그래프에서 정확한 패턴 매칭의 복잡도 이진 문자열과 제한 차수
초록
이 논문은 라벨이 붙은 그래프에서 패턴 문자열을 정확히 찾는 문제(PMLG)의 시간 복잡도에 대해, 이진 알파벳과 최대 차수가 3인 무방향·유향 비순환 그래프에 대해 SETH(Strong Exponential Time Hypothesis)를 기반으로 한 조건부 하한을 제시한다. 즉, |E|·m 시간보다 약간이라도 빠른 알고리즘은 SETH가 거짓일 경우에만 존재한다는 결과를 증명한다.
상세 분석
본 연구는 문자열 매칭에서 선형 시간 알고리즘이 존재함에도 불구하고, 그래프 구조가 추가되면 동일한 정확 매칭 문제조차도 근본적으로 더 어려워진다는 점을 명확히 보여준다. 저자들은 먼저 PMLG(패턴 매칭 in 라벨드 그래프) 문제를 정의하고, 입력 그래프 G=(V,E,L)와 패턴 P를 각각 라벨 함수 L과 알파벳 Σ 위에 놓는다. 핵심은 “정확 매칭”이란 패턴이 그래프의 경로에 정확히 일치하도록 라벨을 연결하는 것이며, 경로는 노드를 중복 방문할 수 있다.
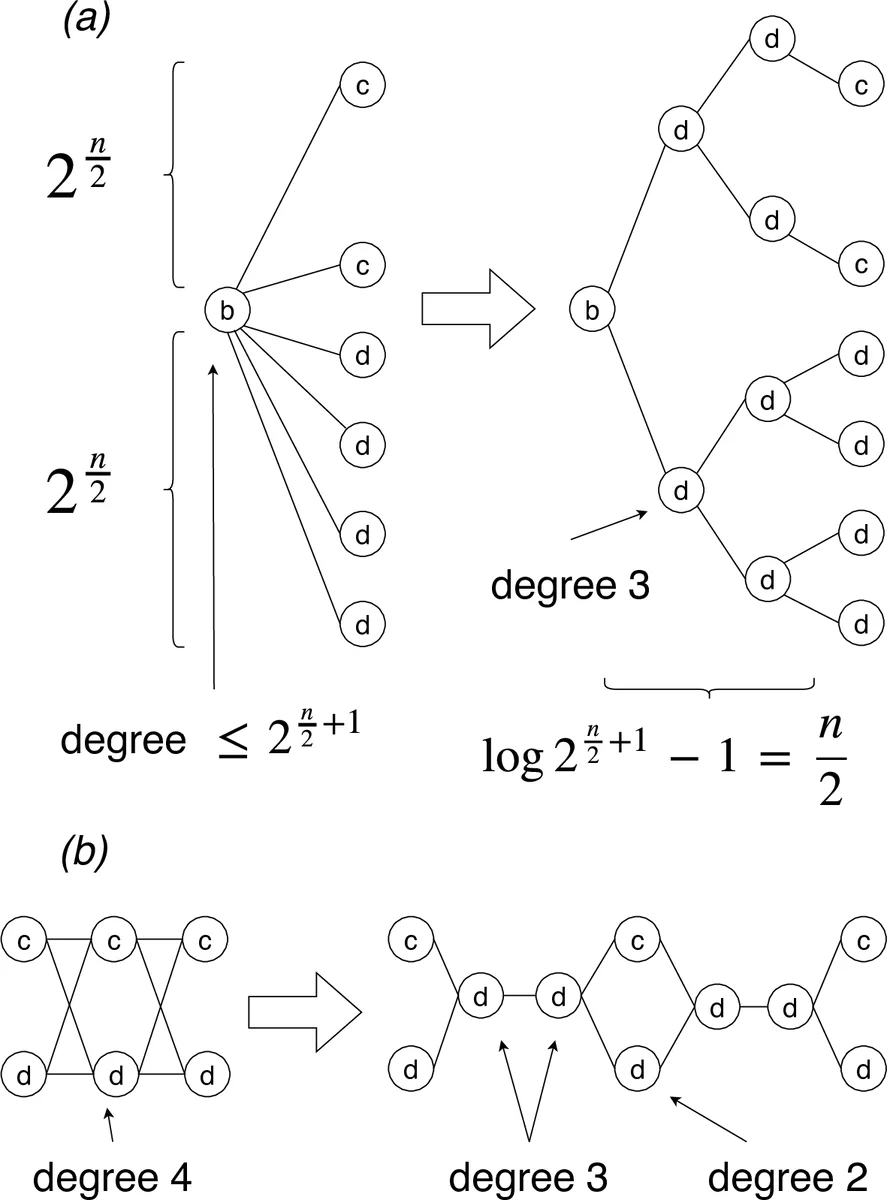
조건부 하한을 얻기 위해 저자들은 SAT(부울 만족도) 문제를 직접 PMLG로 감소시킨다. SAT 인스턴스는 n개의 변수와 k=poly(n)개의 절을 갖으며, 변수들을 절반씩 나누어 X와 Y라는 두 집합의 반할당을 만든다. 각 반할당은 2^{n/2}개의 조합을 가지며, 이를 그래프와 패턴의 구조에 매핑한다. 패턴 P는 네 개의 심볼(b, e, c, d)로 구성된 문자열이며, b와 e는 동기화 토큰, c는 아직 만족되지 않은 절을 표시, d는 이미 만족된 절을 나타낸다.
