무작위 롤아웃 정책 경사법으로 지역 최적 정책에 전역 수렴
본 논문은 무한히 긴 할인 MDP에서 정책 경사법(PG)의 전역 수렴성을 비볼록 최적화 관점에서 분석한다. 랜덤 롤아웃 길이를 이용해 편향 없는 정책 그라디언트 추정기를 설계하고, 이를 기반으로 기본 RPG와 주기적으로 스텝 사이즈를 확대하는 변형 MRPG를 제안한다. 기본 알고리즘은 확률적 1차 최적화 이론에 따라 정지점(gradient =0)으로 수렴함을 보이며, 변형 알고리즘은 보상 함수가 양(음)으로 제한되고 정책 파라미터가 정규(Fis…
저자: Kaiqing Zhang, Alec Koppel, Hao Zhu
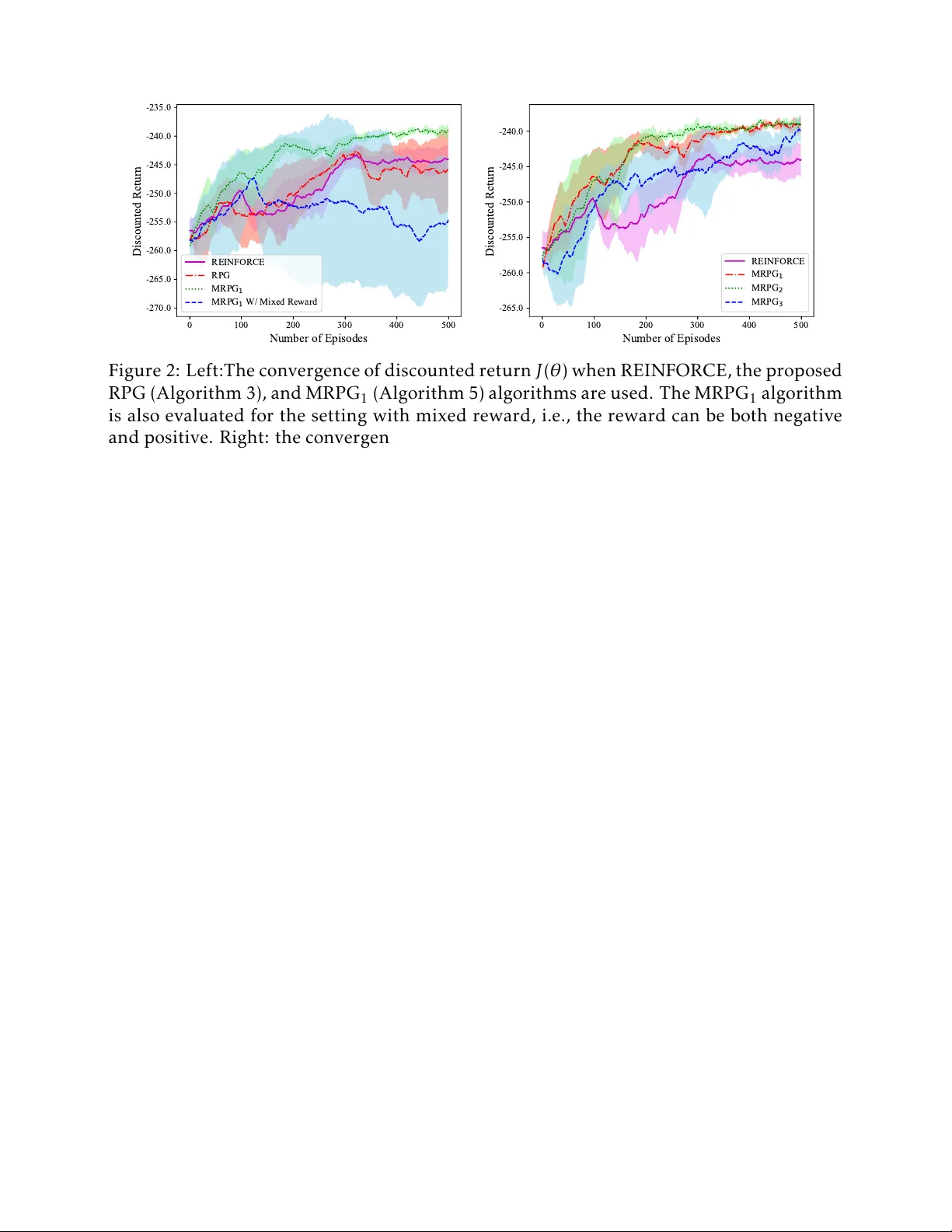
**1. 연구 배경 및 문제 정의**
강화학습(RL)에서 에이전트는 마코프 결정 과정(MDP) 내에서 상태 s∈S와 행동 a∈A를 선택하고, 즉시 보상 r=R(s,a)를 받으며 다음 상태로 전이한다. 목표는 초기 상태 s₀에서 장기 할인 보상 Vπ(s₀)=E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기