HPC AI500: 차세대 HPC AI 시스템 벤치마크 방법론 및 성능 모델
초록
본 논문은 대규모 분산 딥러닝 워크로드를 위한 HPC AI 시스템을 공정하고 재현 가능하게 평가하기 위해, 9계층 구조와 명확한 벤치마크 규칙을 제시한다. AIBench 기반의 이미지 분류와 극한 기상 분석 두 워크로드를 선정하고, 품질 보장을 위한 ‘Valid FLOPS’와 ‘Valid FLOPS per Watt’ 지표를 도입한다. 또한 Convolution·GEMM 중심의 Roofline 모델을 통해 시스템 최적화를 가이드한다.
상세 분석
이 논문은 최근 AI 워크로드가 HPC 영역으로 확장됨에 따라 기존 TOP500·HPL‑AI와 같은 전통적인 벤치마크가 갖는 한계를 정확히 짚어낸다. 특히 “동등성(equivalence)”, “대표성(representativeness)”, “경제성(affordability)”, “반복성(repeatability)” 네 가지 핵심 요구사항을 동시에 만족시키는 프레임워크가 부재함을 지적하고, 이를 해결하기 위해 9개의 독립 레이어(하드웨어, 시스템, 프레임워크, 알고리즘 등)를 정의한다. 각 레이어는 다른 레이어를 고정한 채 개별적으로 테스트할 수 있도록 설계돼, 하드웨어 변화가 소프트웨어 스택에 미치는 영향을 명확히 분리한다.
벤치마크 규칙에서는 레이어별 허용 가능한 변경사항을 명시함으로써, 예를 들어 데이터 병렬성, 학습률 정책, 배치 크기 등은 변동 가능하지만, 모델 아키텍처나 데이터셋, 목표 품질 등은 고정한다. 이는 동일한 워크로드가 서로 다른 시스템에서 동일한 품질을 달성했는지 여부를 객관적으로 판단하게 한다.
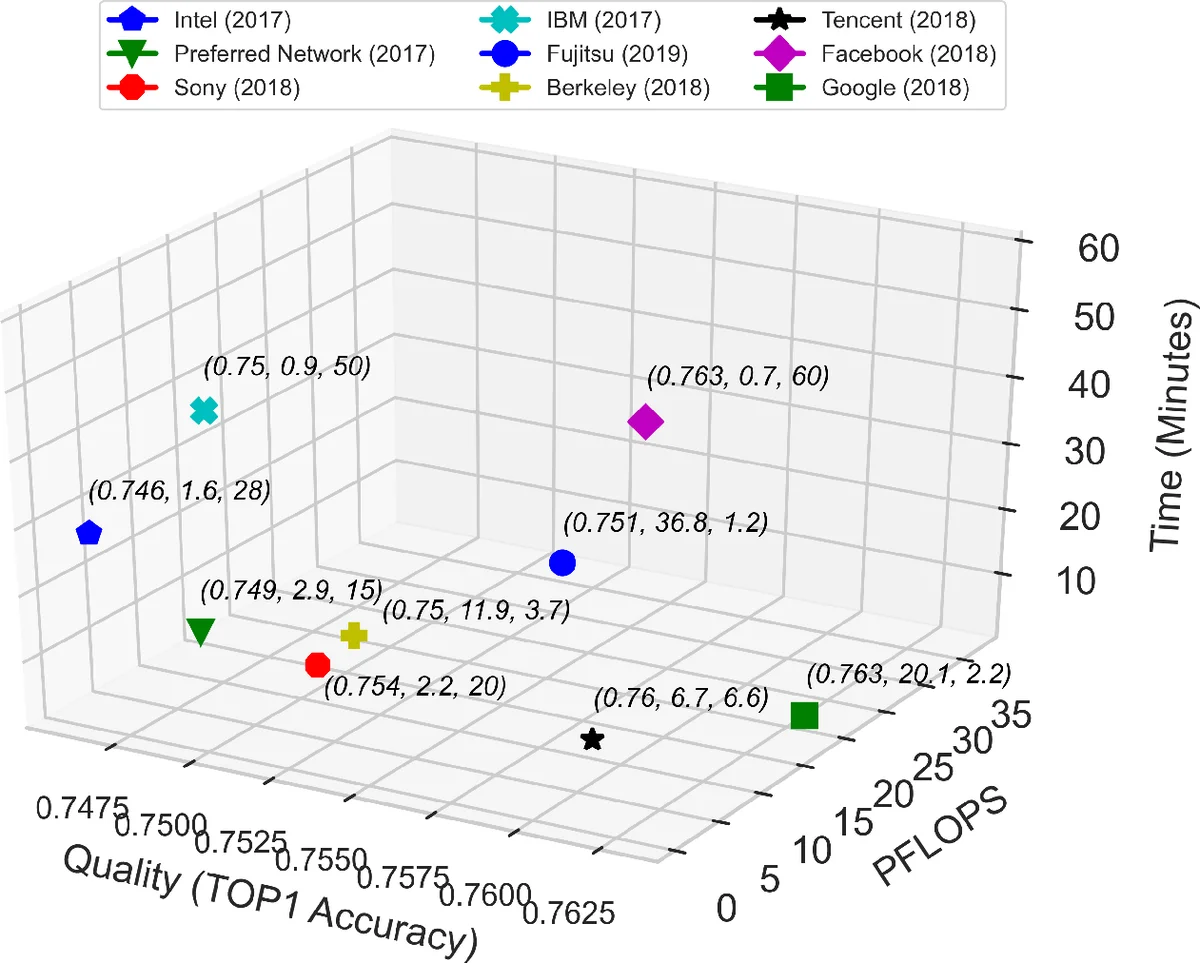