그래프 G는 “가젯”이라 불리는 서브그래프들의 집합으로 구성된다. 각 가젯은 특정 반할당 y∈Y와 절 c_i의 만족 관계를 나타내는 두 종류의 노드(c와 d)와, 시작·종료 노드(b, e)로 이루어진다. 라벨이 c인 노드는 패턴의 c와 매치될 때 해당 절이 y에 의해 만족됨을 의미하고, d 노드는 매치가 필요 없음을 나타낸다. 이렇게 구성된 그래프는 최대 차수가 3인 무방향 그래프이며, 라벨은 이진 알파벳 {0,1}로 변환될 수 있다(심볼 인코딩을 통해).
감소 과정에서 패턴 길이 m과 그래프의 에지 수 |E|는 모두 Θ(2^{n}) 수준이며, 전체 변환 비용은 ˜O(2^{n})이다. 만약 |E|·m보다 약간이라도 빠른 O(|E|^{1−ε}·m) 혹은 O(|E|·m^{1−ε}) 알고리즘이 존재한다면, 이를 이용해 SAT을 2^{(1−δ)n} 시간 안에 풀 수 있게 된다. 이는 SETH가 주장하는 “어떤 상수 δ>0에 대해서도 2^{(1−δ)n} 시간 알고리즘은 존재하지 않는다”는 가정에 직접 모순된다. 따라서 SETH가 참이라면 PMLG에 대한 서브쿼드라틱 알고리즘은 불가능하다.
또한 저자들은 기존의 Backurs‑Indyk 결과(문자열 편집 거리에 대한 SETH 하한)와 비교하여, 그래프 상에서 정확 매칭과 근사 매칭이 동일한 복잡도 장벽을 공유한다는 점을 강조한다. 근사 매칭은 O(|E|·m) 시간에 해결 가능하지만, 이 역시 SETH 하한에 의해 최적임이 증명된다.
결과적으로, 이 논문은 그래프 라벨링이 추가되면 문자열 매칭의 쉬운 선형 시간 해법이 사라지고, SETH 기반의 강력한 하한이 적용된다는 중요한 이론적 통찰을 제공한다. 이는 변이 그래프 기반 유전체 분석, 그래프 데이터베이스 질의, 이종 네트워크 마이닝 등 실용적인 분야에서 효율적인 인덱싱·검색 기법 개발에 제한을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기