협동 멀티에이전트 강화학습을 위한 보상 머신 분해
초록
보상 머신(RM)을 팀 과업의 구조화된 표현으로 활용해, 협동 MARL에서 팀 과업을 개별 에이전트의 하위 과업으로 분해한다. 제안된 분해 조건 하에 각 에이전트가 로컬 RM을 학습하면 전체 팀 목표를 보장할 수 있으며, 이를 기반으로 분산 Q‑학습 알고리즘을 설계한다. 실험 결과, 중앙집중식 학습보다 10배 이상 빠르게 수렴하고 기존 계층형·독립 Q‑학습보다 우수한 성능을 보였다.
상세 분석
이 논문은 협동형 다중 에이전트 강화학습(MARL)에서 발생하는 두 가지 핵심 난제, 즉 에이전트 간의 협조와 비정상성을 해결하기 위해 보상 머신(Reward Machine, RM)을 도입한다. RM은 Mealy 머신 형태의 유한 상태 자동화로, 환경 이벤트에 따라 상태 전이와 보상을 정의한다. 기존 연구에서는 RM을 단일 에이전트의 보상 함수 대체 수단으로 사용했지만, 저자들은 이를 팀 수준의 과업을 기술하는 메타 모델로 확장한다.
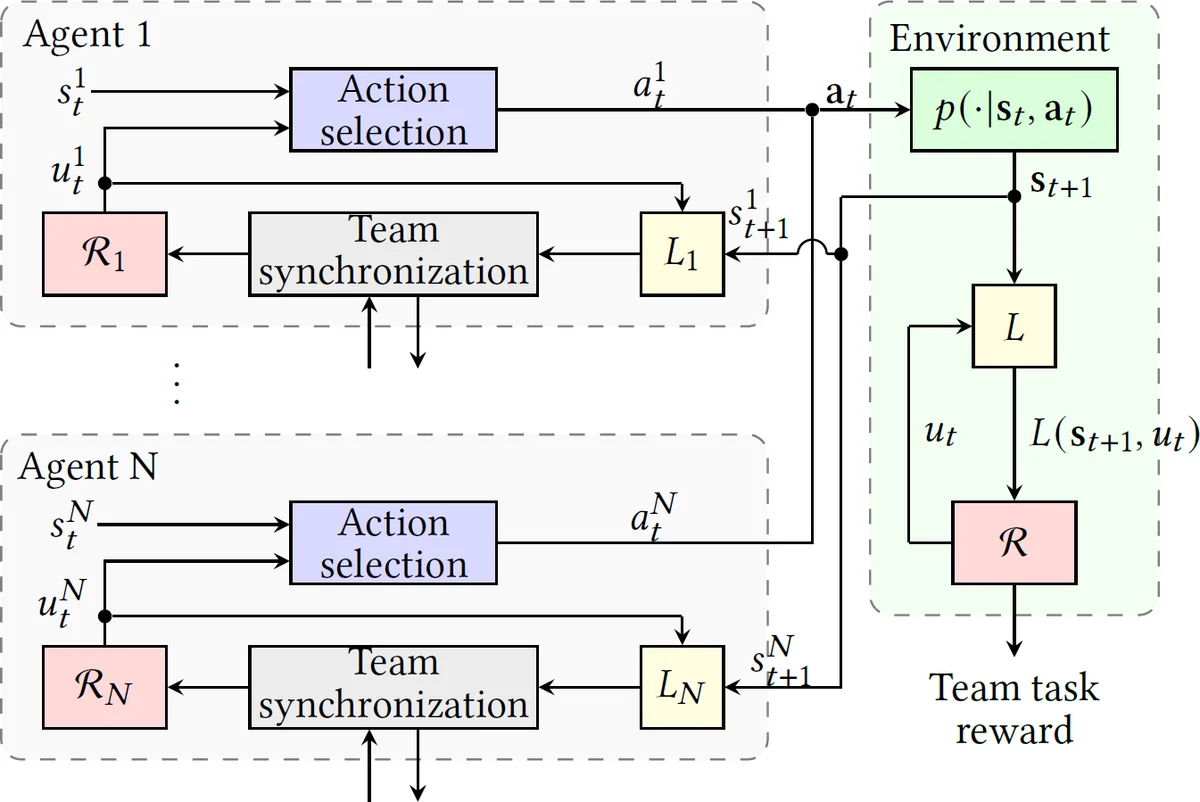
핵심 아이디어는 팀 과업을 기술하는 하나의 전역 RM을 에이전트별 로컬 이벤트 집합 Σ_i에 투사(projection)하여 각 에이전트마다 부분 RM R_i를 만든다. 이때 상태 동등성 관계 ∼_i 를 정의해, 로컬 이벤트와 무관한 전이들은 같은 동등 클래스에 묶는다. 이렇게 하면 각 R_i는 원래 전역 RM과 동형(bisimulation) 관계를 유지하면서도 에이전트가 관찰할 수 있는 정보만을 포함한다.
논문은 두 가지 중요한 정리를 제시한다. 첫째, RM 분해 가능성 조건(state‑equivalence 기반) 하에, 모든 에이전트가 자신의 R_i 를 완수하면 전체 팀 과업이 완수된다는 완전성 보장이다. 둘째, 비감가 보상 상황에서 로컬 가치 함수 Q_i 를 이용해 전역 가치 함수 V에 대한 하한·상한을 구함으로써, 분산 학습이 전역 최적성에 얼마나 근접하는지 정량적으로 평가한다.
알고리즘적 측면에서는 기존 Q‑Learning with Reward Machines(QRM)을 각 에이전트에 적용한 분산 QRM(Decentralized QRM) 을 설계한다. 에이전트 i는 자신의 로컬 상태 s_i 와 현재 RM 상태 u_i 에서 행동을 선택하고, 환경 전이 후 라벨링 함수 L_i(s’,u_i) 로부터 이벤트 집합을 받아 로컬 RM을 전이시킨다. 업데이트는 전역 QRM과 동일한 TD‑오차를 사용하지만, 카운터팩추얼 업데이트를 통해 다른 RM 상태에서도 발생할 수 있었던 보상을 동시에 학습한다. 이 설계는 에이전트 간 직접적인 정책 교환 없이도 협조적 행동을 유도한다.
실험은 세 가지 이산 도메인(두‑에이전트·십‑에이전트 버튼 과업, 그리고 추가적인 격자 세계)에서 수행되었다. 특히 10‑에이전트 버튼 과업에서는 중앙집중식 QRM이 학습 단계 제한 내에 수렴하지 못하는 반면, 제안된 분산 QRM은 빠르게 성공적인 팀 정책을 획득한다. 또한, 계층형 독립 Q‑학습(h‑IL)과 독립 Q‑학습(IQL)과 비교했을 때, 수렴 속도와 최종 성공률 모두 유의미하게 우수함을 보였다.
이 논문의 기여는 (1) RM 기반 팀 과업의 형식적 분해 이론, (2) 로컬 이벤트 집합에 기반한 상태 동등성 정의, (3) 이를 활용한 분산 Q‑학습 알고리즘, 그리고 (4) 실험을 통한 실용성 검증에 있다. 특히 비정상성 문제를 라벨링과 로컬 RM 전이로 캡슐화함으로써, 에이전트가 서로의 정책 변화를 직접 관측하지 않아도 협조적 행동을 학습할 수 있다는 점이 혁신적이다. 향후 연속 상태·액션 공간, 부분 관측 마크오프 게임, 그리고 동적 팀 구성에 대한 확장 가능성도 논문에서 언급되어, 연구의 파급력이 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기