제약된 제어로 다중안정성 전환: 딥 강화학습 기반 어트랙터 선택
본 논문은 비선형 다중안정 시스템에서 제약된 액추에이터를 이용해 원하는 어트랙터로 전환하는 방법을 제시한다. 교차 엔트로피 방법(CEM)과 딥 결정적 정책 그라디언트(DDPG) 두 가지 연속 제어 강화학습 알고리즘을 Duffing 진동기에 적용해 성공률, 학습 속도, 제어 부드러움 등을 비교한다. 결과적으로 두 기법 모두 높은 성공률을 보였으나, DDPG가 학습 효율과 제어 연속성 면에서 우수함을 확인하였다.
저자: Xue-She Wang, James D. Turner, Brian P. Mann
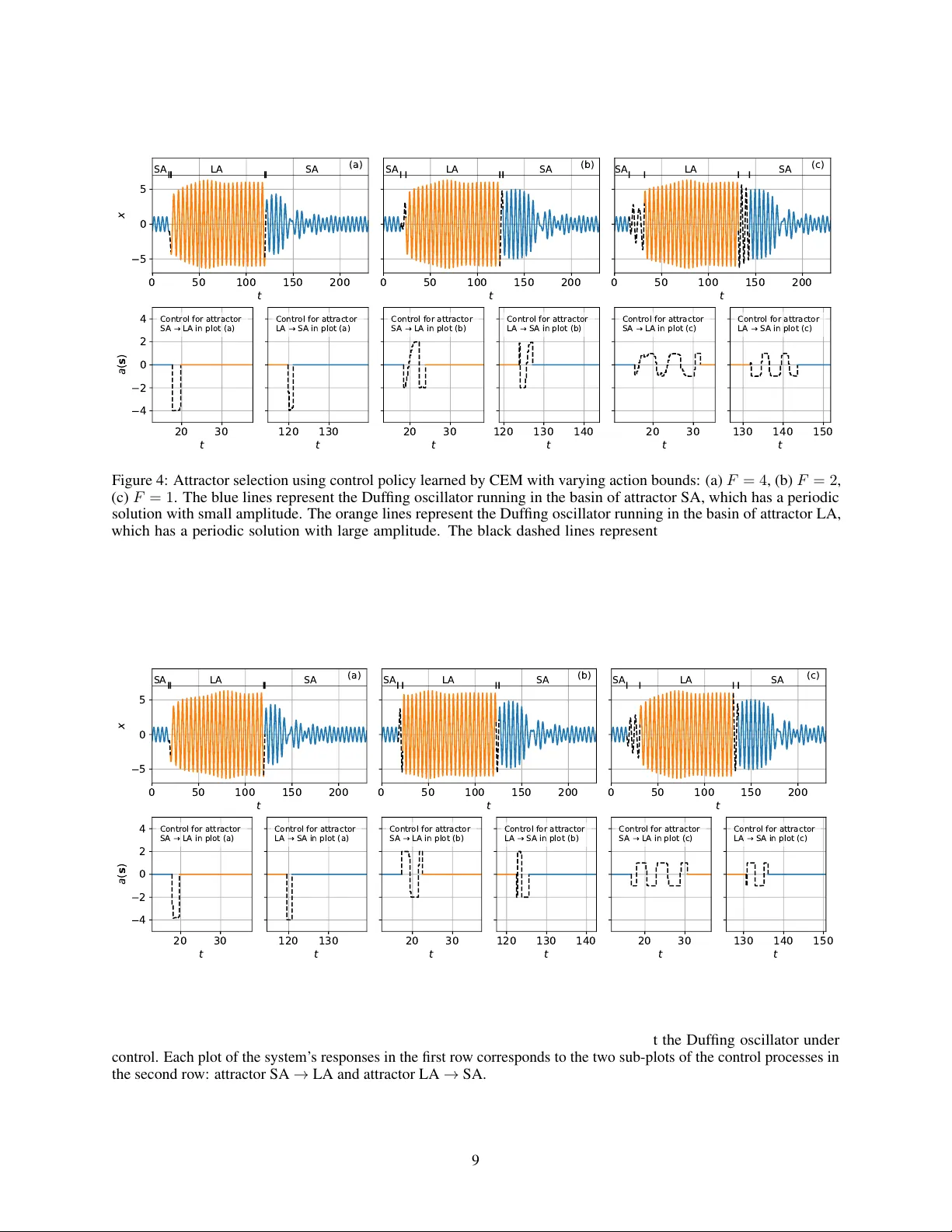
본 논문은 비선형 다중안정 시스템에서 특정 어트랙터를 선택하기 위한 제어 전략을 강화학습으로 구현한다. 기존의 펄스 제어, 타깃팅 알고리즘, OGY 방식 등은 혼돈 시스템 전용이거나 제어 제약을 다루기 어렵다는 한계가 있었다. 이를 극복하고자 저자들은 강화학습을 MDP 형태로 모델링하고, 제어 입력에 물리적 한계(최대 힘 \(F\))를 직접 적용한다. 시스템은 강성형 Duffing 진동기로, \(\ddot{x}+0.1\dot{x}+x+0.04x^{3}= \Gamma\cos(\omega t)+a(s)\) 로 기술된다. 상태는 위치, 속도, 위상 \(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기