Ginkgo를 AMD GPU에 맞추다 — CUDA‑HIP 전환 실전 가이드
초록
본 논문은 오픈소스 선형대수 라이브러리 Ginkgo에 AMD GPU용 HIP 백엔드를 추가한 과정을 상세히 기술한다. CUDA 코드를 HIP로 포팅하면서 발생한 기능 격차(특히 cooperative groups)와 이를 직접 구현한 방법, 코드 중복을 최소화하기 위한 공통 모듈 설계, 그리고 NVIDIA와 AMD 양쪽에서의 성능 평가 결과를 제시한다.
상세 분석
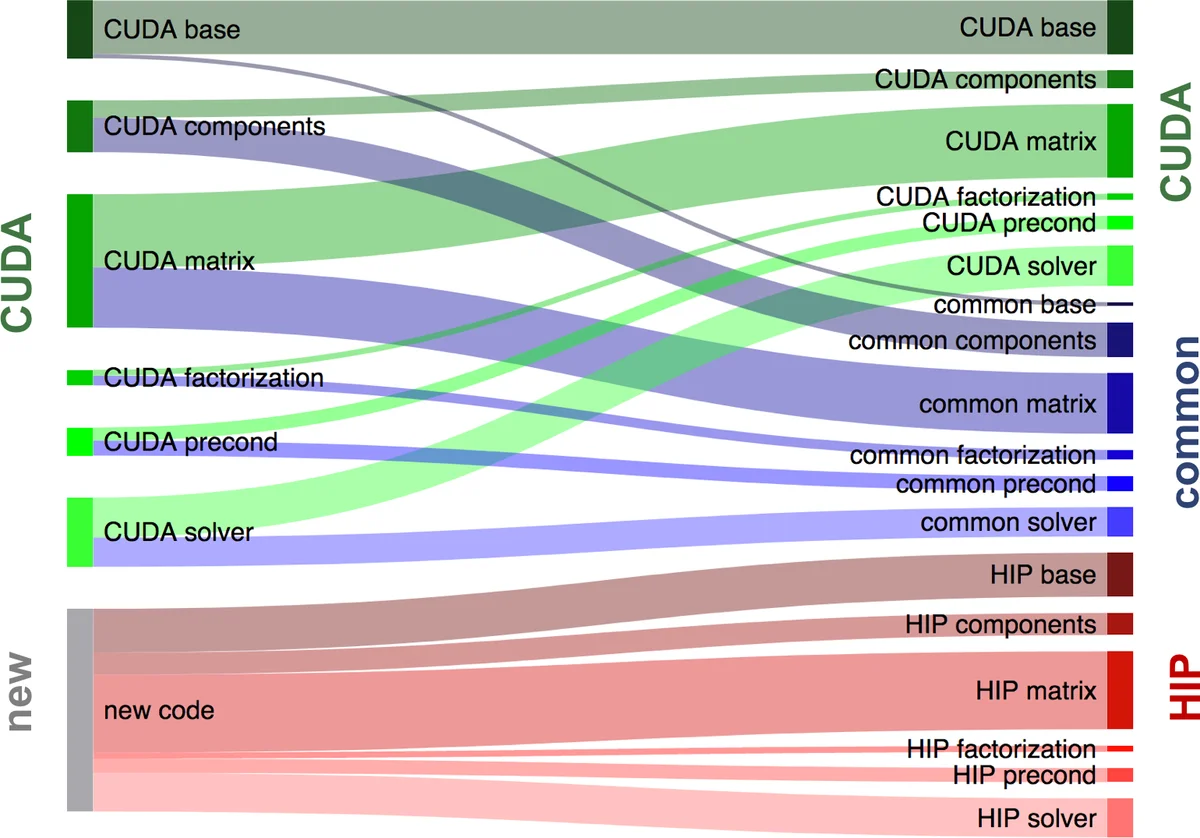
Ginkgo는 기존에 CUDA, OpenMP, CPU reference 구현을 제공하던 고성능 희소 선형대수 라이브러리이다. AMD의 ROCm·HIP 생태계가 점차 HPC 영역으로 확대됨에 따라, 저자들은 CUDA 전용 코드를 HIP로 이식하는 전 과정을 체계화하였다. 가장 큰 기술적 난관은 HIP가 CUDA와 1:1 대응되지 않는 기능, 특히 warp‑level cooperative groups와 sub‑warp shuffle, ballot 연산을 제공하지 않는 점이었다. 이를 해결하기 위해 저자들은 HIP 전용 서브‑warp 그룹 클래스를 구현하고, CUDA의 __shfl_xor, __ballot 등을 비트 마스크와 popcnt 연산을 조합해 재현하였다. 구현 시 warp size 차이(AMD 64, NVIDIA 32)를 고려해 lane mask 타입을 추상화하고, 32‑bit·64‑bit 정수에 대한 popcnt 오버로드를 제공함으로써 아키텍처 독립성을 확보했다.
코드 중복 방지를 위한 설계는 “common” 디렉터리에 CUDA와 HIP 양쪽에서 동일하게 사용할 수 있는 커널 로직을 배치하고, 백엔드별로 launch 파라미터(warp size, launch bounds 등)만을 별도 파일에서 지정하도록 한 점이 핵심이다. 이 구조는 향후 새로운 GPU 아키텍처가 추가될 때 핵심 연산 로직을 수정하지 않고 설정 파일만 교체하면 되게 만든다. 또한, CUDA 전용 기능(동적 병렬성, 복소수 원자 연산 등)이 HIP에 아직 미지원되는 경우, CUDA 구현을 그대로 유지하면서 HIP에서도 동일한 인터페이스를 제공하도록 래퍼 함수를 작성하였다.
성능 평가에서는 동일한 소스 코드를 nvcc와 hipcc로 각각 컴파일한 뒤, V100(NVIDIA)과 Radeon VII(AMD)에서 100번 반복되는 로컬 reduction 커널을 실행하였다. 결과는 HIP 구현이 CUDA 네이티브 구현에 근접하거나 경우에 따라 약간 앞서는 수준을 보였으며, 특히 cooperative group을 사용한 버전이 legacy 구현과 거의 동일한 실행 시간을 기록했다. 이는 저자들의 sub‑warp 그룹 구현이 실제 하드웨어 warp 구조와 잘 맞물려 효율적으로 동작함을 의미한다. 또한, HIP 코드가 AMD GPU에서 CUDA 코드와 비교해 약 5‑10% 정도의 오버헤드가 발생했지만, 이는 컴파일러 최적화와 메모리 대역폭 차이에 기인한 것으로, 전체 라이브러리 수준에서는 미미한 영향을 미친다.
전반적으로 이 논문은 GPU 포팅 작업을 단순히 “코드 변환” 수준에 머무르지 않고, 하드웨어 차이와 소프트웨어 생태계 격차를 메우는 구체적인 구현 전략을 제시한다는 점에서 가치가 크다. 특히, 오픈소스 프로젝트가 다중 백엔드를 지원하면서도 유지보수 비용을 최소화하려는 경우, “common” 모듈과 백엔드‑별 설정 파일 구조는 좋은 템플릿이 될 수 있다. 또한, HIP 생태계가 아직 부족한 기능을 자체적으로 보완함으로써, AMD GPU가 HPC와 과학 컴퓨팅 분야에서 실질적인 대안으로 자리 잡는 데 기여한다.
댓글 및 학술 토론
Loading comments...
의견 남기기