비교를 활용한 선형 분류기 능동 학습
본 논문은 로그-볼록·s-볼록 등 약한 분포 가정 하에 비교 쿼리를 허용하면 선형 분류기의 능동 학습과 RPU 학습에서 기존 라벨 쿼리만 사용할 때보다 지수적인 샘플·쿼리 복잡도 감소가 가능함을 보인다. 또한 평균 추론 차원(Average Inference Dimension)을 도입해 비교 기반 학습의 이론적 한계를 정량화하고, 이를 통해 점 위치 문제의 비교 기반 선형 결정 트리 깊이 상한을 개선한다.
저자: Max Hopkins, Daniel M. Kane, Shachar Lovett
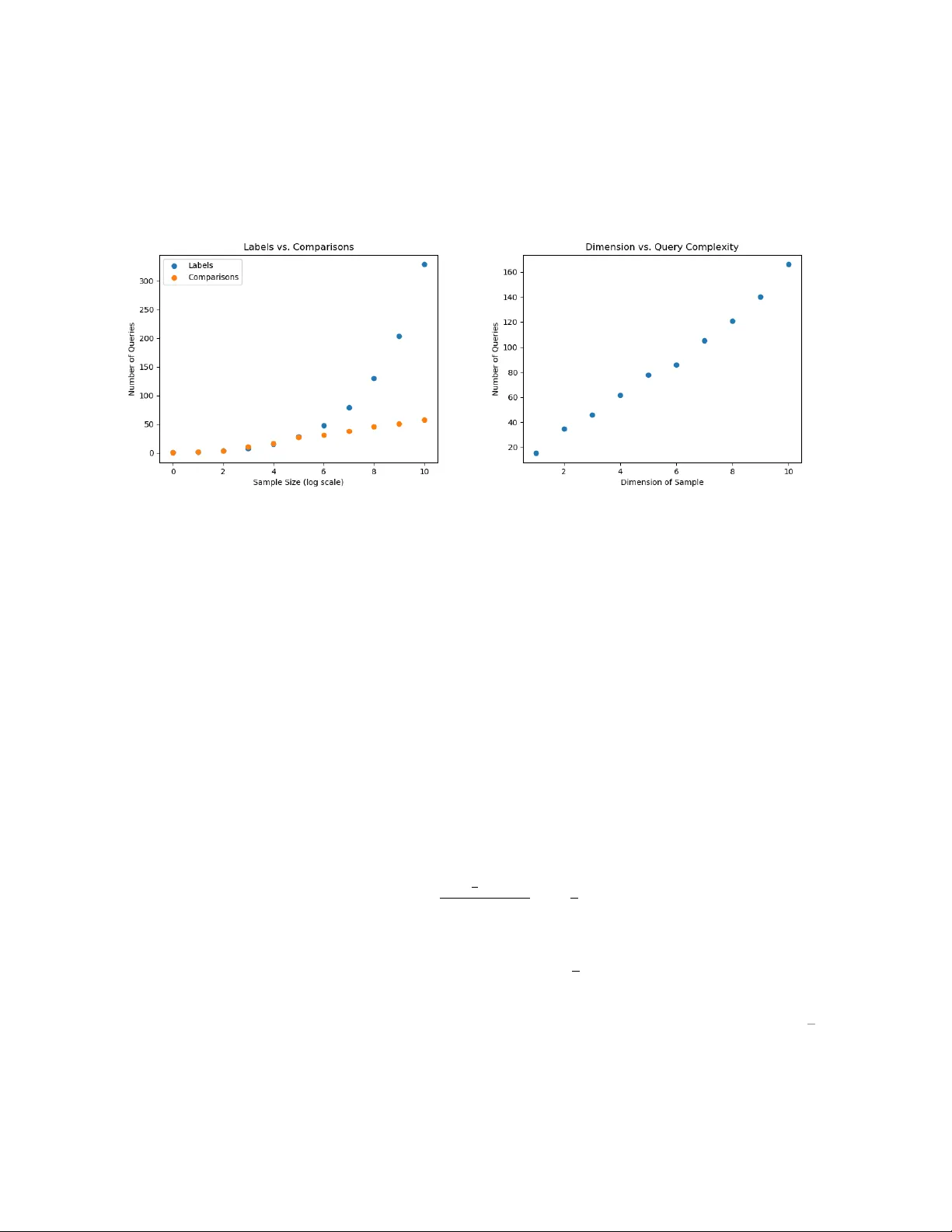
본 논문은 대규모 데이터가 존재하지만 라벨링 비용이 높은 상황을 전제로, 능동 학습(active learning)과 Reliable‑Probably‑Useful(RPU) 학습이라는 두 가지 학습 프레임워크에서 비교 쿼리(comparison query)의 효과를 심도 있게 탐구한다.
먼저 배경을 정리하면서, 전통적인 PAC‑learning은 라벨링 비용을 최소화하는 것이 목표이며, 능동 학습은 라벨링이 비싼 대신 비라벨 데이터는 저렴하다는 가정 하에 라벨 쿼리 수를 최소화한다. 그러나 기존 연구에서는 선형 분리자(linear separator)와 같은 핵심 클래스에 대해 능동 학습이 수동 학습과 비교해 비약적인 샘플 절감 효과를 보이지 못한다는 부정적 결과가 있었다.
