단일 화자 Tacotron 기반 음성 변환, 적은 데이터로 고품질 구현
Taco‑VC는 단일 화자 Tacotron과 WaveNet을 결합하고, 음성 인식 네트워크에서 추출한 Phonetic Posterior‑Grams(PPG)를 입력으로 사용한다. 제한된 학습 데이터만으로도 새로운 화자에 빠르게 적응하며, 기존 다중 화자 모델 대비 자연스러움과 화자 유사도에서 경쟁력을 보인다.
저자: Roee Levy Leshem, Raja Giryes
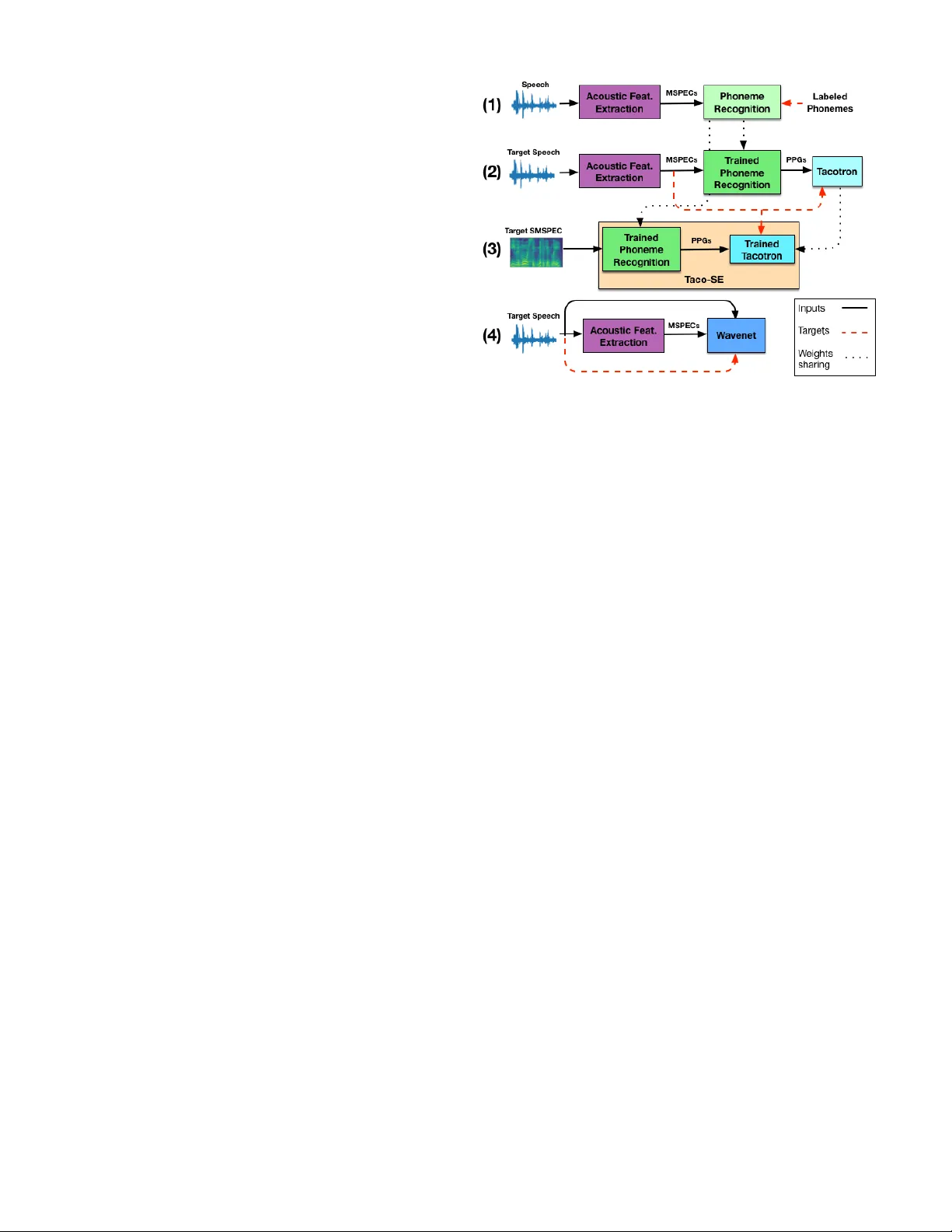
본 연구는 음성 변환(Voice Conversion, VC) 시스템을 설계하면서, 다중 화자 데이터와 복잡한 모델에 의존하는 기존 접근법의 한계를 극복하고자 한다. 저자는 Tacotron 기반의 시퀀스‑투‑시퀀스 모델과 WaveNet Vocoder를 결합한 Taco‑VC라는 새로운 아키텍처를 제안한다. 시스템은 크게 네 가지 모듈로 구성된다. 첫 번째는 Phoneme Recognition(PR) 네트워크로, Convolutional Neural Network(CNN) 구조에 Leaky‑ReLU와 배치 정규화를 적용해 16 kHz TIMIT 데이터를 22.05 kHz mel‑spectrogram으로 변환 후 CTC 손실을 이용해 Phonetic Posterior‑Grams(PPG)를 추출한다. PPG는 화자에 무관한 발음 정보를 담고 있어, 원본 음성의 운율과 억양을 그대로 전달한다. 두 번째 모듈은 단일 화자 Tacotron 합성기이다. 기존 Tacotron은 텍스트를 입력으로 사용하지만, 여기서는 PPG를 입력으로 사용해 목표 화자의 mel‑spectrogram을 직접 예측한다. 학습 과정에서 스케줄드 샘플링을 적용해 디코더가 실제 출력에 과도하게 의존하지 않도록 하였으며, 입력 길이가 출력 길이와 동일함을 이용해 stop‑token을 간단히 구현했다. 세 번째 모듈은 Speech Enhancement 네트워크(Taco‑SE)이다. Tacotron이 생성한 mel‑spectrogram은 중고주파 영역에서 과도하게 평탄화되는 문제가 있었는데, 이를 해결하기 위해 PR 네트워크와 Tacotron을 가중치 공유 형태로 연결한 뒤, 실제 mel‑spectrogram과 합성된 mel‑spectrogram을 각각 입력으로 사용해 동일한 손실 함수를 최소화하도록 학습한다. 