강화학습 기반 로봇 군집 목표 분포 유도
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
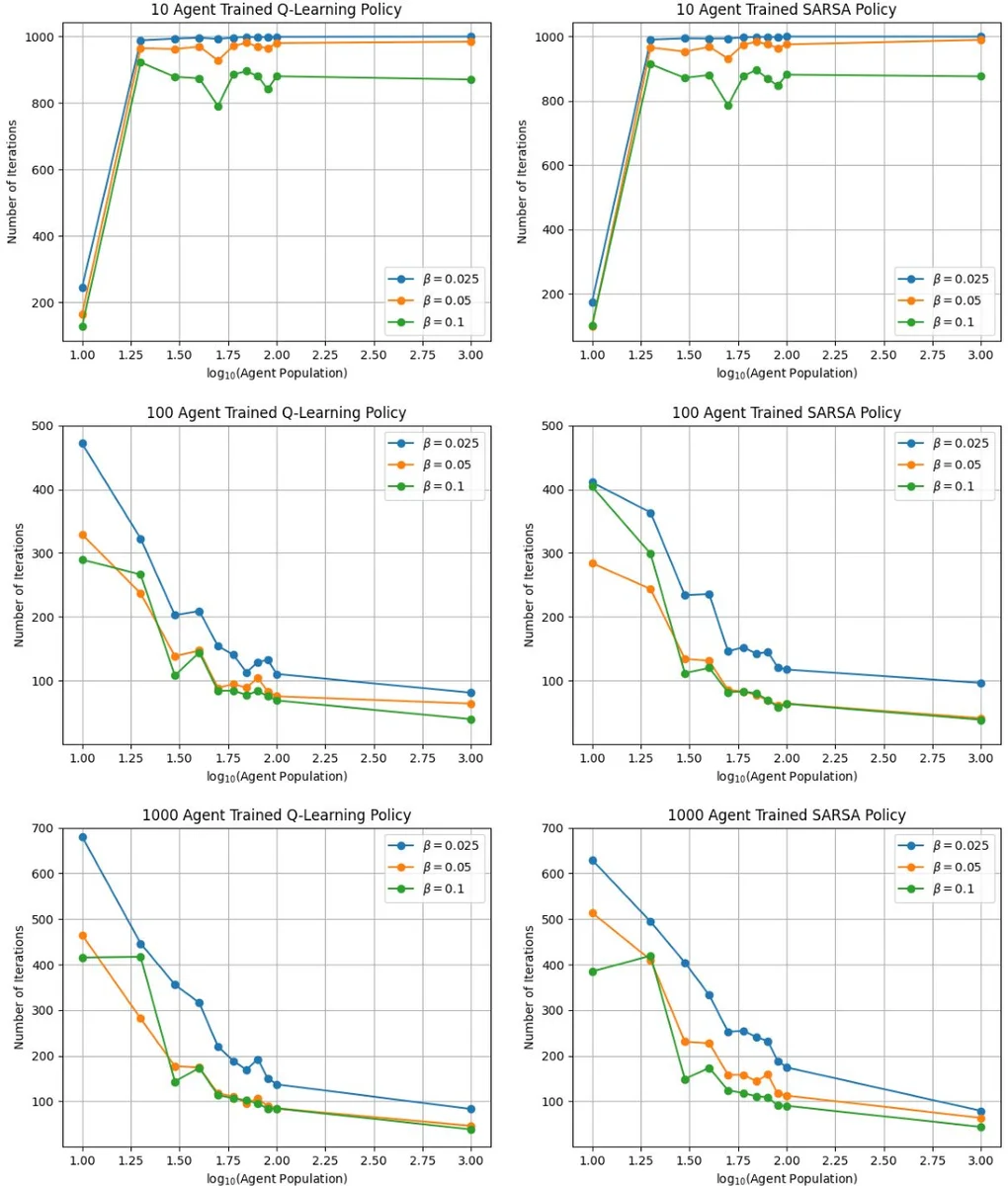
본 논문은 리더 로봇이 팔로워 로봇 군집을 그래프 상의 목표 확률 분포로 빠르게 수렴시키는 강화학습 제어 정책을 제시한다. 평균장 모델을 이용해 군집의 분포를 상태로 정의하고, SARSA와 Q‑Learning을 통해 리더의 이동·행동 정책을 학습한다. 4개의 정점으로 구성된 격자 그래프에서 시뮬레이션을 수행했으며, 10~100대의 가상 로봇뿐 아니라 실제 10대 로봇 실험에서도 목표 분포 달성에 성공하였다.
상세 분석
이 연구는 로봇 군집 제어에서 스케일러빌리티와 모델‑프리 학습을 동시에 달성하려는 시도로, 기존의 리더‑팔로워 접근법과 차별화된다. 먼저, 팔로워들의 개별 상태가 아니라 각 정점에 존재하는 인구 비율을 평균장(Mean‑Field) 변수 ˆS(k) 로 정의함으로써 상태 차원을 M 차원(그래프 정점 수)으로 축소한다. 이 평균장 변수는 N→∞ 한계에서 결정론적 차분 방정식(6)으로 기술되며, 리더의 행동에 따라 전이 확률 u_e(k) 가 변한다. 리더는 현재 위치 1(k)와 행동 상태 2(k) (0 또는 1) 를 포함한 복합 상태 (ˆS(k), `1(k)) 를 관찰하고, 이를 기반으로 정책 π: P(V)×V→A 를 선택한다. 여기서 A는 현재 정점에서 가능한 이동·정지 행동 집합이다.
강화학습 부분에서는 SARSA와 Q‑Learning 두 가지 TD(Temporal‑Difference) 알고리즘을 적용한다. 연속적인 인구 비율을 D개의 구간으로 양자화하고 정수형 F_v 로 변환해 상태 벡터 S_env =
댓글 및 학술 토론
Loading comments...
의견 남기기