이에 저자들은 두 가지 주요 아이디어를 도입한다. 첫 번째는 **분포 가정**을 약하게 완화한다는 점이다. 로그‑볼록(log‑concave) 혹은 s‑볼록(s‑concave) 분포는 집중(concentration)과 반집중(anti‑concentration) 특성을 갖으며, 가우시안이나 균등 분포를 일반화한다. 두 번째는 **비교 쿼리**를 허용한다는 점이다. 비교 쿼리는 두 점 x, x′에 대해 sign(h(x)−h(x′))를 반환하며, 라벨 쿼리보다 더 풍부한 정보를 제공한다. 실제로 추천 시스템이나 순위 학습 등에서 널리 활용되는 형태이다.
### 1. 능동 학습(PAC)에서의 하한과 상한
- **하한**: 라벨‑MQS(라벨 쿼리와 합성 쿼리)만을 사용할 경우, 차원 d와 오류 ε에 대해 쿼리 복잡도는 Ω(d·ε^{-(d−1)}) 로, 차원에 대한 지수적 의존성을 보인다(명제 1.2).
- **비교‑패시브**: 비교 쿼리만 사용해도 샘플 복잡도는 Ω(ε^{-1}) 로, 라벨만 사용할 때와 비슷한 수준이다(명제 1.3). 즉, 비교 쿼리만으로는 충분한 가속을 얻지 못한다.
- **상한**: 로그‑볼록 분포를 가정하고, 비교‑풀(pool) 모델에서 Balcan‑Long 알고리즘을 변형한 뒤 노이즈가 있는 임계값 추정 기법을 적용하면, 쿼리 복잡도는 ˜O((d+log 1/δ)·log 1/ε) 로 크게 감소한다(정리 1.4). 이는 차원에 대해 선형, 오류에 대해 로그 의존성을 갖는 거의 최적에 해당한다.
### 2. RPU 학습에서의 비교 쿼리 효용
RPU 모델은 오류를 전혀 허용하지 않으며, 대신 “모르겠다(⊥)” 라는 응답을 허용한다. 라벨만 사용할 경우, 차원 d에 대해 Θ(ε^{-(d+1)/2}) 라는 지수적 샘플 복잡도가 필요해 실용성이 떨어진다(명제 1.5).
저자들은 **평균 추론 차원(Average Inference Dimension, AID)** 라는 새로운 복잡도 개념을 도입한다. AID는 주어진 분포와 가설 클래스에 대해 평균적으로 몇 개의 비교 쿼리가 새로운 정보를 제공하는지를 측정한다. 로그‑볼록·s‑볼록 분포 하에서는 AID가 O(d·log n) 수준으로 제한됨을 증명한다. 이를 이용해, 라벨·비교 복합 쿼리만으로도 RPU 학습의 샘플·쿼리 복잡도를 PAC 수준과 동일하게 만들 수 있다. 즉, 비교 쿼리는 RPU 모델에서도 차원에 대한 지수적 의존성을 로그‑다항 수준으로 낮춘다.
### 3. 평균 추론 차원과 점 위치 문제
점 위치 문제는 n개의 하이퍼플레인으로 정의된 배열에서 임의의 점이 어느 셀에 속하는지를 결정하는 문제이다. 기존 결과는 임의의 선형 쿼리를 허용하면 ˜O(d·log n) 깊이의 선형 결정 트리를 구축할 수 있지만, 실제 시스템에서는 비교 형태의 제한된 쿼리만 사용할 수 있다.
논문은 평균 추론 차원 분석을 통해, 하이퍼플레인 집합이 약한 분포 가정을 만족하면 비교 기반 LDT의 기대 깊이가 ˜O(d·log² d·log² n) 로 개선될 수 있음을 보인다. 이는 기존의 Ω(n) 하한을 크게 완화한 것으로, 비교 쿼리를 활용한 실용적인 알고리즘 설계에 중요한 이론적 근거를 제공한다.
### 4. 기술적 기여 요약
1. 라벨‑MQS와 비교‑패시브만으로는 선형 분리자 학습에 실질적 가속을 기대할 수 없다는 하한을 명시.
2. 로그‑볼록·s‑볼록 분포 하에서 비교‑풀 모델을 이용해, 능동 PAC 학습의 쿼리 복잡도를 ˜O((d+log 1/δ)·log 1/ε) 로 크게 감소.
3. RPU 학습에서 라벨만 사용할 경우 차원에 대한 지수적 복잡도가 필요함을 확인하고, 비교 쿼리를 도입해 평균 추론 차원을 이용해 로그‑다항 복잡도로 개선.
4. 평균 추론 차원 개념을 도입해, 비교 기반 LDT가 점 위치 문제에서 기대 깊이를 크게 낮출 수 있음을 증명.
전반적으로 이 논문은 **비교 쿼리**라는 추가적인 정보원을 활용함으로써, 기존 능동 학습과 RPU 학습의 이론적 한계를 뛰어넘는 새로운 학습 알고리즘과 복잡도 분석을 제공한다. 이는 고차원 데이터와 제한된 라벨링 비용이 존재하는 실제 머신러닝 시스템에 직접적인 적용 가능성을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기