컨볼루션·디컨볼루션 통합 FPGA 가속기 설계
초록
본 논문은 이미지 분할에 특화된 SegNet‑Basic을 대상으로, 컨볼루션과 디컨볼루션을 동일한 프로세스 엘리먼트 배열에서 공유하도록 설계된 확장 가능한 FPGA 가속기 구조를 제안한다. 루프 언롤링·틸링·인터체인지와 2×2 패치 기반 디컨볼루션 최적화를 결합해 부분합 저장을 최소화하고 메모리 대역폭 부담을 낮추었다. Xilinx ZC706 보드에 구현한 결과, 컨볼루션 151.5 GOPS, 디컨볼루션 94.3 GOPS를 달성했으며, 기존 구현 대비 자원 효율과 처리량에서 우수함을 보였다.
상세 분석
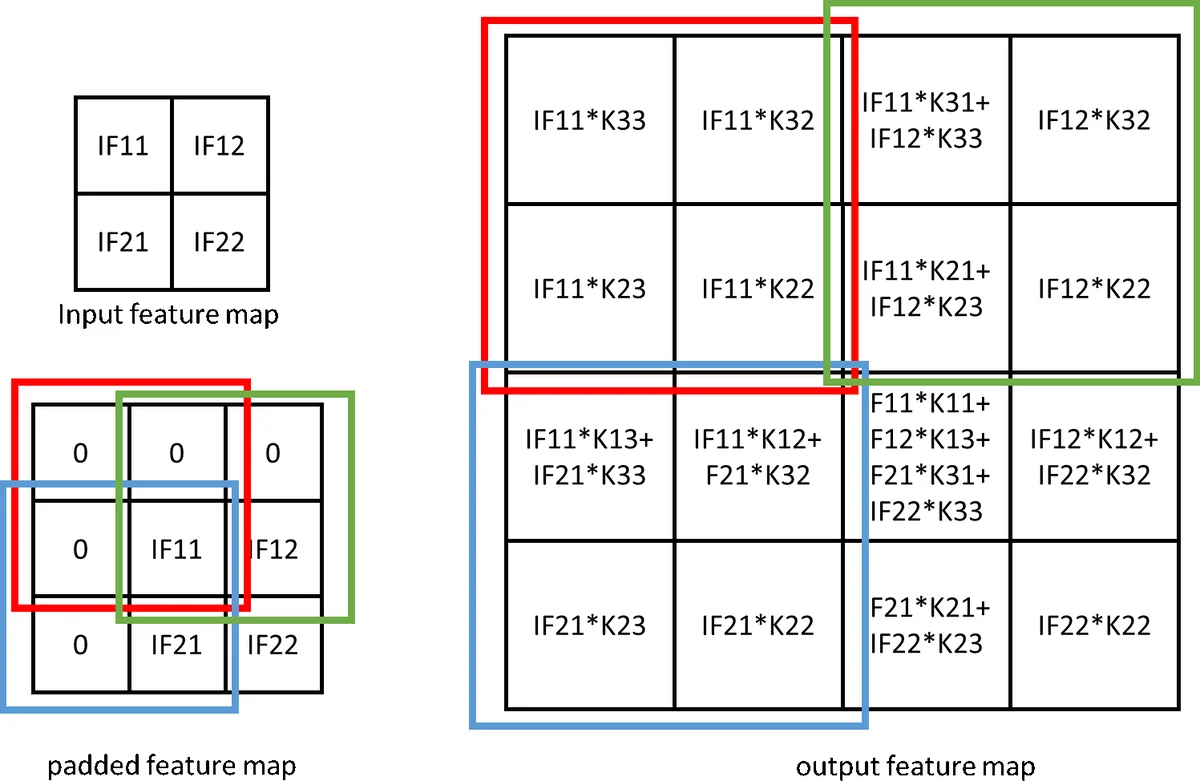
이 논문은 FPGA 기반 CNN 가속기의 설계에서 흔히 간과되는 디컨볼루션 연산을 컨볼루션과 동일한 하드웨어 자원으로 처리할 수 있는 새로운 프로세스 엘리먼트(PE) 구조를 제시한다. 기존 연구들은 디컨볼루션을 별도의 모듈로 구현하거나, 0값 곱셈을 피하기 위해 복잡한 데이터 재배열 및 임시 메모리 저장을 요구했지만, 본 설계는 2×2 슬라이딩 윈도우를 이용해 디컨볼루션을 9개의 곱셈과 5개의 덧셈으로 압축한다. 이는 PE 하나가 디컨볼루션 모드에서 4개의 출력 픽셀을 동시에 생성하도록 데이터 라우팅을 바꾸는 방식으로 구현된다.