이 과정은 고주파 조화성을 회복시키고, 원본 스펙트럼의 세부 정보를 보존한다. 네 번째 모듈은 WaveNet Vocoder이다. 80‑band mel‑spectrogram을 로컬 컨디션으로 사용하고, 업샘플링 레이어를 통해 시간 해상도를 원시 파형과 일치시켜 고품질의 음성을 복원한다. 전체 파이프라인은 각각 독립적으로 학습된 뒤, 새로운 목표 화자에 대해 전체 모델을 5 ~ 10 k 단계 정도 미세조정(fine‑tuning)함으로써 적은 양(≈5 분)의 데이터만으로도 효과적인 적응이 가능하다. 실험 설정은 다음과 같다. PR 네트워크는 TIMIT 전체 462명 화자를 사용해 학습했으며, Tacotron, Taco‑SE, WaveNet은 단일 여성 화자(LJ Speech, 24 시간) 데이터로 학습하였다. 평가에는 VCC2018 SPOKE 비병렬 변환 과제를 채택했으며, 각 목표 화자당 5 분 정도의 학습 데이터를 사용해 모델을 적응시켰다. 평가 항목은 자연스러움 MOS와 화자 유사도 MOS이며, Amazon Mechanical Turk를 통해 주관적 평가를 수행했다. 결과는 다음과 같다. 제안 모델(Taco‑VC)은 베이스라인 GMM 기반 시스템(B01)보다 자연스러움 점수가 크게 향상되었고, 최고 성능을 보인 다중 화자 DBLSTM 기반 시스템(N10)과도 비슷한 수준을 기록했다. 특히 Taco‑SE를 제외한 버전(Taco‑VC‑NoSe)은 자연스러움 MOS가 현저히 낮아, 스펙트럼 강화 단계가 최종 품질에 결정적인 영향을 미침을 확인했다. 화자 유사도 측면에서는 Taco‑VC가 약 60 %의 평가자가 목표 화자와 유사하다고 판단했으며, 베이스라인은 30 % 미만에 그쳤다. 전체적으로 단일 화자 데이터만으로도 다중 화자 변환 시스템에 필적하는 성능을 달성했으며, 모델 구조가 비교적 단순하고 학습·적응 비용이 낮다는 실용적 장점이 있다. 논문은 또한 PR 네트워크가 화자 독립적이므로 적응 단계에서 재학습이 필요 없다는 점을 강조한다. 마지막으로, 제한된 데이터 환경에서도 고품질 VC를 구현할 수 있는 새로운 패러다임을 제시함으로써, 향후 개인화된 TTS, 보조기기, 스피커 스푸핑 방지 등 다양한 응용 분야에 활용 가능성을 열었다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기