탐색적 지형 분석은 샘플링 전략에 크게 민감함
초록
**
본 논문은 탐색적 지형 분석(ELA)에서 특징값을 추정할 때 사용되는 샘플링 방법과 샘플 크기가 결과에 미치는 영향을 실험적으로 조사한다. 균등 무작위, 라틴 하이퍼큐브(LHS), 개선된 LHS(iLHS) 및 Sobol 저불일치 시퀀스 등 다섯 가지 전략을 비교했으며, 특징값은 절대적인 값이 아니라 샘플링 분포에 종속된다는 중요한 사실을 발견한다. 또한, 동일한 샘플링 방식으로 학습·테스트한 경우에만 분류 정확도가 크게 향상되며, Sobol 시퀀스로 만든 샘플이 가장 높은 정확도를 보였다.
**
상세 분석
**
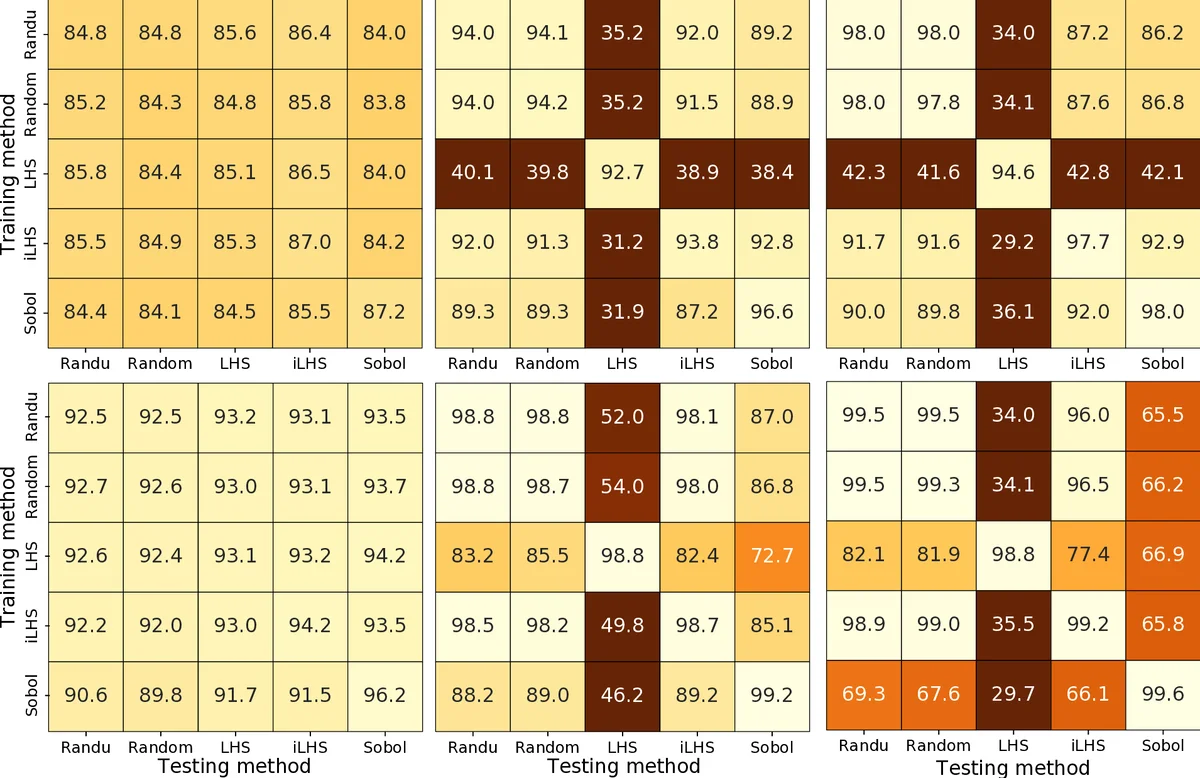
이 연구는 ELA가 자동 알고리즘 선택·구성에 핵심적인 역할을 한다는 전제 하에, 블랙박스 최적화 상황에서 제한된 평가 횟수로부터 특징값을 어떻게 추정할 것인가라는 실질적인 문제를 다룬다. 먼저 저자들은 BBOB 벤치마크의 24가지 함수를 5차원에서 100번씩 무작위로 샘플링해 46개의 ELA 특징을 추출하고, 이를 100개의 독립 반복을 통해 통계적 안정성을 확보하였다. 샘플 크기 n을 30, 300, 3125로 변동시키면서 특징값의 분산이 감소함을 확인했지만, 가장 중요한 발견은 서로 다른 샘플링 전략이 같은 함수에 대해 서로 다른 “진짜” 특징값을 만든다는 점이다. 이는 기존 문헌에서 “샘플 수가 무한대로 갈 때 특징값이 수렴한다”는 가정과 정면으로 충돌한다.
다섯 가지 샘플링 방법 중, 균등 무작위는 두 종류의 난수 생성기(Mersenne Twister와 RANDU)를 사용했으며, 두 생성기의 결과 차이는 미미했다. 이는 난수 생성기의 품질이 ELA 특징 추정에 큰 영향을 주지 않음을 시사한다. 라틴 하이퍼큐브(LHS)와 개선형 iLHS는 전통적으로 널리 쓰이지만, 실험 결과는 이들 전략이 Sobol 저불일치 시퀀스에 비해 분류 정확도가 낮다는 것을 보여준다. Sobol 시퀀스는 낮은 별 불일치(star discrepancy)를 갖는 quasi‑random 시퀀스로, 샘플이 공간을 고르게 채우면서도 통계적 편향을 최소화한다. 이러한 특성이 ELA 특징값을 보다 일관되게 만들고, 결국 지도학습 분류기의 성능을 끌어올린다.
분류 실험에서는 K‑Nearest Neighbors(K=5)와 결정 트리 두 가지 기본 모델을 사용했으며, 각 모델에 대해 동일한 샘플링 전략으로 학습·테스트를 진행했다. 결과는 샘플 크기가 커질수록 정확도가 상승했지만, 전략 간 차이가 뚜렷했다. 특히 Sobol 기반 샘플은 n=300에서도 0.92 이상의 정확도를 기록했으며, n=3125에서는 거의 0.97에 달했다. 반면 RANDU 기반 균등 샘플은 0.83 수준에 머물렀다. 이는 ELA 기반 머신러닝 모델을 실제 적용할 때, 학습 단계와 동일한 샘플링 방식을 유지해야 함을 강력히 시사한다.
또한, 저자들은 “특징값은 절대적인 메트릭이 아니라 샘플링 분포에 종속된다”는 결론을 도출함으로써, 기존 연구에서 특징값을 비교하거나 시각화할 때 샘플링 조건을 명시하지 않으면 오해가 발생할 수 있음을 경고한다. 향후 연구 방향으로는 저불일치 시퀀스 외에도 공간‑채우기 설계, 최소 분산 설계 등 다양한 quasi‑random 기법을 탐색하고, 이러한 샘플링이 다른 최적화 문제(예: 고차원, 제약조건 포함)에 어떻게 일반화되는지를 검증할 필요가 있다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기