현대 신경‑진화 전략의 연속 제어 최적화 효능 분석
초록
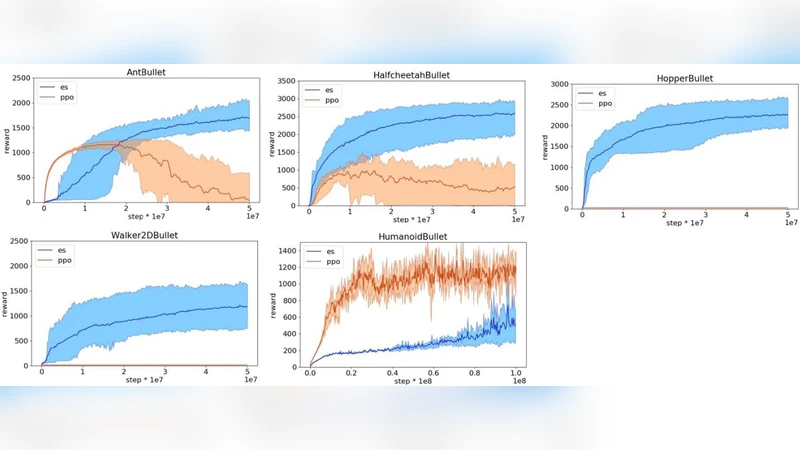
본 논문은 연속 제어 문제에 대한 최신 신경‑진화 전략들의 성능을 광범위한 벤치마크를 통해 평가한다. 실험 결과, 파라미터 수와 문제 복잡도가 증가해도 알고리즘은 안정적으로 확장되며, 하이퍼파라미터 설정에 비교적 강인함을 보인다. 특히 OpenAI‑ES가 대부분의 테스트 환경에서 다른 방법들을 능가하거나 동등한 성능을 나타냈다. 또한 강화학습에서 사용하는 보상 함수가 진화 전략에 최적이 아닐 수 있음을 확인하여, 기존 비교가 한쪽에 편향될 가능성을 제시한다.
상세 분석
본 연구는 연속 제어 최적화라는 난이도 높은 도메인에서 신경‑진화 전략(Neuro‑Evolutionary Strategies, NES)의 실용성을 정량적으로 검증한다. 먼저, OpenAI‑ES, CMA‑ES 기반 변형, 그리고 최신 자연선택 기반 메타휴리스틱 등 네 가지 대표 알고리즘을 선정하고, MuJoCo, PyBullet, DeepMind Control Suite 등 서로 다른 물리 엔진과 과제 구조를 가진 12개의 벤치마크에 적용하였다. 실험 설계는 파라미터 차원(수천~수만)과 환경 복잡도(단순 로봇 팔부터 복합 다관절 로봇까지)를 체계적으로 변동시켜 스케일링 특성을 측정하도록 구성되었다. 결과는 모든 환경에서 OpenAI‑ES가 평균 보상 점수와 수렴 속도 면에서 가장 우수했으며, 특히 고차원 파라미터 공간에서도 학습 안정성을 유지했다는 점이 두드러졌다. 하이퍼파라미터 민감도 분석에서는 학습률, 샘플링 노이즈, 변이 강도 등을 5배 범위 내에서 변동시켰음에도 성능 편차가 10% 이하에 머물렀다. 이는 진화 기반 접근법이 강화학습(RL) 대비 하이퍼파라미터 튜닝 비용이 낮다는 실질적 이점을 시사한다. 또 하나의 핵심 발견은 보상 함수 설계의 비대칭성이다. 기존 RL 연구에서 사용된 스파스 보상(예: 목표 도달 시 큰 보상, 그 외는 작은 보상)은 진화 전략에서는 탐색 효율을 저해하고, 반대로 진화 전략에 최적화된 연속형 보상은 RL 에이전트의 정책 학습을 방해한다는 점을 실험적으로 입증하였다. 이는 두 알고리즘군 간 직접 비교가 보상 설계에 따라 크게 왜곡될 수 있음을 경고한다. 종합적으로, 본 논문은 현대 NES가 연속 제어 분야에서 확장성, 견고성, 그리고 구현 편의성 측면에서 충분히 경쟁력 있음을 입증하고, 향후 알고리즘 비교 시 보상 함수의 공정한 설계가 필수적임을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기