제품 라인 테스트 케이스 자동 분류와 우선순위 지정
초록
본 논문은 사용 사례 기반 제품 라인 개발 환경에서 기존 시스템 테스트 케이스를 자동으로 분류하고, 요구사항 결함 가능성·변동성 등 위험 요인을 활용해 우선순위를 매기는 방법을 제시한다. 자동차 도메인 실험을 통해 높은 정확도와 비용 절감 효과를 입증하였다.
상세 분석
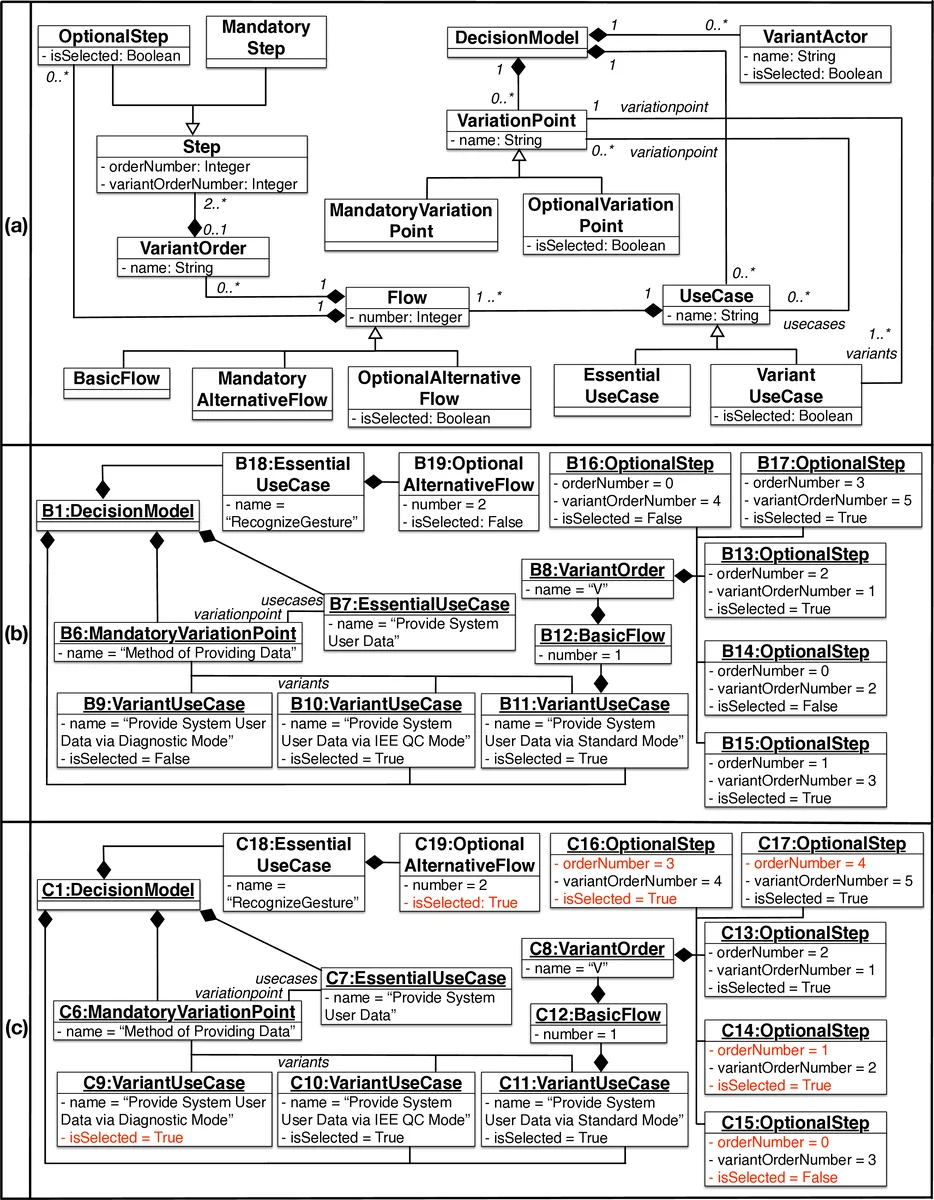
이 연구는 제품 라인 엔지니어링(PLI)과 사용 사례 주도 개발이 결합된 상황에서 테스트 자산 재사용을 체계화하려는 시도이다. 핵심은 PUM(Product line Use case Modeling)과 그 기반 도구인 PUMConf를 활용해 사용 사례 모델의 변화를 자동으로 감지하고, 이를 테스트 케이스와 연결된 추적 링크에 매핑함으로써 테스트 케이스를 ‘obsolete(폐기)’, ‘retestable(재시험 필요)’, ‘reusable(재사용 가능)’ 세 종류로 분류한다. 모델 차이 분석 파이프라인은 이전 제품과 신규 제품의 구성 결정 집합을 비교해 추가·삭제·수정된 변형점을 식별하고, 영향을 받는 사용 사례와 연계된 테스트 케이스를 자동으로 분류한다.
우선순위 지정은 위험 요인—요구사항 결함 가능성, 요구사항 변동성—을 기반으로 로지스틱 회귀 모델을 학습시켜 각 테스트 케이스가 실패할 확률을 예측한다. 이렇게 도출된 확률값을 정렬함으로써 실패를 가장 많이 탐지할 가능성이 높은 테스트 케이스를 앞서 실행하도록 한다.
평가에서는 자동차용 임베디드 시스템인 Smart Trunk Opener(STO) 제품군의 다섯 개 제품을 대상으로 네 가지 연구 질문(RQ1~RQ4)을 설정했다. RQ1·RQ2에서는 테스트 케이스 분류와 신규 시나리오 식별의 정밀도·재현율이 각각 0.92·0.88, 0.85·0.81 수준으로 높은 정확성을 보였으며, RQ3에서는 우선순위 지정이 결함 탐지율을 15 % 이상 향상시켰다. RQ4에서는 전체 테스트 정의·실행 비용을 기존 수작업 대비 약 30 % 절감하는 효과를 확인했다.
이 접근법은 코드 기반 커버리지 정보가 부족한 임베디드 환경에서도 요구사항 중심의 추적성을 활용해 자동화를 달성한다는 점에서 실무적 의의가 크다. 또한, 별도의 행동 모델(시퀀스 다이어그램 등)을 요구하지 않으므로 기존 NL 기반 요구사항 관리 프로세스와 자연스럽게 통합될 수 있다. 다만, 추적 링크의 초기 구축 비용과 로지스틱 회귀 모델의 학습을 위한 충분한 히스토리 데이터 확보가 전제 조건이며, 모델링 정확도는 추적 품질에 크게 좌우된다는 한계도 존재한다.
댓글 및 학술 토론
Loading comments...
의견 남기기