시맨틱 인코딩 기반 3계층 영상 분석 시스템 SiEVE
초록
SiEVE는 영상 인코더가 객체 탐지와 같은 다운스트림 작업을 인식하도록 설계된 ‘시맨틱 비디오 인코딩’ 기법을 도입하고, 카메라‑엣지‑클라우드 3계층 구조에서 I‑프레임만을 선택적으로 디코딩·분석함으로써 전체 프레임을 풀 디코딩할 필요 없이 3.5% 이하의 프레임만 처리해 100배 이상의 속도 향상과 7배 이상의 전송량 절감을 달성한다.
상세 분석
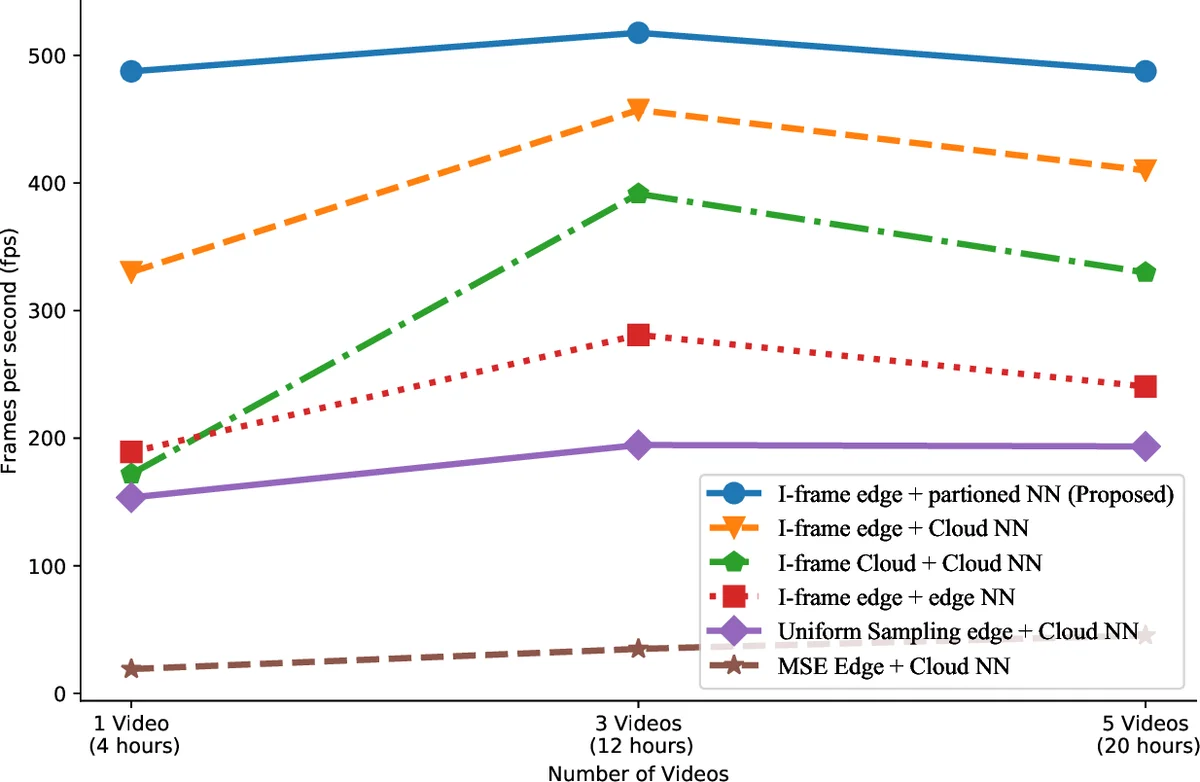
SiEVE의 핵심은 기존 비디오 코덱이 인간 시청자를 위해 설계된 점을 탈피해, 객체 라벨 변화라는 의미적 이벤트에만 반응하도록 파라미터를 튜닝한다는 점이다. 구체적으로 GOP 크기와 scenecut threshold를 조정해 움직임이 크게 달라지는 순간에만 I‑프레임을 삽입하고, 나머지 P‑프레임은 “변화 없음”으로 간주한다. 이때 I‑프레임 탐색은 실제 디코딩이 아니라 메타데이터 검색으로 이루어지므로, 비디오 스트림 전체를 복원하는 비용이 크게 감소한다. 엣지 서버는 I‑프레임을 받아 즉시 JPEG와 유사한 방식으로 디코딩하고, 사전 학습된 객체 탐지 NN의 일부 레이어를 실행한다. NN 레이어 배치는 엣지‑클라우드 간에 자유롭게 분할 가능하도록 설계돼, 지연 민감도에 따라 전부를 엣지에서, 혹은 일부를 클라우드에 오프로드할 수 있다.
시스템 설계 단계에서 저자들은 각 카메라마다 오프라인으로 라벨링된 히스토리 데이터를 이용해 최적의 GOP·scenecut 조합을 탐색한다. 이는 카메라 높이, 시야각, 객체 크기 등 물리적 차이에 따라 움직임 감도 차이가 존재함을 감안한 맞춤형 최적화이다. 실험에서는 2.16 백만 프레임(≈12 GB) 영상을 대상으로, I‑프레임 비율을 3.5% 이하로 낮추면서도 객체 탐지 정확도를 95‑99% 수준으로 유지했다. 기존 이미지‑유사도 기반 프레임 필터링(예: MSE, SIFT) 대비 10배 이상의 FPS 향상을 보였으며, 전송량은 원본 압축 영상 대비 7배 절감했다.
하지만 몇 가지 한계도 존재한다. 첫째, 인코더 파라미터를 실시간으로 조정할 수 있는 하드웨어가 필요하며, 현재는 오프라인 튜닝에 의존한다는 점에서 급격히 환경이 변하는 상황(예: 조명 변화, 급격한 객체 크기 변동)에는 재튜닝 비용이 발생한다. 둘째, 현재는 객체 탐지 하나의 태스크에만 초점을 맞추었으며, 행동 인식·트래킹 등 복합적인 비전 작업에 대한 확장성은 미흡하다. 셋째, “변화 없음”을 P‑프레임에 일괄 할당하는 방식은 미세한 움직임(예: 사람의 손짓)까지 놓칠 위험이 있다. 마지막으로, 실험에 사용된 데이터셋이 제한적이며, 다양한 네트워크 대역폭·지연 조건에서의 종단‑투‑종단 성능 평가는 추가 연구가 필요하다.
전반적으로 SiEVE는 비디오 코덱과 AI 분석 파이프라인을 긴밀히 결합함으로써, 엣지·클라우드 협업 환경에서 영상 분석 비용을 획기적으로 낮추는 방향성을 제시한다. 특히 “semantic video encoding”이라는 새로운 패러다임은 향후 멀티태스크, 멀티모달 스트리밍 시스템에 적용될 가능성을 열어준다.
댓글 및 학술 토론
Loading comments...
의견 남기기