대표 워크로드로 선택된 ImageNet‑ResNet‑50 기반 이미지 분류와 극한 기상 분석(EWA)은 각각 비즈니스와 과학 컴퓨팅을 대변한다. 두 워크로드는 모델 파라미터 수(0.03M68.39M), 연산량(0.09 MFLOP157.8 GFLOP), 수렴 에폭(6~304) 등에서 폭넓은 스펙트럼을 커버한다. 특히 EWA는 기후 시뮬레이션 데이터와 복합적인 전처리 파이프라인을 포함해, 과학 워크로드 특유의 대규모 입출력 및 연산 패턴을 반영한다.
핵심 성능 지표인 Valid FLOPS는 “품질 달성 여부”에 페널티를 부여한다. 즉, 목표 정확도에 도달하지 못하면 실제 FLOPS가 감소된 것으로 계산해, 단순히 연산량만을 강조하는 기존 FLOPS와 차별화한다. Valid FLOPS per Watt는 에너지 효율까지 고려해, 친환경 HPC AI 시스템 평가에 활용 가능하다.
또한, Convolution과 GEMM을 “상한 성능” 측정용 마이크로 벤치마크로 채택하고, 이를 기반으로 단일 노드와 분산 시스템용 Roofline 모델을 구축한다. Roofline 모델은 메모리 대역폭, 연산 집약도, 통신 비용 등을 시각화해, 병목 현상을 빠르게 파악하고 최적화 방향을 제시한다. 실험 결과, 제안된 모델이 실제 시스템에서의 최적화 효과를 정확히 예측함을 보였다.
전체 평가에서는 HPC AI500 V2.0이 기존 벤치마크 대비 1) 동일 품질을 보장하면서 2) 구현·운용 비용을 크게 낮추고 3) 결과 재현성을 확보한다는 점을 입증한다. 공개된 코드와 데이터셋을 통해 연구 커뮤니티가 손쉽게 벤치마크를 확장·재현할 수 있도록 지원한다는 점도 큰 장점이다.
댓글 및 학술 토론
Loading comments...
의견 남기기