루프 최적화 측면에서는 4중 루프 구조를 분석해, loop‑1(출력 채널) 전체 언롤링, loop‑2(입력 채널) 부분 언롤링, loop‑4(픽셀) 완전 언롤링을 선택하였다. 이는 부분합을 BRAM에 저장해 오프‑칩 메모리 접근을 최소화하고, 픽셀 재사용을 극대화한다. 또한, 라인 버퍼와 시프트 레지스터를 활용해 입력 피처맵을 3×1 벡터 형태로 스트리밍함으로써 BRAM 사용량을 크게 줄였다.
하드웨어 구조는 크게 라인 버퍼, 입력/출력 피처맵 버퍼, PE 배열, 풀링·배치 정규화·활성화 모듈, 그리고 FSM 기반 시스템 컨트롤러로 구성된다. 라인 버퍼는 AXI DMA와 연결돼 다양한 패딩 모드를 지원하며, 피처맵 크기에 따라 동적으로 FIFO 상태를 관리한다. PE는 9개의 곱셈기와 어더 트리를 포함하고, 컨볼루션 시 3×3 윈도우, 디컨볼루션 시 2×2 패치를 처리한다. 배치 정규화는 곱셈·덧셈 형태로 PE에 통합돼 별도 연산 단계를 없앴으며, ReLU·LeakyReLU를 선택적으로 적용할 수 있다.
실험에서는 SegNet‑Basic을 대상으로 설계했으며, 전체 파라미터는 42 MB, 8‑bit 고정소수점 양자화를 적용했다. ZC706 보드의 900 DSP와 19.2 MB BRAM을 활용해 220 MHz 클럭으로 동작했으며, 전체 LUT 16,579(8 %), 레지스터 25,390(6 %), BRAM 537(99 %), DSP 576(64 %)를 사용했다. 컨볼루션 성능은 151.5 GOPS, 디컨볼루션은 94.3 GOPS로, 기존 FPGA 기반 디컨볼루션 가속기 대비 2배 이상 높은 처리량을 기록했다. 다만 컨볼루션 전용 최적화 설계에 비해 약간 낮은 성능을 보였지만, 통합 설계의 자원 효율성과 설계 복잡도 감소 효과가 크게 부각된다.
확장성 측면에서는 PE 배열 수를 늘려 데이터 폭을 확대하면 성능을 선형적으로 향상시킬 수 있다. 현재는 PE 배열 1개(입출력 폭 64비트)로 구현했지만, 더 높은 대역폭을 지원하는 FPGA에서는 배열을 다중화해 수백 GOPS 수준까지 스케일링이 가능하다. 또한, 라인 버퍼와 FIFO 구조가 파라미터와 피처맵 크기에 따라 동적으로 조정되므로, 다양한 CNN 구조(예: U‑Net, FCN)에도 손쉽게 적용할 수 있다.
요약하면, 이 논문은 디컨볼루션을 별도 하드웨어 없이 기존 컨볼루션 PE에 매핑함으로써 메모리 대역폭과 자원 사용을 최소화하고, 루프 최적화와 데이터 흐름 설계를 통해 고성능·고효율 FPGA 가속기를 구현한 점이 가장 큰 공헌이다.
댓글 및 학술 토론
Loading comments...
의견 남기기