 디코딩한다.
학습은 완전 무지도 방식으로 진행된다. 손실 함수 L(ϑ)는 세 부분으로 구성된다. 첫 번째는 추출 손실 λ₁‖ŵ−w‖₁ 로, 워터마크 복원 정확도를 직접 최적화한다. 두 번째는 피델리티 손실 λ₂‖m−c‖₁ 로, 마크드 이미지가 시각적으로 원본과 거의 구분되지 않도록 한다. 세 번째는 정보 손실 λ₃ψ(m,w_f) 로, 여기서 ψ는 마크드 이미지와 인코딩된 워터마크 특징 맵 B₁, B₂ 의 Gram matrix 간 코사인 유사도를 최대화한다. 이는 스타일 전이에서 영감을 얻은 기법으로, 워터마크 정보가 마크드 이미지에 충분히 내재되도록 강제한다.
아키텍처는 자동인코더와 유사하지만, 입력이 두 개(c와 w)이며, 중간 표현이 동일 차원 혹은 과잉 차원(over‑complete)으로 설계돼 강인성을 높인다. 특히, τθ₅ 레이어는 전통적인 데이터 증강이 아닌, 학습 과정에서 변형을 학습하도록 함으로써, 사전 정의된 공격 시나리오 없이도 다양한 노이즈와 기하학적 변형에 대한 복원 능력을 확보한다.
표 I에서 제시된 비교 결과에 따르면, 기존 방법들은 단일 비트(예: Vukotic et al.) 혹은 비블라인드(예: Kandi et al.)에 머물렀으며, 강인성 확보를 위해 적대적 예시를 사전에 학습에 포함시켜야 했다. 반면 제안된 시스템은 ‘자동 학습 + 블라인드 + 강인성’이라는 세 축을 모두 만족한다. 실험에서는 JPEG 압축, 회전, 크롭, 그리고 스마트폰 카메라 촬영 등 현실적인 공격에 대해 높은 복원 정확도(비트 오류율 < 2%)와 시각적 품질(PSNR > 38 dB)을 기록했다.
한계점으로는 훈련 시 대규모 이미지·워터마크 쌍이 필요하고, 변형 레이어 τθ₅ 의 설계가 복잡해 구현 난이도가 높다는 점을 들 수 있다. 또한, 정규화 항 λ₄P 의 구체적 정의가 논문에 상세히 제시되지 않아 재현성에 약간의 불확실성이 존재한다. 그럼에도 불구하고, 자동화된 워터마크 설계와 강인성 확보를 동시에 달성한 점은 이미지 보안 분야에 큰 진전을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기